AWS Big Data Blog
ETL orchestration using the Amazon Redshift Data API and AWS Step Functions with AWS SDK integration
Extract, transform, and load (ETL) serverless orchestration architecture applications are becoming popular with many customers. These applications offers greater extensibility and simplicity, making it easier to maintain and simplify ETL pipelines. A primary benefit of this architecture is that we simplify an existing ETL pipeline with AWS Step Functions and directly call the Amazon Redshift Data API from the state machine. As a result, the complexity for the ETL pipeline is reduced.
As a data engineer or an application developer, you may want to interact with Amazon Redshift to load or query data with a simple API endpoint without having to manage persistent connections. The Amazon Redshift Data API allows you to interact with Amazon Redshift without having to configure JDBC or ODBC connections. This feature allows you to orchestrate serverless data processing workflows, design event-driven web applications, and run an ETL pipeline asynchronously to ingest and process data in Amazon Redshift, with the use of Step Functions to orchestrate the entire ETL or ELT workflow.
This post explains how to use Step Functions and the Amazon Redshift Data API to orchestrate the different steps in your ETL or ELT workflow and process data into an Amazon Redshift data warehouse.
AWS Lambda is typically used with Step Functions due to its flexible and scalable compute benefits. An ETL workflow has multiple steps, and the complexity may vary within each step. However, there is an alternative approach with AWS SDK service integrations, a feature of Step Functions. These integrations allow you to call over 200 AWS services’ API actions directly from your state machine. This approach is optimal for steps with relatively low complexity compared to using Lambda because you no longer have to maintain and test function code. Lambda functions have a maximum timeout of 15 minutes; if you need to wait for longer-running processes, Step Functions standard workflows allows a maximum runtime of 1 year.
You can replace steps that include a single process with a direct integration between Step Functions and AWS SDK service integrations without using Lambda. For example, if a step is only used to call a Lambda function that runs a SQL statement in Amazon Redshift, you may remove the Lambda function with a direct integration to the Amazon Redshift Data API’s SDK API action. You can also decouple Lambda functions with multiple actions into multiple steps. An implementation of this is available later in this post.
We created an example use case in the GitHub repo ETL Orchestration using Amazon Redshift Data API and AWS Step Functions that provides an AWS CloudFormation template for setup, SQL scripts, and a state machine definition. The state machine directly reads SQL scripts stored in your Amazon Simple Storage Service (Amazon S3) bucket, runs them in your Amazon Redshift cluster, and performs an ETL workflow. We don’t use Lambda in this use case.
Solution overview
In this scenario, we simplify an existing ETL pipeline that uses Lambda to call the Data API. AWS SDK service integrations with Step Functions allow you to directly call the Data API from the state machine, reducing the complexity in running the ETL pipeline.
The entire workflow performs the following steps:
- Set up the required database objects and generate a set of sample data to be processed.
- Run two dimension jobs that perform SCD1 and SCD2 dimension load, respectively.
- When both jobs have run successfully, the load job for the fact table runs.
- The state machine performs a validation to ensure the sales data was loaded successfully.

The following architecture diagram highlights the end-to-end solution:
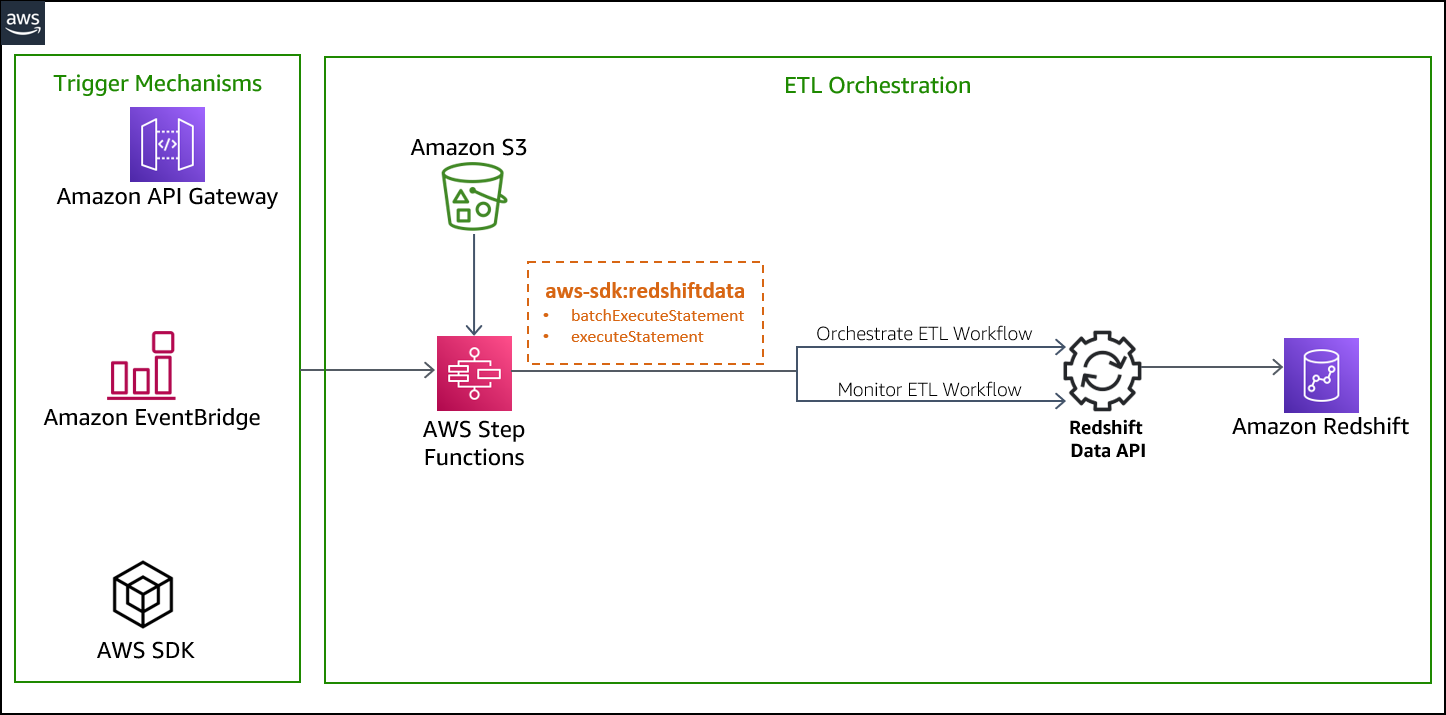
We run the state machine via the Step Functions console, but you can run this solution in several ways:
- Call the StartExecution API action
- Use Amazon CloudWatch Events to trigger the state machine
- Use Amazon API Gateway to trigger the state machine
- Start a nested workflow run from a task state
You can deploy the solution with the provided CloudFormation template, which creates the following resources:
- Database objects in the Amazon Redshift cluster:
- Four stored procedures:
- sp_setup_sales_data_pipeline() – Creates the tables and populates them with sample data
- sp_load_dim_customer_address() – Runs the SCD1 process on
customer_addressrecords - sp_load_dim_item() – Runs the SCD2 process on
itemrecords - sp_load_fact_sales (p_run_date date) – Processes sales from all stores for a given day
- Five Amazon Redshift tables:
customercustomer_addressdate_dimitemstore_sales
- Four stored procedures:
- The AWS Identity and Access Management (IAM) role
StateMachineExecutionRolefor Step Functions to allow the following permissions:- Federate to the Amazon Redshift cluster through
getClusterCredentialspermission avoiding password credentials - Run queries in the Amazon Redshift cluster through Data API calls
- List and retrieve objects from Amazon S3
- Federate to the Amazon Redshift cluster through
- The Step Functions state machine
RedshiftETLStepFunction, which contains the steps used to run the ETL workflow of the sample sales data pipeline
Prerequisites
As a prerequisite for deploying the solution, you need to set up an Amazon Redshift cluster and associate it with an IAM role. For more information, see Authorizing Amazon Redshift to access other AWS services on your behalf. If you don’t have a cluster provisioned in your AWS account, refer to Getting started with Amazon Redshift for instructions to set it up.
When the Amazon Redshift cluster is available, perform the following steps:
- Download and save the CloudFormation template to a local folder on your computer.
- Download and save the following SQL scripts to a local folder on your computer:
- sp_statements.sql – Contains the stored procedures including DDL and DML operations.
- validate_sql_statement.sql – Contains two validation queries you can run.
- Upload the SQL scripts to your S3 bucket. The bucket name is the designated S3 bucket specified in the
ETLScriptS3Pathinput parameter. - On the AWS CloudFormation console, choose Create stack with new resources and upload the template file you downloaded in the previous step (
etl-orchestration-with-stepfunctions-and-redshift-data-api.yaml). - Enter the required parameters and choose Next.

- Choose Next until you get to the Review page and select the acknowledgement check box.
- Choose Create stack.

- Wait until the stack deploys successfully.
When the stack is complete, you can view the outputs, as shown in the following screenshot:

Run the ETL orchestration
After you deploy the CloudFormation template, navigate to the stack detail page. On the Resources tab, choose the link for RedshiftETLStepFunction to be redirected to the Step Functions console.

The RedshiftETLStepFunction state machine runs automatically, as outlined in the following workflow:
- read_sp_statement and run_sp_deploy_redshift – Performs the following actions:
- Retrieves the
sp_statements.sqlfrom Amazon S3 to get the stored procedure. - Passes the stored procedure to the
batch-execute-statementAPI to run in the Amazon Redshift cluster. - Sends back the identifier of the SQL statement to the state machine.
- Retrieves the
- wait_on_sp_deploy_redshift – Waits for at least 5 seconds.
- run_sp_deploy_redshift_status_check – Invokes the Data API’s
describeStatementto get the status of the API call. - is_run_sp_deploy_complete – Routes the next step of the ETL workflow depending on its status:
- FINISHED – Stored procedures are created in your Amazon Redshift cluster.
- FAILED – Go to the
sales_data_pipeline_failurestep and fail the ETL workflow. - All other status – Go back to the
wait_on_sp_deploy_redshiftstep to wait for the SQL statements to finish.
- setup_sales_data_pipeline – Performs the following steps:
- Initiates the
setupstored procedure that was previously created in the Amazon Redshift cluster. - Sends back the identifier of the SQL statement to the state machine.
- Initiates the
- wait_on_setup_sales_data_pipeline – Waits for at least 5 seconds.
- setup_sales_data_pipeline_status_check – Invokes the Data API’s
describeStatementto get the status of the API call. - is_setup_sales_data_pipeline_complete – Routes the next step of the ETL workflow depending on its status:
- FINISHED – Created two dimension tables (
customer_addressanditem) and one fact table (sales). - FAILED – Go to the
sales_data_pipeline_failurestep and fail the ETL workflow. - All other status – Go back to the
wait_on_setup_sales_data_pipelinestep to wait for the SQL statements to finish.
- FINISHED – Created two dimension tables (
- run_sales_data_pipeline –
LoadItemTableandLoadCustomerAddressTableare two parallel workflows that Step Functions runs at the same time. The workflows run the stored procedures that were previously created. The stored procedure loads the data into theitemandcustomer_addresstables. All other steps in the parallel sessions follow the same concept as described previously. When both parallel workflows are complete,run_load_fact_salesruns. - run_load_fact_sales – Inserts data into the
store_salestable that was created in the initial stored procedure. - Validation – When all the ETL steps are complete, the state machine reads a second SQL file from Amazon S3 (
validate_sql_statement.sql) and runs the two SQL statements using thebatch_execute_statementmethod.
The implementation of the ETL workflow is idempotent. If it fails, you can retry the job without any cleanup. For example, it recreates the stg_store_sales table each time, then deletes the target table store_sales with the data for the particular refresh date each time.
The following diagram illustrates the state machine workflow:
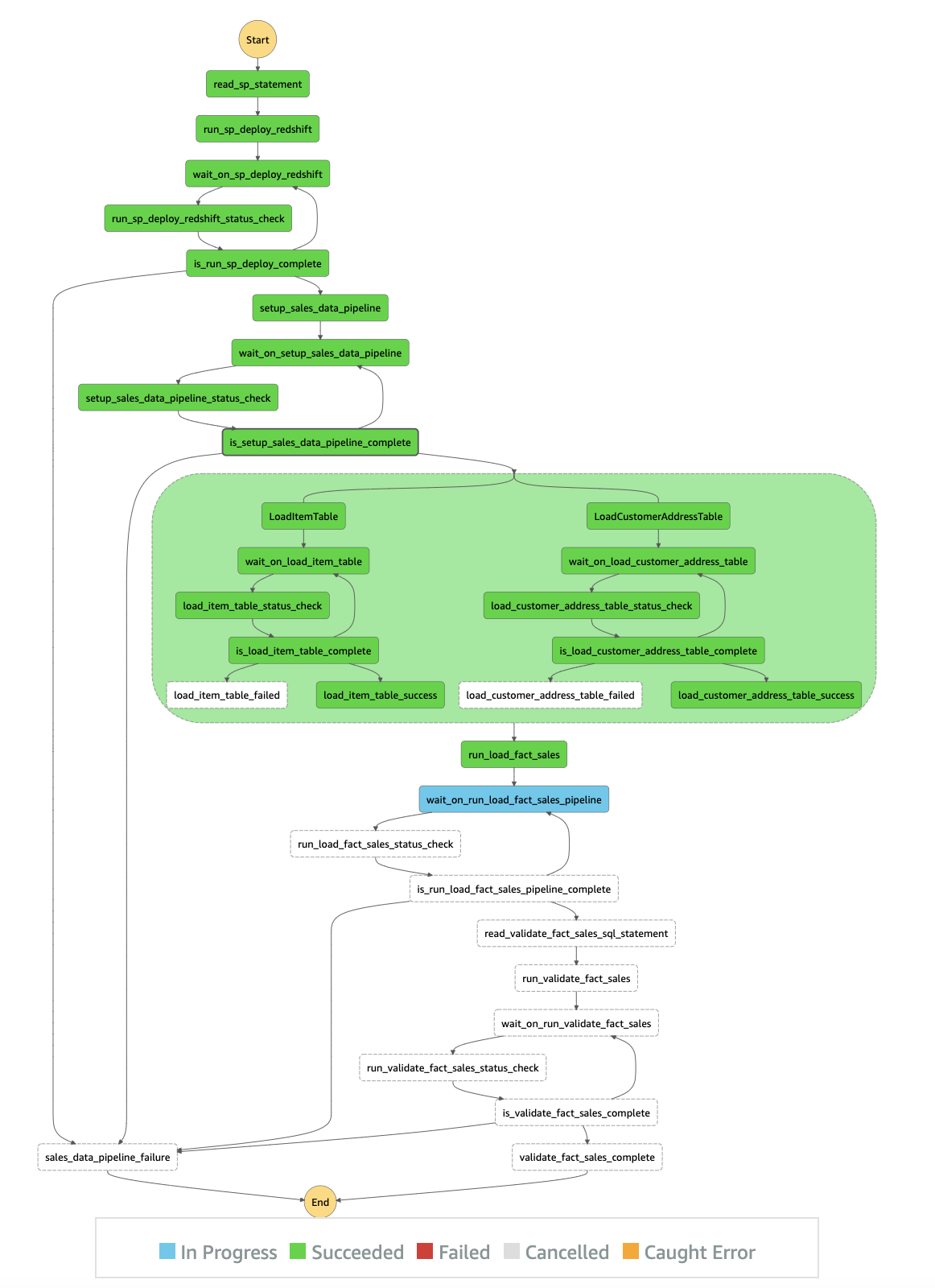
In this example, we use the task state resource arn:aws:states:::aws-sdk:redshiftdata:[apiAction] to call the corresponding Data API action. The following table summarizes the Data API actions and their corresponding AWS SDK integration API actions.
| Amazon Redshift Data API Actions | AWS SDK Integrations API Actions |
| BatchExecuteStatement | batchExecuteStatement |
| ExecuteStatement | executeStatement |
| DescribeStatement | describeStatement |
| CancelStatement | cancelStatement |
| GetStatementResult | getStatementResult |
| DescribeTable | describeTable |
| ListDatabases | listDatabases |
| ListSchemas | listSchemas |
| ListStatements | listStatements |
| ListTables | listTables |
To use AWS SDK integrations, you specify the service name and API call, and, optionally, a service integration pattern. The AWS SDK action is always camel case, and parameter names are Pascal case. For example, you can use the Step Functions action batchExecuteStatement to run multiple SQL statements in a batch as a part of a single transaction on the Data API. The SQL statements can be SELECT, DML, DDL, COPY, and UNLOAD.
Validate the ETL orchestration
The entire ETL workflow takes approximately 1 minute to run. The following screenshot shows that the ETL workflow completed successfully.

When the entire sales data pipeline is complete, you may go through the entire execution event history, as shown in the following screenshot.

Schedule the ETL orchestration
After you validate the sales data pipeline, you may opt to run the data pipeline on a daily schedule. You can accomplish this with Amazon EventBridge.
- On the EventBridge console, create a rule to run the
RedshiftETLStepFunctionstate machine daily.

- To invoke the
RedshiftETLStepFunctionstate machine on a schedule, choose Schedule and define the appropriate frequency needed to run the sales data pipeline.

- Specify the target state machine as
RedshiftETLStepFunctionand choose Create.

You can confirm the schedule on the rule details page.

Clean up
Clean up the resources created by the CloudFormation template to avoid unnecessary cost to your AWS account. You can delete the CloudFormation stack by selecting the stack on the AWS CloudFormation console and choosing Delete. This action deletes all the resources it provisioned. If you manually updated a template-provisioned resource, you may see some issues during cleanup; you need to clean these up independently.
Limitations
The Data API and Step Functions AWS SDK integration offers a robust mechanism to build highly distributed ETL applications within minimal developer overhead. Consider the following limitations when using the Data API and Step Functions:
Conclusion
In this post, we demonstrated how to build an ETL orchestration using the Amazon Redshift Data API and Step Functions with AWS SDK integration.
To learn more about the Data API, see Using the Amazon Redshift Data API to interact with Amazon Redshift clusters and Using the Amazon Redshift Data API.
About the Authors
 Jason Pedreza is an Analytics Specialist Solutions Architect at AWS with over 13 years of data warehousing experience. Prior to AWS, he built data warehouse solutions at Amazon.com. He specializes in Amazon Redshift and helps customers build scalable analytic solutions.
Jason Pedreza is an Analytics Specialist Solutions Architect at AWS with over 13 years of data warehousing experience. Prior to AWS, he built data warehouse solutions at Amazon.com. He specializes in Amazon Redshift and helps customers build scalable analytic solutions.
 Bipin Pandey is a Data Architect at AWS. He loves to build data lake and analytics platforms for his customers. He is passionate about automating and simplifying customer problems with the use of cloud solutions.
Bipin Pandey is a Data Architect at AWS. He loves to build data lake and analytics platforms for his customers. He is passionate about automating and simplifying customer problems with the use of cloud solutions.
 David Zhang is an AWS Solutions Architect who helps customers design robust, scalable, and data-driven solutions across multiple industries. With a background in software development, David is an active leader and contributor to AWS open-source initiatives. He is passionate about solving real-world business problems and continuously strives to work from the customer’s perspective. Feel free to connect with him on LinkedIn.
David Zhang is an AWS Solutions Architect who helps customers design robust, scalable, and data-driven solutions across multiple industries. With a background in software development, David is an active leader and contributor to AWS open-source initiatives. He is passionate about solving real-world business problems and continuously strives to work from the customer’s perspective. Feel free to connect with him on LinkedIn.