AWS Big Data Blog
Build and orchestrate ETL pipelines using Amazon Athena and AWS Step Functions
Extract, transform, and load (ETL) is the process of reading source data, applying transformation rules to this data, and loading it into the target structures. ETL is performed for various reasons. Sometimes ETL helps align source data to target data structures, whereas other times ETL is done to derive business value by cleansing, standardizing, combining, aggregating, and enriching datasets. You can perform ETL in multiple ways; the most popular choices being:
- Programmatic ETL using Apache Spark. Amazon EMR and AWS Glue both support this model.
- SQL ETL using Apache Hive or PrestoDB/Trino. Amazon EMR supports both these tools.
- Third-party ETL products.
Many organizations prefer the SQL ETL option because they already have developers who understand and write SQL queries. However, these developers want to focus on writing queries and not worry about setting up and managing the underlying infrastructure.
Amazon Athena is an interactive query service that makes it easy to analyze data in Amazon Simple Storage Service (Amazon S3) using standard SQL. Athena is serverless, so there is no infrastructure to manage, and you pay only for the queries that you run.
This post explores how you can use Athena to create ETL pipelines and how you can orchestrate these pipelines using AWS Step Functions.
Architecture overview
The following diagram illustrates our architecture.
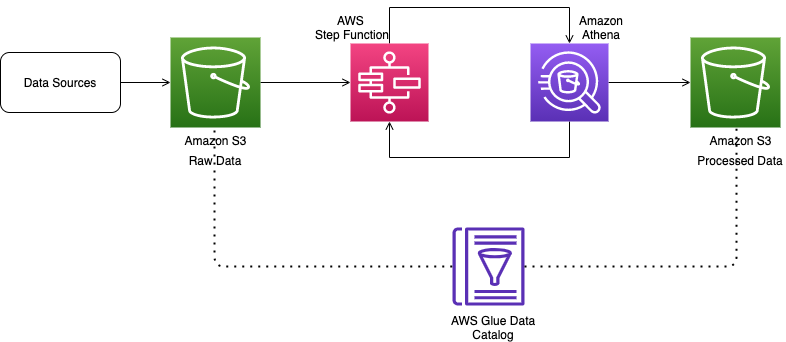
The source data first gets ingested into an S3 bucket, which preserves the data as is. You can ingest this data in Amazon S3 multiple ways:
- AWS Database Migration Service (AWS DMS) for batch and change data capture (CDC)
- Amazon Kinesis for streaming data
- AWS Transfer Family to ingest files in the raw bucket
After the source data is in Amazon S3 and assuming that it has a fixed structure, you can either run an AWS Glue crawler to automatically generate the schema or you can provide the DDL as part of your ETL pipeline. An AWS Glue crawler is the primary method used by most AWS Glue users. You can use a crawler to populate the AWS Glue Data Catalog with tables. A crawler can crawl multiple data stores in a single run. Upon completion, the crawler creates or updates one or more tables in your Data Catalog. Athena uses this catalog to run queries against the tables.
After the raw data is cataloged, the source-to-target transformation is done through a series of Athena Create Table as Select (CTAS) and INSERT INTO statements. The transformed data is loaded into another S3 bucket. The files are also partitioned and converted into Parquet format to optimize performance and cost.
Prepare your data
For this post, we use the NYC taxi public dataset. It has the data of trips taken by taxis and for-hire vehicles in New York City organized in CSV files by each month of the year starting from 2009. For our ETL pipeline, we use two files containing yellow taxi data: one for demonstrating the initial table creation and loading this table using CTAS, and the other for demonstrating the ongoing data inserts into this table using the INSERT INTO statement. We also use a lookup file to demonstrate join, transformation, and aggregation in this ETL pipeline.
- Create a new S3 bucket with a unique name in your account.
You use this bucket to copy the raw data from the NYC taxi public dataset and store the data processed by Athena ETL.
- Create the S3 prefixes
athena,nyctaxidata/data,nyctaxidata/lookup,nyctaxidata/optimized-data, andnyctaxidata/optimized-data-lookupinside this newly created bucket.
These prefixes are used in the Step Functions code provided later in this post.
- Copy the yellow taxi data files from the
nyc-tlcpublic bucket described in the NYC taxi public dataset registry for January and February 2020 into thenyctaxidata/dataprefix of the S3 bucket you created in your account. - Copy the lookup file into the
nyctaxidata/lookupprefix you created.
Create an ETL pipeline using Athena integration with Step Functions
Step Functions is a low-code visual workflow service used to orchestrate AWS services, automate business processes, and build serverless applications. Through its visual interface, you can create and run a series of checkpointed and event-driven workflows that maintain the application state. The output of one step acts as an input to the next. Each step in your application runs in order, as defined by your business logic.
The Step Functions service integration with Athena enables you to use Step Functions to start and stop query runs, and get query results.
For the ETL pipeline in this post, we keep the flow simple; however, you can build a complex flow using different features of Step Functions.
The flow of the pipeline is as follows:
- Create a database if it doesn’t already exist in the Data Catalog. Athena by default uses the Data Catalog as its metastore.
- If no tables exist in this database, take the following actions:
- Create the table for the raw yellow taxi data and the raw table for the lookup data.
- Use CTAS to create the target tables and use the raw tables created in the previous step as input in the SELECT statement. CTAS also partitions the target table by year and month, and creates optimized Parquet files in the target S3 bucket.
- Use a view to demonstrate the join and aggression parts of ETL.
- If any table exists in this database, iterate though the list of all the remaining CSV files and process by using the INSERT INTO statement.
Different use cases may make the ETL pipeline quite complex. You may be getting continuous data from the source either with AWS DMS in batch or CDC mode or by Kinesis in streaming mode. This requires mechanisms in place to process all such files during a particular window and mark it as complete so that the next time the pipeline is run, it processes only the newly arrived files. Instead of manually adding DDL in the pipeline, you can add AWS Glue crawler steps in the Step Functions pipeline to create a schema for the raw data; and instead of a view to aggregate data, you may have to create a separate table to keep the results ready for consumption. Also, many use cases get change data as part of the feed, which needs to be merged with the target datasets. Extra steps in the Step Functions pipeline are required to process such data on a case-by-case basis.
The following code for the Step Functions pipeline covers the preceding flow we described. For more details on how to get started with Step Functions, refer the tutorials. Replace the S3 bucket names with the unique bucket name you created in your account.
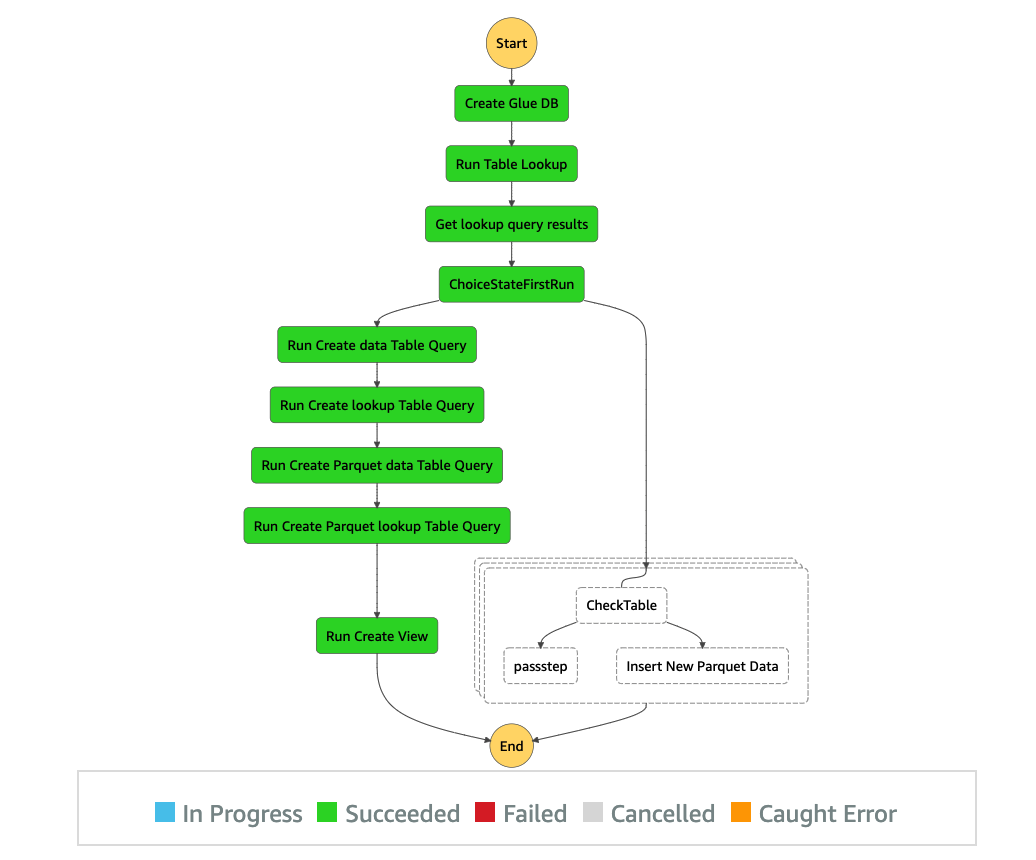
The first time we run this pipeline, it follows the CTAS path and creates the aggregation view.
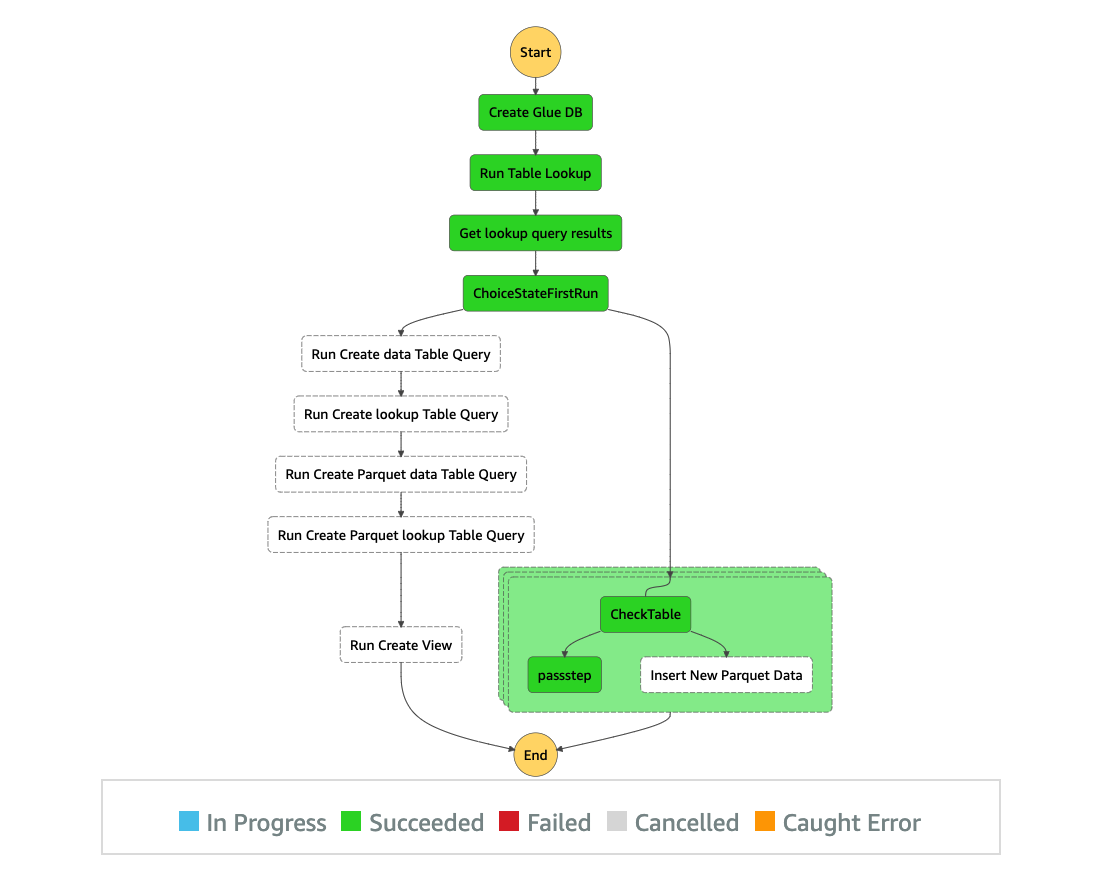
The second time we run it, it follows the INSERT INTO statement path to add new data into the existing tables.
When to use this pattern
You should use this pattern when the raw data is structured and the metadata can easily be added to the catalog.
Because Athena charges are calculated by the amount of data scanned, this pattern is best suitable for datasets that aren’t very large and need continuous processing.
The pattern is best suitable to convert raw data into columnar formats like Parquet or ORC, and aggregate a large number of small files into larger files or partition and bucket your datasets.
Conclusion
In this post, we showed how to use Step Functions to orchestrate an ETL pipeline in Athena using CTAS and INSERT INTO statements.
As next steps to enhance this pipeline, consider the following:
- Create an ingestion pipeline that continuously puts data in the raw S3 bucket at regular intervals
- Add an AWS Glue crawler step in the pipeline to automatically create the raw schema
- Add extra steps to identify change data and merge this data with the target
- Add error handling and notification mechanisms in the pipeline
- Schedule the pipeline using Amazon EventBridge to run at regular intervals
About the Authors
 Behram Irani, Sr Analytics Solutions Architect
Behram Irani, Sr Analytics Solutions Architect
 Dipankar Kushari, Sr Analytics Solutions Architect
Dipankar Kushari, Sr Analytics Solutions Architect
 Rahul Sonawane, Principal Analytics Solutions Architect
Rahul Sonawane, Principal Analytics Solutions Architect