AWS Big Data Blog
Build incremental crawls of data lakes with existing Glue catalog tables
AWS Glue includes crawlers, a capability that make discovering datasets simpler by scanning data in Amazon Simple Storage Service (Amazon S3) and relational databases, extracting their schema, and automatically populating the AWS Glue Data Catalog, which keeps the metadata current. This reduces the time to insight by making newly ingested data quickly available for analysis with your preferred analytics and machine learning (ML) tools.
Previously, you could reduce crawler cost by using Amazon S3 Event Notifications to incrementally crawl changes on Data Catalog tables created by crawler. Today, we’re extending this support to crawling and updating Data Catalog tables that are created by non-crawler methods, such as using data pipelines. This crawler feature can be useful for several use cases, such as following:
- You currently have a data pipeline to create AWS Glue Data Catalog tables and want to offload detection of partition information from the data pipeline to a scheduled crawler
- You have an S3 bucket with event notifications enabled and want to continuously catalog new changes and prevent creation of new tables in case of ill-formatted files that break the partition detection
- You have manually created Data Catalog tables and want to run incremental crawls on new file additions instead of running full crawls due to long crawl times
To accomplish incremental crawling, you can configure Amazon S3 Event Notifications to be sent to an Amazon Simple Queue Service (Amazon SQS) queue. You can then use the SQS queue as a source to identify changes and can schedule or run an AWS Glue crawler with Data Catalog tables as a target. With each run of the crawler, the SQS queue is inspected for new events. If no new events are found, the crawler stops. If events are found in the queue, the crawler inspects their respective folders, processes through built-in classifiers (for CSV, JSON, AVRO, XML, and so on), and determines the changes. The crawler then updates the Data Catalog with new information, such as newly added or deleted partitions or columns. This feature reduces the cost and time to crawl large and frequently changing Amazon S3 data.
This post shows how to create an AWS Glue crawler that supports Amazon S3 event notification on existing Data Catalog tables using the new crawler UI and an AWS CloudFormation template.
Overview of solution
To demonstrate how the new AWS Glue crawler performs incremental updates, we use the Toronto parking tickets dataset—specifically data about parking tickets issued in the city of Toronto between 2019–2020. The goal is to create a manual dataset as well as its associated metadata tables in AWS Glue, followed by an event-based crawler that detects and implements changes to the manually created datasets and catalogs.
As mentioned before, instead of crawling all the subfolders on Amazon S3, we use an Amazon S3 event-based approach. This helps improve the crawl time by using Amazon S3 events to identify the changes between two crawls by listing all the files from the subfolder that triggered the event instead of listing the full Amazon S3 target. To accomplish this, we create an S3 bucket, an event-based crawler, an Amazon Simple Storage Service (Amazon SNS) topic, and an SQS queue. The following diagram illustrates our solution architecture.
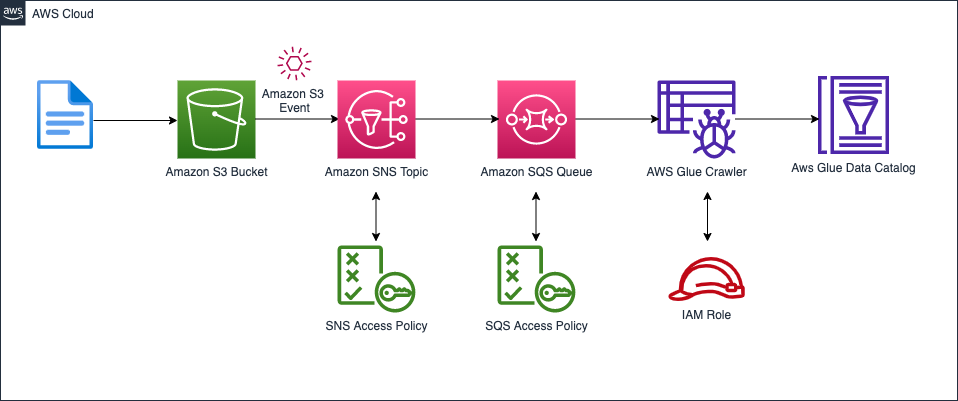
Prerequisites
For this walkthrough, you should have the following prerequisites:
- An AWS account
- An AWS Identity and Access Management (IAM) user with access to the following services:
- AWS CloudFormation
- AWS Glue
- Amazon SNS
- Amazon SQS
- Amazon S3
If the AWS account you use to follow this post uses Lake Formation to manage permissions on the AWS Glue Data Catalog, make sure that you log in as a user with access to create databases and tables. For more information, refer to Implicit Lake Formation permissions.
Launch your CloudFormation stack
To create your resources for this use case, complete the following steps:
- Launch your CloudFormation stack in
us-east-1:

- For Stack name, enter a name for your stack .
- For paramBucketName, enter a name for your S3 bucket (with your account number).
- Choose Next.

- Select I acknowledge that AWS CloudFormation might create IAM resources with custom names.
- Choose Create stack.
Wait for the stack formation to finish provisioning the requisite resources. When you see the CREATE_COMPLETE status, you can proceed to the next steps.
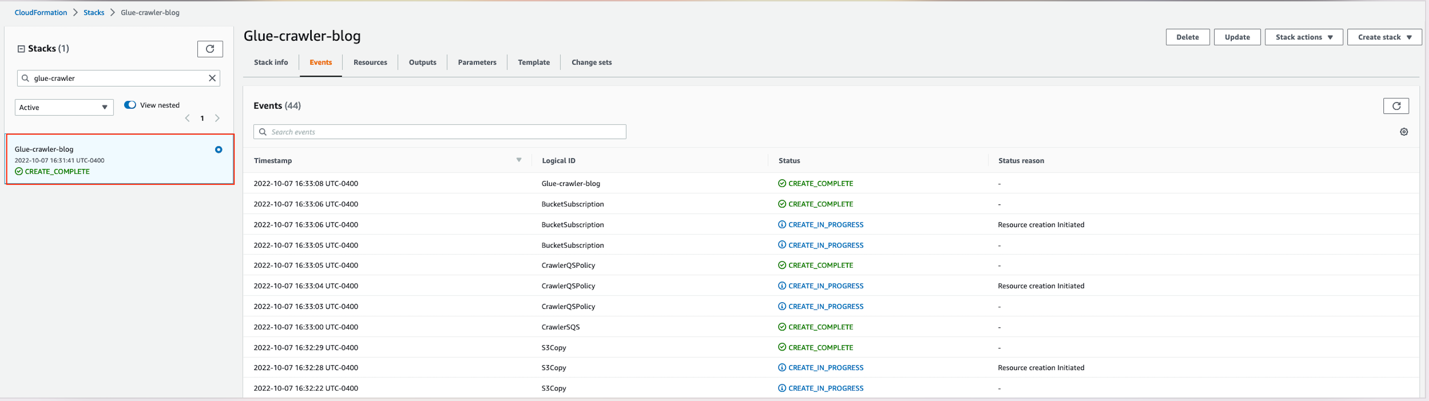
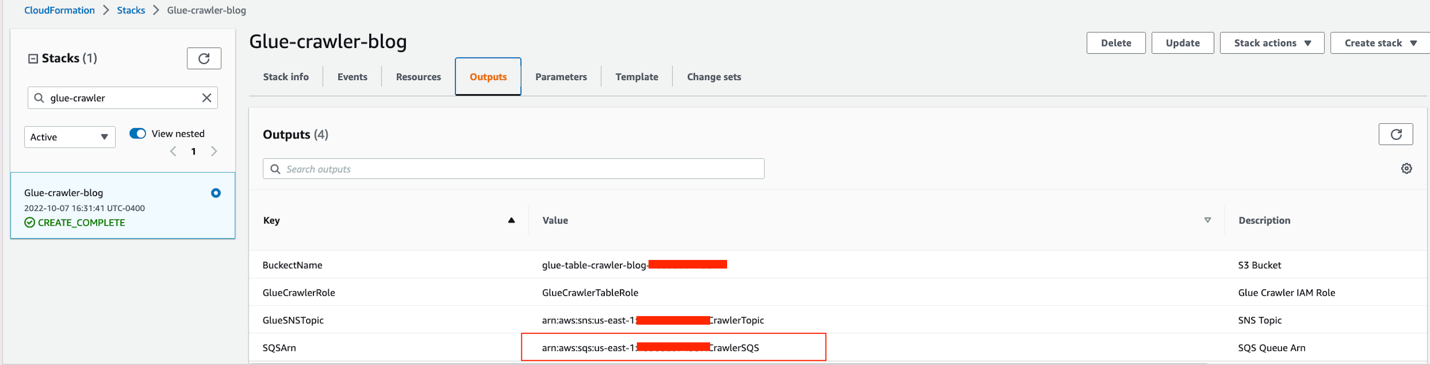
Additionally, note down the ARN of the SQS queue to use at a later point.
Query your Data Catalog
Next, we use Amazon Athena to confirm that the manual tables have been created in the Data Catalog, as part of the CloudFormation template.
- On the Athena console, choose Launch query editor.

- For Data source, choose
AwsDataCatalog.

- For Database, choose
torontoparking.

Theticketstable should appear in the Tables section.

Now you can query the table to see its contents. - You can write your own query, or choose Preview Table on the options menu.
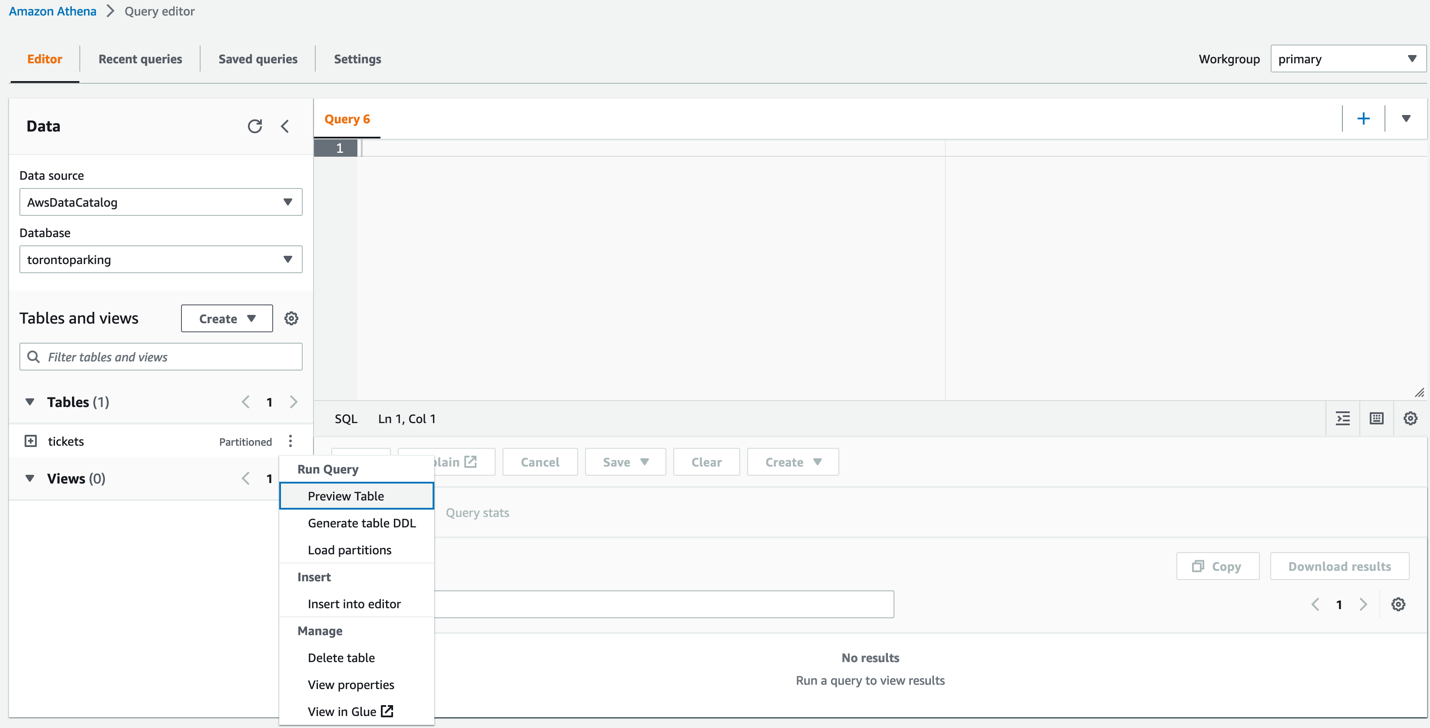
This writes a simple SQL query to show us the first 10 rows. - Choose Run to run the query.


As we can see in the query results, the database and table for 2019 parking ticket data have been created and partitioned.
Create the Amazon S3 event crawler
The next step is to create the crawler that detects and crawls only on incrementally updated tables.
- On the AWS Glue console, choose Crawlers in the navigation pane.
- Choose Create crawler.

- For Name, enter a name.
- Choose Next.

Now we need to select the data source for the crawler. - Select Yes to indicate that our data is already mapped to our AWS Glue Data Catalog.
- Choose Add tables.

- For Database, choose
torontoparkingand for Tables, choose tickets.

- Select Crawl based on events.

- For Include SQS ARN, enter the ARN you saved from the CloudFormation stack outputs.
- Choose Confirm.

You should now see the table populated under Glue tables, with the parameter set as Recrawl by event. - Choose Next.

- For Existing IAM role, choose the IAM role created by the CloudFormation template (
GlueCrawlerTableRole). - Choose Next.

- For Frequency, choose On demand.

You also have the option of choosing a schedule on which the crawler will run regularly. - Choose Next.
- Review the configurations and choose Create crawler.

Now that the crawler has been created, we add the 2020 ticketing data to our S3 bucket so that we can test our new crawler. For this step, we use the AWS Command Line Interface (AWS CLI) - To add this data, use the following command:
After successful completion of this command, your S3 bucket should contain the 2020 ticketing data and your crawler is ready to run. The terminal should return the following:
Run the crawler and verify the updates
Now that the new folder has been created, we run the crawler to detect the changes in the table and partitions.
- Navigate to your crawler on the AWS Glue console and choose Run crawler.

After running the crawler, you should see that it added the 2020 data to the tickets table.

- On the Athena console, we can ensure that the Data Catalog has been updated by adding a where
year = 2020filter to the query.

AWS CLI option
You can also create the crawler using the AWS CLI. For more information, refer to create-crawler.
Clean up
To avoid incurring future charges, and to clean up unused roles and policies, delete the resources you created: the CloudFormation stack, S3 bucket, AWS Glue crawler, AWS Glue database, and AWS Glue table.
Conclusion
You can use AWS Glue crawlers to discover datasets, extract schema information, and populate the AWS Glue Data Catalog. In this post, we provided a CloudFormation template to set up AWS Glue crawlers to use Amazon S3 event notifications on existing Data Catalog tables, which reduces the time and cost needed to incrementally process table data updates in the Data Catalog.
With this feature, incremental crawling can now be offloaded from data pipelines to the scheduled AWS Glue crawler, reducing cost. This alleviates the need for full crawls, thereby reducing crawl times and Data Processing Units (DPUs) required to run the crawler. This is especially useful for customers that have S3 buckets with event notifications enabled and want to continuously catalog new changes.
To learn more about this feature, refer to Accelerating crawls using Amazon S3 event notifications.
Special thanks to everyone who contributed to this crawler feature launch: Theo Xu, Jessica Cheng, Arvin Mohanty, and Joseph Barlan.
About the authors
 Leonardo Gómez is a Senior Analytics Specialist Solutions Architect at AWS. Based in Toronto, Canada, he has over a decade of experience in data management, helping customers around the globe address their business and technical needs.
Leonardo Gómez is a Senior Analytics Specialist Solutions Architect at AWS. Based in Toronto, Canada, he has over a decade of experience in data management, helping customers around the globe address their business and technical needs.
 Aayzed Tanweer is a Solutions Architect working with startup customers in the FinTech space, with a special focus on analytics services. Originally hailing from Toronto, he recently moved to New York City, where he enjoys eating his way through the city and exploring its many peculiar nooks and crannies.
Aayzed Tanweer is a Solutions Architect working with startup customers in the FinTech space, with a special focus on analytics services. Originally hailing from Toronto, he recently moved to New York City, where he enjoys eating his way through the city and exploring its many peculiar nooks and crannies.
 Sandeep Adwankar is a Senior Technical Product Manager at AWS. Based in the California Bay Area, he works with customers around the globe to translate business and technical requirements into products that enable customers to improve how they manage, secure, and access data.
Sandeep Adwankar is a Senior Technical Product Manager at AWS. Based in the California Bay Area, he works with customers around the globe to translate business and technical requirements into products that enable customers to improve how they manage, secure, and access data.