AWS Big Data Blog
How FanDuel Group secures personally identifiable information in a data lake using AWS Lake Formation
This post is co-written with Damian Grech from FanDuel
FanDuel Group is an innovative sports-tech entertainment company that is changing the way consumers engage with their favorite sports, teams, and leagues. The premier gaming destination in the US, FanDuel Group consists of a portfolio of leading brands across gaming, sports betting, daily fantasy sports, advance-deposit wagering, and TV/media, including FanDuel, Betfair US, and TVG. FanDuel Group has a presence across 50 states and over 8.5 million customers. The company is based in New York with offices in California, New Jersey, Florida, Oregon, and Scotland. FanDuel Group is a subsidiary of Flutter Entertainment plc, the world’s largest sports betting and gaming operator with a portfolio of globally recognized brands and a constituent of the FTSE 100 index of the London Stock Exchange.
In this post, we discuss how FanDuel used AWS Lake Formation and Amazon Redshift Spectrum to restrict access to personally identifiable information (PII) in their data lake.
The challenge
In 2018, a series of mergers led to the creation of FanDuel Group, and the combined data engineering team found themselves operating three data warehouses running on Amazon Redshift. The team decided to create a new single platform to replace the three separate warehouses, consisting of a data warehouse containing the core business data model and a data lake to catalog and hold all other types of data. FanDuel’s vision was to create an unified data platform that served their data requirements. This included the ability to ingest and organize real-time and batch datasets, and secure and govern PII.
Because the end-users of the existing data warehouses were familiar with Amazon Redshift, it was critical that they be able to access the data lake using Amazon Redshift. Other important architecture considerations included a simplified user experience, the ability to scale to huge data volumes, and a robust security model to provision relevant data to analysts and data scientists.
To accomplish the vision, FanDuel decided to modernize the data platform and introduce Amazon Simple Storage Service (Amazon S3)-based data lakes. Data lakes are a logical construct that allows data to be stored in its native format using open data formats. With a data lake architecture, FanDuel can enable data analysts to analyze large volume of data without significant modeling. Also, data lakes allow FanDuel to store structured and unstructured data.
Some of the data to be stored in the data lake was customer PII, so access to this category of data needed to be carefully restricted to only employees who required access to perform their job functions. To address these security challenges, FanDuel first tested out a tag-based approach on Amazon S3 to restrict access to the PII data. The idea was to write two datasets for a single dataset—one with PII and another without PII—and apply tags for files where PII is stored, securing files using AWS Identity and Access Management (IAM) policies. This approach was complex and needed 100–200 hours of development time for every data source that was ingested.
Solution overview
FanDuel decided to use Lake Formation and Redshift Spectrum to solve this challenge. The following architectural diagram shows how FanDuel secured their data lake.
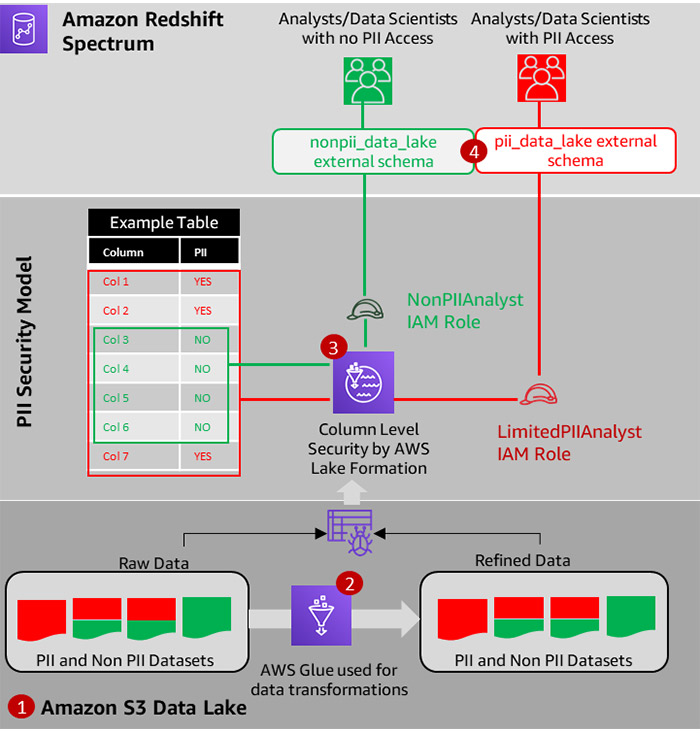
The solution includes the following steps:
- The FanDuel team registered the S3 location in Lake Formation.
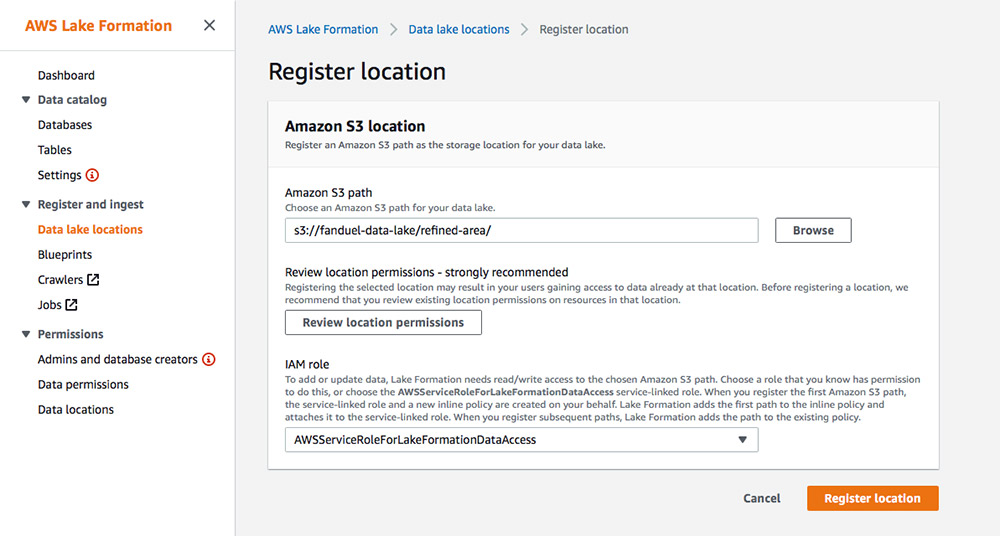
After the location is registered, Lake Formation takes control of the data lake, thereby eliminating the need to set up complicated policies in IAM.
- FanDuel built AWS Glue ETL jobs to extract data from sources, including MySQL databases and flat files. They used AWS Glue to cleanse and transform raw data to form refined datasets stored in Parquet-formatted files. They also used AWS Glue crawlers to register the cleansed datasets in the Data Catalog.
- The team used Lake Formation to set up column-based permissions using two roles:
- LimitedPIIAnalyst – Granted access to all columns. Only analysts who needed access to PII data were assigned this role.
- NonPIIAnalyst – Granted access to non-PII columns. By default, analysts using the data lake were assigned this role.
- FanDuel created two external schemas using Redshift Spectrum: one using the
NonPIIAnalystrole, and one using theLimitedPIIAnalystThe following code is an example of the DDL that uses the role that was set up in Lake Formation:
FanDuel could already manage access permissions by adding or removing users from a group in Amazon Redshift, so they already had a group consisting of only the analysts who should be permitted access to PII. The following code grants this group access to the limitedpii_data_lake schema, which effectively means only this group can query the data lake using the LimitedPIIAnalyst role:
Benefits
The ability to extend queries to the data lake with Redshift Spectrum and have column-level access control provides superior control over the S3 tag-based permissions approach that was originally considered. This architecture provided the following benefits for FanDuel:
- FanDuel could offer new capabilities to data analysts. For example, data analysts could quickly access raw data with PII and combine it with existing data in Amazon Redshift. Lake Formation provided a single view for monitoring the data access patterns.
- Lake Formation column-level access control allowed them to secure PII data, which otherwise would have taken a complex S3 tag-based approach. This saved 100–200 hours of development time for every new data source and data footprint, because the original approach required creating two files (one with PII and another without PII), tagging files, and setting up permissions based on tags.
- The ability to extend access from Amazon Redshift to the data lake with appropriate access control has allowed FanDuel to reduce data stored in Amazon Redshift.
Conclusion
FanDuel will leverage its new data platform to ingest additional data sources with real-time data so analysts and data scientists can gain insights and improve customer experience.
Questions or feedback? Send an email to lakeformation-feedback@amazon.com.
About the Authors
 Damian Grech is a Data Engineering Senior Manager at FanDuel. Damian has over 15 years of experience in software delivery and has worked with organizations ranging from large enterprises to start-ups at their infant stages. In his spare time, you can find him either experimenting in the kitchen or trailing the Scottish Highlands.
Damian Grech is a Data Engineering Senior Manager at FanDuel. Damian has over 15 years of experience in software delivery and has worked with organizations ranging from large enterprises to start-ups at their infant stages. In his spare time, you can find him either experimenting in the kitchen or trailing the Scottish Highlands.
 Shiv Narayanan is Global Business Development Manager for Data Lakes and Analytics solutions at AWS. He works with AWS customers across the globe to strategize, build, develop and deploy modern data platforms. Shiv loves music, travel, food and trying out new tech.
Shiv Narayanan is Global Business Development Manager for Data Lakes and Analytics solutions at AWS. He works with AWS customers across the globe to strategize, build, develop and deploy modern data platforms. Shiv loves music, travel, food and trying out new tech.
 Sidhanth Muralidhar is a Senior Technical Account Manager at Amazon Web Services. He works with large enterprise customers who run their workloads on AWS. He is passionate about working with customers and helping them in their cloud journey. In his spare time, he loves to play and watch football.
Sidhanth Muralidhar is a Senior Technical Account Manager at Amazon Web Services. He works with large enterprise customers who run their workloads on AWS. He is passionate about working with customers and helping them in their cloud journey. In his spare time, he loves to play and watch football.