AWS Big Data Blog
How William Hill migrated NoSQL workloads at scale to Amazon Keyspaces
Social gaming and online sports betting are competitive environments. The game must be able to handle large volumes of unpredictable traffic while simultaneously promising zero downtime. In this domain, user retention is no longer just desirable, it’s critical. William Hill is a global online gambling company based in London, England, and it is the founding member of the UK Betting and Gaming Council. They share the mission to champion the betting and gaming industry and set world-class standards to make sure of an enjoyable, fair, and safe betting and gambling experience for all of their customers. In sports betting, William Hill is an industry-leading brand, awarded with prestigious industry titles like the IGA Awards Sports Betting Operator of the year in 2019, 2020, and 2022, and the SBC Awards Racing Sportsbook of the Year in 2019. William Hill has been acquired by Caesars Entertainment, Inc (NASDAQ: CZR) in April 2021, and it’s the largest casino-entertainment company in the US and one of the world’s most diversified casino-entertainment providers. At the heart of William Hill gaming platform is a NoSQL database that maintains 100% uptime, scales in real-time to handle millions of users or more, and provides users with a responsive and personalized experience across all of their devices.
In this post, we’ll discuss how William Hill moved their workload from Apache Cassandra to Amazon Keyspaces (for Apache Cassandra) with zero downtime using AWS Glue ETL.
William Hill was facing challenges regarding scalability, cluster instability, high operational costs, and manual patching and server maintenance. They were looking for a NoSQL solution which was scalable, highly-available, and completely managed. This let them focus on providing better user experience rather than maintaining infrastructure. William Hill Limited decided to move forward with Amazon Keyspaces, since it can run Apache Cassandra workloads on AWS using the same Cassandra application code and developer tools used today, without the need to provision, patch, manage servers, install, maintain, or operate software.
Solution overview
William Hill Limited wanted to migrate their existing Apache Cassandra workloads to Amazon Keyspaces with a replication lag of minutes, with minimum migration costs and development efforts. Therefore, AWS Glue ETL was leveraged to deliver the desired outcome.
AWS Glue is a serverless data integration service that provides multiple benefits for migration:
- No infrastructure to maintain; allocates the necessary computing power and runs multiple migration jobs simultaneously.
- All-in-one pricing model that includes infrastructure and is 55% cheaper than other cloud data integration options.
- No lock in with the service; possible to develop data migration pipelines in open-source Apache Spark (Spark SQL, PySpark, and Scala).
- Migration pipeline can be scaled fearlessly with Amazon Keyspaces and AWS Glue.
- Built-in pipeline monitoring to make sure of in-migration continuity.
- AWS Glue ETL jobs make it possible to perform bulk data extraction from Apache Cassandra and ingest to Amazon Keyspaces.
In this post, we’ll take you through William Hill’s journey of building the migration pipeline from scratch to migrate the Apache Cassandra workload to Amazon Keyspaces by leveraging AWS Glue ETL with DataStax Spark Cassandra connector.
For the purpose of this post, let’s look at a typical Cassandra Network setup on AWS and the mechanism used to establish the connection with AWS Glue ETL. The migration solution described also works for Apache Cassandra hosted on on-premises clusters.
Architecture overview
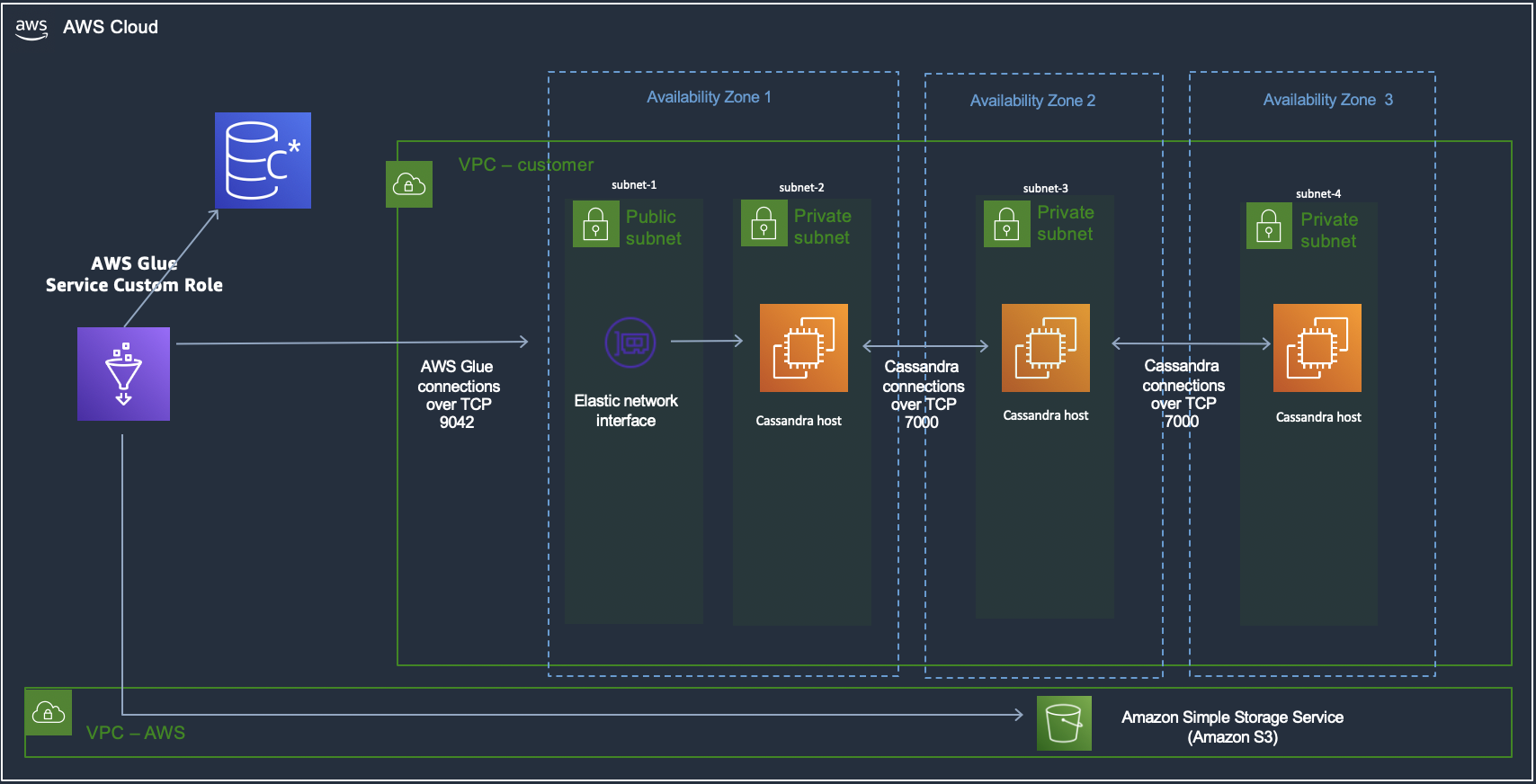
The architecture demonstrates the migration environment that requires Amazon Keyspaces, AWS Glue, Amazon Simple Storage Service (Amazon S3), and the Apache Cassandra cluster. To avoid a high CPU utilization/saturation on the Apache Cassandra cluster during the migration process, you might want to deploy another Cassandra datacenter to isolate your production from the migration workload to make the migration process seamless for your customers.
Amazon S3 has been used for staging while migrating data from Apache Cassandra to Amazon Keyspaces to make sure that the IO load on Cassandra serving live traffic on production is minimized, in case the data upload to Amazon Keyspaces fails and a retry must be done.
Prerequisites
The Apache Cassandra cluster is hosted on Amazon Elastic Compute Cloud (Amazon EC2) instances, spread across three availability zones, and hosted in private subnets. AWS Glue ETL is hosted on Amazon Virtual Private Cloud (Amazon VPC) and thus needs a AWS Glue Studio custom Connectors and Connections to be setup to communicate with the Apache Cassandra nodes hosted on the private subnets in the customer VPC. Thereby, this enables the connection to the Cassandra cluster hosted in the VPC. The DataStax Spark Cassandra Connector must be downloaded and saved onto an Amazon S3 bucket: s3://$MIGRATION_BUCKET/jars/spark-cassandra-connector-assembly_2.12-3.2.0.jar.
Let’s create an AWS Glue Studio custom connector named cassandra_connection and its corresponding connection named conn-cassandra-custom for AWS region us-east-1.
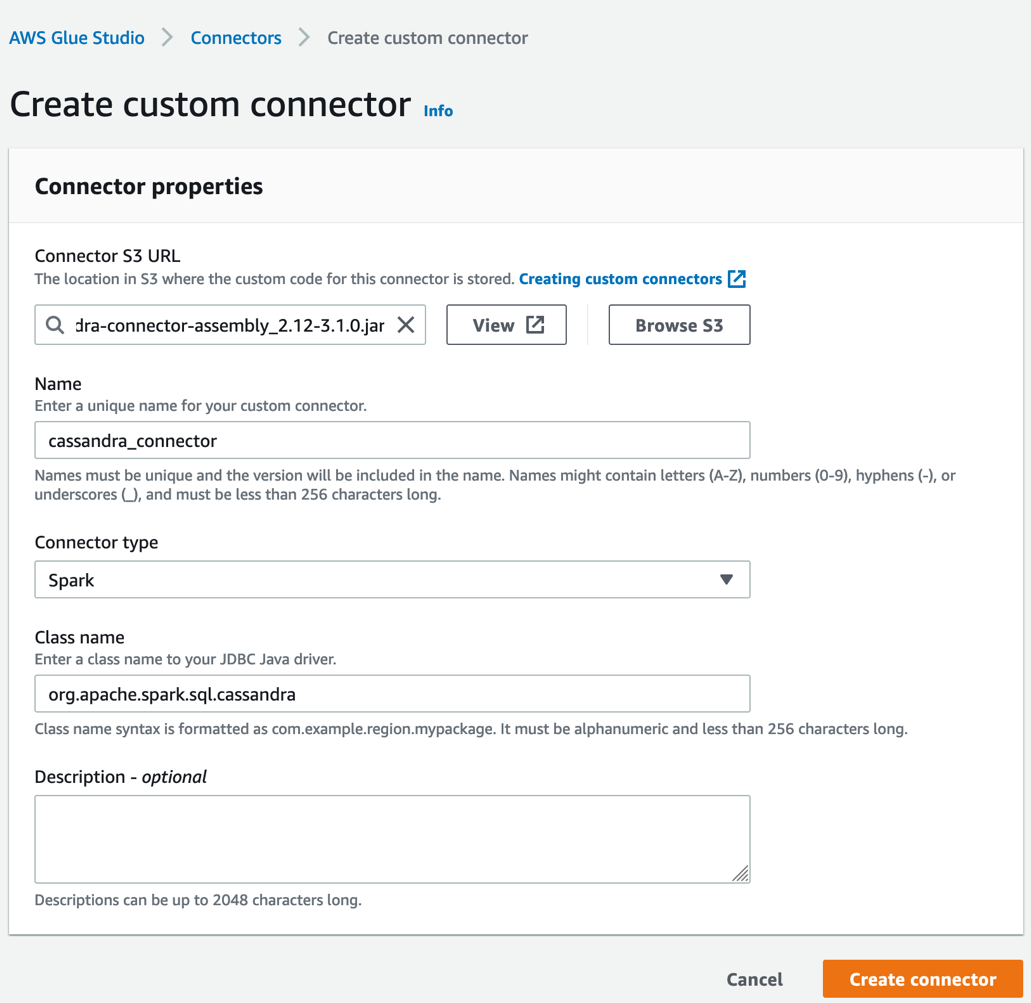
For the connector created, create an AWS Glue Studio connection and populate it with network information VPC, and a Subnet allowing for AWS Glue ETL to establish a connection with Apache Casandra.
- Name:
conn-cassandra-custom - Network Options
- VPC:
vpc-XXXXEXAMPLE - Subnet:
subnet-ee1111d1EXAMPLE - Security Group: sg-0f0f0f000000f000fSAMPLE
- VPC:
Let’s begin by creating a keyspace and table in Amazon Keyspaces using Amazon Keyspaces Console or CQLSH, and then create a target keyspace named target_keyspace and a target table named target_table.

After the table has been created, switch the table to on-demand mode to pre-warm the table and avoid AWS Glue ETL job throttling failures. The following script will update the throughput mode.
Let’s go ahead and create two Amazon S3 buckets to support the migration process. The first bucket (s3://your-spark-cassandra-connector-bucket-name)should store the spark Cassandra connector assembly jar file, Cassandra, and Keyspaces configuration YAML files.
The second bucket (s3://your-migration-stage-bucket-name) will be used to store intermediate parquet files to identify the delta between the Cassandra cluster and the Amazon Keyspaces table to track changes between subsequent executions of the AWS Glue ETL jobs.
In the following KeyspacesConnector.conf, set your contact points to connect to Amazon Keyspaces, and replace the username and the password to the AWS credentials.
Using the RateLimitingRequestThrottler we can make sure that requests don’t exceed the configured Keyspaces capacity. The G1.X DPU creates one executor per worker. The RateLimitingRequestThrottler in this example is set for 1000 requests per second. With this configuration, and G.1X DPU, you’ll achieve 1000 request per AWS Glue worker. Adjust the max-requests-per-second accordingly to fit your workload. Increase the number of workers to scale throughput to a table.
Similarly, create a CassandraConnector.conf file, set the contact points to connect to the Cassandra cluster, and replace the username and the password respectively.
Build AWS Glue ETL migration pipeline with Amazon Keyspaces
To build reliable, consistent delta upload Glue ETL pipeline, let’s decouple the migration process into two AWS Glue ETLs.
- CassandraToS3 Glue ETL: Read data from the Apache Cassandra cluster and transfer the migration workload to Amazon S3 in the Apache Parquet format. To identify incremental changes in the Cassandra tables, the job stores separate parquet files with primary keys with an updated timestamp.
- S3toKeyspaces Glue ETL: Uploads the migration workload from Amazon S3 to Amazon Keyspaces. During the first run, the ETL uploads the complete data set from Amazon S3 to Amazon Keyspaces, and for the subsequent run calculates the incremental changes by comparing the updated timestamp across two subsequent runs and calculating the incremental difference. The job also takes care of inserting new records, updating existing records, and deleting records based on the incremental difference.
In this example, we’ll use Scala to write the AWS Glue ETL, but you can also use PySpark.
Let’s go ahead and create an AWS Glue ETL job named CassandraToS3 with the following job parameters:
The CassandraToS3 Glue ETL job reads data from the Apache Cassandra table source_keyspace.source_table and writes it to the S3 bucket in the Apache Parquet format. The job rotates the parquet files to help identify delta changes in the data between consecutive job executions. To identify inserts, updates, and deletes, you must know primary key and columns write times (updated timestamp) in the Cassandra cluster up front. Our primary key consists of several columns userid, level, gameid, and a write time column updatetime. If you have multiple updated columns, then you must use more than one write time columns with an aggregation function. For example, for email and updatetime, take the maximum value between write times for email and updatetime.
The following AWS Glue spark code offloads data to Amazon S3 using the spark-cassandra-connector. The script takes four parameters KEYSPACE_NAME, KEYSPACE_TABLE, S3_URI_CURRENT_CHANGE, S3_URI_CURRENT_CHANGE, and S3_URI_NEW_CHANGE.
To upload the data from Amazon S3 to Amazon Keyspaces, you must create a S3toKeyspaces Glue ETL job using the Glue spark code to read the parquet files from the Amazon S3 bucket created as an output of CassandraToS3 Glue job and identify inserts, updates, deletes, and execute requests against the target table in Amazon Keyspaces. The code sample provided takes four parameters: KEYSPACE_NAME, KEYSPACE_TABLE, S3_URI_CURRENT_CHANGE, S3_URI_CURRENT_CHANGE, and S3_URI_NEW_CHANGE.
Let’s go ahead and create our second AWS Glue ETL job S3toKeyspaces with the following job parameters:
Job scheduling
The final step is to configure AWS Glue Triggers or Amazon EventBridge depending on your scheduling needs to trigger S3toKeyspaces Glue ETL when the job CassandraToS3 has succeeded. If you want to run the CassandraToS3 based on the schedule and configure the schedule option, then the following example showcases how to schedule cassandraToS3 to run every 15 minutes.

Job tuning
There are Spark settings recommended to begin with Amazon Keyspaces, which can then be increased later as appropriate for your workload.
- Use a Spark partition size (groups multiple Cassandra rows) smaller than 8 MBs to avoid replaying large Spark tasks during a task failure.
- Use a low concurrent number of writes per DPU with a large number of retries. Add the following options to the job parameters:
--conf spark.cassandra.query.retry.count=500--conf spark.cassandra.output.concurrent.writes=3. - Set
spark.task.maxFailuresto a bounded value. For example, you can start from 32 and increase as needed. This option can help you increase a number of tasks reties during a table pre-warm stage. Add the following option to the job parameters:--conf spark.task.maxFailures=32 - Another recommendation is to turn off batching to improve random access patterns. Add the following options to the job parameters:
spark.cassandra.output.batch.size.rows=1
spark.cassandra.output.batch.grouping.key=nonespark.cassandra.output.batch.grouping.buffer.size=100 - Randomize your workload. Amazon Keyspaces partitions data using partition keys. Although Amazon Keyspaces has built-in logic to help load balance requests for the same partition key, loading the data is faster and more efficient if you randomize the order because you can take advantage of the built-in load balancing of writing to different partitions. To spread the writes across the partitions evenly, you must randomize the data in the dataframe. You might use a rand function to shuffle rows in the dataframe.
Summary
William Hill was able to migrate their workload from Apache Cassandra to Amazon Keyspaces at scale using AWS Glue, without the needs to make any changes on their application tech stack. The adoption of Amazon Keyspaces has provided them with the headroom to focus on their Application and customer experience, as with Amazon Keyspaces there’s no need to manage servers, get performance at scale, highly-scalable, and secure solution with the ability to handle the sudden spike in demand.
In this post, you saw how to use AWS Glue to migrate the Cassandra workload to Amazon Keyspaces, and simultaneously keep your Cassandra source databases completely functional during the migration process. When your applications are ready, you can choose to cut over your applications to Amazon Keyspaces with minimal replication lag in sub minutes between the Cassandra cluster and Amazon Keyspaces. You can also use a similar pipeline to replicate the data back to the Cassandra cluster from Amazon Keyspaces to maintain data consistency, if needed. Here you can find the documents and code to help accelerate your migration to Amazon Keyspaces.
About the Authors
 Nikolai Kolesnikov is a Senior Data Architect and helps AWS Professional Services customers build highly-scalable applications using Amazon Keyspaces. He also leads Amazon Keyspaces ProServe customer engagements.
Nikolai Kolesnikov is a Senior Data Architect and helps AWS Professional Services customers build highly-scalable applications using Amazon Keyspaces. He also leads Amazon Keyspaces ProServe customer engagements.
 Kunal Gautam is a Senior Big Data Architect at Amazon Web Services. Having experience in building his own Startup and working along with enterprises, he brings a unique perspective to get people, business and technology work in tandem for customers. He is passionate about helping customers in their digital transformation journey and enables them to build scalable data and advance analytics solutions to gain timely insights and make critical business decisions. In his spare time, Kunal enjoys Marathons, Tech Meetups and Meditation retreats.
Kunal Gautam is a Senior Big Data Architect at Amazon Web Services. Having experience in building his own Startup and working along with enterprises, he brings a unique perspective to get people, business and technology work in tandem for customers. He is passionate about helping customers in their digital transformation journey and enables them to build scalable data and advance analytics solutions to gain timely insights and make critical business decisions. In his spare time, Kunal enjoys Marathons, Tech Meetups and Meditation retreats.