AWS Big Data Blog
Real-time analytics with Amazon Redshift streaming ingestion
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more.
Amazon Redshift is a fast, scalable, secure, and fully managed cloud data warehouse that makes it simple and cost-effective to analyze all your data using standard SQL. Amazon Redshift offers up to three times better price performance than any other cloud data warehouse. Tens of thousands of customers use Amazon Redshift to process exabytes of data per day and power analytics workloads such as high-performance business intelligence (BI) reporting, dashboarding applications, data exploration, and real-time analytics.
We’re excited to launch Amazon Redshift streaming ingestion for Amazon Kinesis Data Streams, which enables you to ingest data directly from the Kinesis data stream without having to stage the data in Amazon Simple Storage Service (Amazon S3). Streaming ingestion allows you to achieve low latency in the order of seconds while ingesting hundreds of megabytes of data into your Amazon Redshift cluster.
In this post, we walk through the steps to create a Kinesis data stream, generate and load streaming data, create a materialized view, and query the stream to visualize the results. We also discuss the benefits of streaming ingestion and common use cases.
The need for streaming ingestion
We hear from our customers that you want to evolve your analytics from batch to real time, and access your streaming data in your data warehouses with low latency and high throughput. You also want to enrich your real-time analytics by combining them with other data sources in your data warehouse.
Use cases for Amazon Redshift streaming ingestion center around working with data that is generated continually (streamed) and needs to be processed within a short period (latency) of its generation. Sources of data can vary, from IoT devices to system telemetry, utility service usage, geolocation of devices, and more.
Before the launch of streaming ingestion, if you wanted to ingest real-time data from Kinesis Data Streams, you needed to stage your data in Amazon S3 and use the COPY command to load your data. This usually involved latency in the order of minutes and needed data pipelines on top of the data loaded from the stream. Now, you can ingest data directly from the data stream.
Solution overview
Amazon Redshift streaming ingestion allows you to connect to Kinesis Data Streams directly, without the latency and complexity associated with staging the data in Amazon S3 and loading it into the cluster. You can now connect to and access the data from the stream using SQL and simplify your data pipelines by creating materialized views directly on top of the stream. The materialized views can also include SQL transforms as part of your ELT (extract, load and transform) pipeline.
After you define the materialized views, you can refresh them to query the most recent stream data. This means that you can perform downstream processing and transformations of streaming data using SQL at no additional cost and use your existing BI and analytics tools for real-time analytics.
Amazon Redshift streaming ingestion works by acting as a stream consumer. A materialized view is the landing area for data that is consumed from the stream. When the materialized view is refreshed, Amazon Redshift compute nodes allocate each data shard to a compute slice. Each slice consumes data from the allocated shards until the materialized view attains parity with the stream. The very first refresh of the materialized view fetches data from the TRIM_HORIZON of the stream. Subsequent refreshes read data from the last SEQUENCE_NUMBER of the previous refresh until it reaches parity with the stream data. The following diagram illustrates this workflow.

Setting up streaming ingestion in Amazon Redshift is a two-step process. You first need to create an external schema to map to Kinesis Data Streams and then create a materialized view to pull data from the stream. The materialized view must be incrementally maintainable.
Create a Kinesis data stream
First, you need to create a Kinesis data stream to receive the streaming data.
- On the Amazon Kinesis console, choose Data streams.
- Choose Create data stream.
- For Data stream name, enter
ev_stream_data. - For Capacity mode, select On-demand.

- Provide the remaining configurations as needed to create your data stream.
Generate streaming data with the Kinesis Data Generator
You can synthetically generate data in JSON format using the Amazon Kinesis Data Generator (KDG) utility and the following template:
The following screenshot shows the template on the KDG console.

Load reference data
In the previous step, we showed you how to load synthetic data into the stream using the Kinesis Data Generator. In this section, you load reference data related to electric vehicle charging stations to the cluster.
Download the Plug-In EVerywhere Charging Station Network data from the City of Austin’s open data portal. Split the latitude and longitude values in the dataset and load it in to a table with the following schema.
Create a materialized view
You can access your data from the data stream using SQL and simplify your data pipelines by creating materialized views directly on top of the stream. Complete the following steps:
- Create an external schema to map the data from Kinesis Data Streams to an Amazon Redshift object:
- Create an AWS Identity and Access Management (IAM) role (for the policy, see Getting started with streaming ingestion).
Now you can create a materialized view to consume the stream data. You can choose to use the SUPER datatype to store the payload as is in JSON format or use Amazon Redshift JSON functions to parse the JSON data into individual columns. For this post, we use the second method because the schema is well defined.
- Create the materialized view so it’s distributed on the UUID value from the stream and is sorted by the
refresh_timevalue. Therefresh_timeis the start time of the materialized view refresh that loaded the record. The materialized view is set to auto refresh and will be refreshed as data keeps arriving in the stream. - The materialized view above could be re-written as:
Refreshing materialized views for streaming ingestion
The materialized view is auto-refreshed as long as there is new data on the KDS stream. You can also disable auto-refresh and run a manual refresh or schedule a manual refresh using the Redshift Console UI.
Query the stream
You can now query the refreshed materialized view to get usage statistics:
The following table contains the results.
| connectiontime | energy_consumed | #users |
| 2022-02-27 23:52:07+00 | 72870 | 131 |
| 2022-02-27 23:52:06+00 | 510892 | 998 |
| 2022-02-27 23:52:05+00 | 461994 | 934 |
| 2022-02-27 23:52:04+00 | 540855 | 1064 |
| 2022-02-27 23:52:03+00 | 494818 | 999 |
| 2022-02-27 23:52:02+00 | 491586 | 1000 |
| 2022-02-27 23:52:01+00 | 499261 | 1000 |
| 2022-02-27 23:52:00+00 | 774286 | 1498 |
| 2022-02-27 23:51:59+00 | 505428 | 1000 |
| 2022-02-27 23:51:58+00 | 262413 | 500 |
| 2022-02-27 23:51:57+00 | 486567 | 1000 |
| 2022-02-27 23:51:56+00 | 477892 | 995 |
| 2022-02-27 23:51:55+00 | 591004 | 1173 |
| 2022-02-27 23:51:54+00 | 422243 | 823 |
| 2022-02-27 23:51:53+00 | 521112 | 1028 |
| 2022-02-27 23:51:52+00 | 240679 | 469 |
| 2022-02-27 23:51:51+00 | 547464 | 1104 |
| 2022-02-27 23:51:50+00 | 495332 | 993 |
| 2022-02-27 23:51:49+00 | 444154 | 898 |
| 2022-02-27 23:51:24+00 | 505007 | 998 |
| 2022-02-27 23:51:23+00 | 499133 | 999 |
| 2022-02-27 23:29:14+00 | 497747 | 997 |
| 2022-02-27 23:29:13+00 | 750031 | 1496 |
Next, you can join the materialized view with the reference data to analyze the charging station consumption data for the last 5 minutes and break it down by station category:
The following table contains the results.
| connectiontime | energy_consumed | #users | category |
| 2022-02-27 23:55:34+00 | 188887 | 367 | Workplace |
| 2022-02-27 23:55:34+00 | 133424 | 261 | Parking |
| 2022-02-27 23:55:34+00 | 88446 | 195 | Multifamily Commercial |
| 2022-02-27 23:55:34+00 | 41082 | 81 | Municipal |
| 2022-02-27 23:55:34+00 | 13415 | 29 | Education |
| 2022-02-27 23:55:34+00 | 12917 | 24 | Healthcare |
| 2022-02-27 23:55:34+00 | 11147 | 19 | Retail |
| 2022-02-27 23:55:34+00 | 8281 | 14 | Parks and Recreation |
| 2022-02-27 23:55:34+00 | 5313 | 10 | Hospitality |
| 2022-02-27 23:54:45+00 | 146816 | 301 | Workplace |
| 2022-02-27 23:54:45+00 | 112381 | 216 | Parking |
| 2022-02-27 23:54:45+00 | 75727 | 144 | Multifamily Commercial |
| 2022-02-27 23:54:45+00 | 29604 | 55 | Municipal |
| 2022-02-27 23:54:45+00 | 13377 | 30 | Education |
| 2022-02-27 23:54:45+00 | 12069 | 26 | Healthcare |
Visualize the results
You can set up a simple visualization using Amazon QuickSight. For instructions, refer to Quick start: Create an Amazon QuickSight analysis with a single visual using sample data.
We create a dataset in QuickSight to join the materialized view with the charging station reference data.

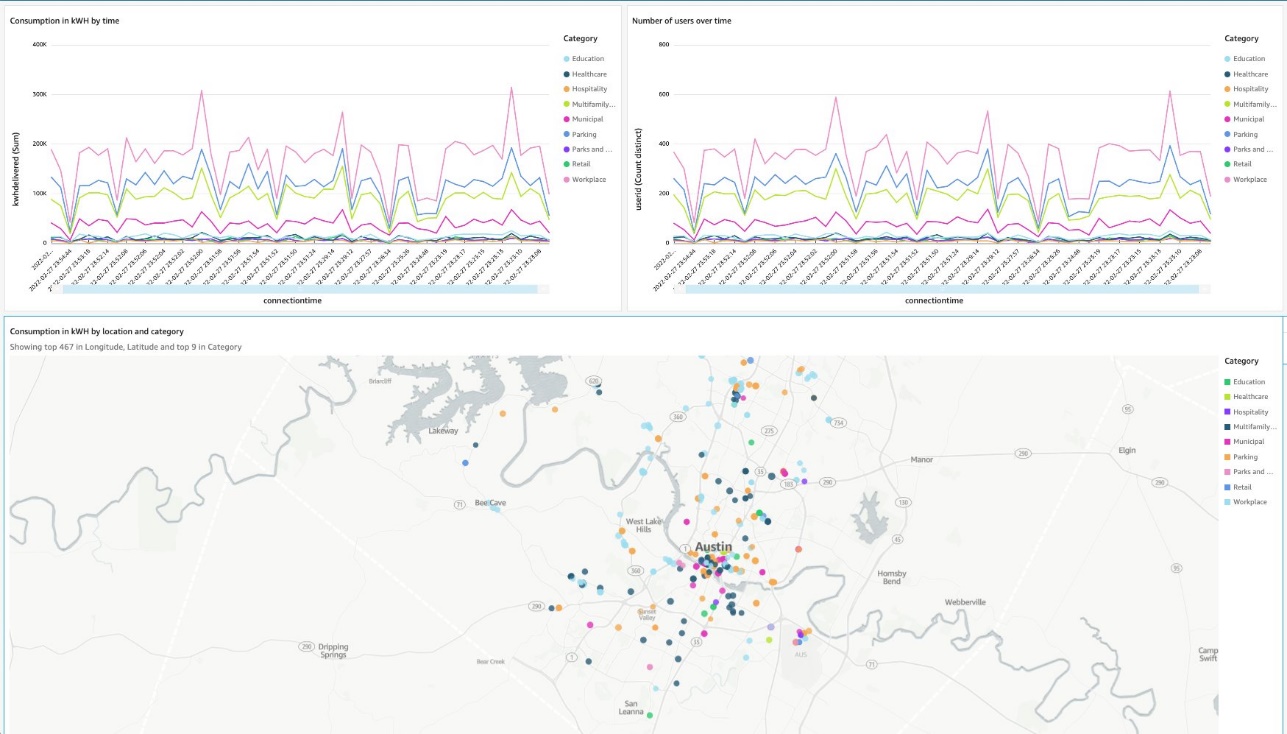
Then, create a dashboard showing energy consumption and number of connected users over time. The dashboard also shows the list of locations on the map by category.
Streaming ingestion benefits
In this section, we discuss some of the benefits of streaming ingestion.
High throughput with low latency
Amazon Redshift can handle and process several gigabytes of data per second from Kinesis Data Streams. (Throughput is dependent on the number of shards in the data stream and the Amazon Redshift cluster configuration.) This allows you to experience low latency and high bandwidth when consuming streaming data, so you can derive insights from your data in seconds instead of minutes.
As we mentioned earlier, the key differentiator with the direct ingestion pull approach in Amazon Redshift is lower latency, which is in seconds. Contrast this to the approach of creating a process to consume the streaming data, staging the data in Amazon S3, and then running a COPY command to load the data into Amazon Redshift. This approach introduces latency in minutes due to the multiple steps involved in processing the data.
Straightforward setup
Getting started is easy. All the setup and configuration in Amazon Redshift uses SQL, which most cloud data warehouse users are already familiar with. You can get real-time insights in seconds without managing complex pipelines. Amazon Redshift with Kinesis Data Streams is fully managed, and you can run your streaming applications without requiring infrastructure management.
Increased productivity
You can perform rich analytics on streaming data within Amazon Redshift and using existing familiar SQL without needing to learn new skills or languages. You can create other materialized views, or views on materialized views, to do most of your ELT data pipeline transforms within Amazon Redshift using SQL.
Streaming ingestion use cases
With near-real time analytics on streaming data, many use cases and industry verticals applications become possible. The following are just some of the many application use cases:
- Improve the gaming experience – You can focus on in-game conversions, player retention, and optimizing the gaming experience by analyzing real-time data from gamers.
- Analyze clickstream user data for online advertising – The average customer visits dozens of websites in a single session, yet marketers typically analyze only their own websites. You can analyze authorized clickstream data ingested into the warehouse to assess your customer’s footprint and behavior, and target ads to your customers just-in-time.
- Real-time retail analytics on streaming POS data – You can access and visualize all your global point of sale (POS) retail sales transaction data for real-time analytics, reporting, and visualization.
- Deliver real-time application insights – With the ability to access and analyze streaming data from your application log files and network logs, developers and engineers can conduct real-time troubleshooting of issues, deliver better products, and alert systems for preventative measures.
- Analyze IoT data in real time – You can use Amazon Redshift streaming ingestion with Amazon Kinesis services for real-time applications such as device status and attributes such as location and sensor data, application monitoring, fraud detection, and live leaderboards. You can ingest streaming data using Kinesis Data Streams, process it using Amazon Kinesis Data Analytics, and emit the results to any data store or application using Kinesis Data Streams with low end-to-end latency.
Conclusion
This post showed how to create Amazon Redshift materialized views to ingest data from Kinesis data streams using Amazon Redshift streaming ingestion. With this new feature, you can easily build and maintain data pipelines to ingest and analyze streaming data with low latency and high throughput.
The Amazon Redshift streaming ingestion feature is now generally available in all AWS regions where Amazon Redshift is available. To get started with Amazon Redshift streaming ingestion, provision an Amazon Redshift cluster on the current track and verify your cluster is running version 1.0.43980 or newer.
For more information, refer to Streaming ingestion.
About the Author
 Sam Selvan is a Principal Analytics Solution Architect with Amazon Web Services.
Sam Selvan is a Principal Analytics Solution Architect with Amazon Web Services.
November 2022: This post was updated to accommodate changes introduced by Amazon Redshift Streaming Ingestion becoming Generally Available.