AWS Big Data Blog
Scale AWS SDK for pandas workloads with AWS Glue for Ray
September 2023: This post was reviewed and updated with a new dataset and related code blocks and images.
AWS SDK for pandas is an open-source library that extends the popular Python pandas library, enabling you to connect to AWS data and analytics services using pandas data frames. We’ve seen customers use the library in combination with pandas for both data engineering and AI workloads. Although pandas data frames are simple to use, they have a limitation on the size of data that can be processed. Because pandas is single-threaded, jobs are bounded by the available resources. If the data you need to process is small, this won’t be a problem, and pandas makes analysis and manipulation simple, as well as interactions with many other tools that support machine learning (ML) and visualization. However, as your data size scales, you may run into problems. This can be especially frustrating if you’ve created a promising prototype that can’t be moved to production. In our work with customers, we’ve seen many projects, both in data science and data engineering, that are stuck while they wait for someone to rewrite using a big data framework such as Apache Spark.
We are excited to announce that AWS SDK for pandas now supports Ray and Modin, enabling you to scale your pandas workflows from a single machine to a multi-node environment, with no code changes. The simplest way to do this is to use AWS Glue for Ray, the new serverless option to run distributed Python code announced at AWS re:Invent 2022. AWS SDK for pandas also supports self-managed Ray on Amazon Elastic Compute Cloud (Amazon EC2).
In this post, we show you how you can use pandas to connect to AWS data and analytics services and manipulate data at scale by running on an AWS Glue for Ray job.
Overview of solution
Ray is a unified framework that enables you to scale AI and Python applications. The goal of the project is to take any Python code that’s written on a laptop and scale the workload on a cluster. This innovative framework opens the door to big data processing to a new audience. Previously, the only way to process large datasets on a cluster was to use tools such as Apache Hadoop, Apache Spark, or Apache Flink. These frameworks require additional skills because they provide their own programming model and often require languages such as Scala or Java to fully take advantage of the advanced capabilities. With Ray, you can just use Python to parallelize your code with few modifications.
Although Ray opens the door to big data processing, it’s not enough on its own to distribute pandas-specific methods. That task falls to Modin, a drop-in replacement of pandas, optimized to run in a distributed environment, such as Ray. Modin has the same API as pandas, so you can keep your code the same, but it parallelizes workloads to improve performance.
With today’s announcement, AWS SDK for pandas customers can use both Ray and Modin for their workloads. You have the option of loading data into Modin data frames, instead of regular pandas data frames. By configuring the library to use Ray and Modin, your existing data processing scripts can distribute operations end-to-end, with no code changes. AWS SDK for pandas takes care of parallelizing the read and write operations for your files across the compute cluster.
To use this feature, you can install the release candidate version of awswrangler with the ray and modin extras:
The following diagram shows what is happening when you run code that uses AWS SDK for pandas to read data from Amazon Simple Storage Service (Amazon S3) into a Modin data frame, perform a filtering operation, and write the data back to Amazon S3, using a multi-node cluster.
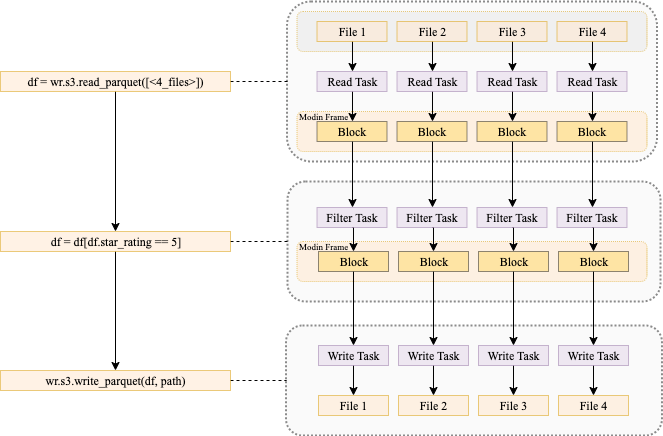
In the first phase, each node reads one or more input files and stores them in memory as blocks. During this phase, the head node builds a mapping reference that tracks the location of each block on the worker nodes. In the second phase, a filter operation is submitted to each node, creating a subset of the data. Finally, each worker node writes its blocks to Amazon S3.
It’s important to note that certain data frame operations (for example groupby or join) may result in the data being shuffled across nodes. Shuffling will also happen if you do partitioned or bucketed writes. This tends to slow down the job because data needs to move between nodes.
If you want to create your own Ray cluster on Amazon EC2, refer to the tutorial Distributing Calls on Ray Remote Cluster. The rest of this post shows you how to run AWS SDK for pandas and Modin on an AWS Glue with Ray job.
Use AWS Glue for Ray
Because AWS Glue for Ray is a fully managed environment, it’s a simple way to run jobs. You don’t need to worry about cluster management and the job auto scales with your workload. To get started, complete the following steps:
- Choose Launch Stack to provision an AWS CloudFormation stack in your AWS account:
 The stack takes about 3 minutes to complete. You can verify that everything was successfully deployed by checking that the CloudFormation stack shows the status
The stack takes about 3 minutes to complete. You can verify that everything was successfully deployed by checking that the CloudFormation stack shows the status CREATE_COMPLETE.
- Navigate to AWS Glue Studio to find an AWS Glue job named
GlueRayJobwith the following script.

- On the Job details tab, scroll down and choose Advanced Properties.
Under Job Parameters, AWS SDK for pandas is specified as an additional Python module to install, along with Modin as an extra dependency.

- Choose Run to start the job and navigate to the Runs tab to monitor progress.
Here, we break down the script and show you what happens at each stage when we run this code on AWS Glue with Ray.
First, we import the library and then read New York City Taxi and Limousine Commission (TLC) Trip Record Datain Parquet format from Amazon S3 and load it into a distributed Modin data frame:
AWS SDK for pandas detects if the runtime supports Ray, and automatically initializes a Ray cluster with the default parameters. In this case, because we’re running on AWS Glue with Ray, AWS SDK for pandas automatically uses the Ray cluster with no extra configuration needed. Advanced users can override this process, however, by starting the Ray runtime before the import command.
Simple data transformations on the data frame are applied next. Modin data frames implement the same interface as pandas data frames, allowing you to perform familiar pandas operations at scale. First, we drop the vendor_id column, then we filter for a subset of the trips that are over 1 mile distance:
The data is written back to Amazon S3 in Parquet format, partitioned by passenger_count and payment_type. The dataset=True argument ensures that an associated Hive table is also created in the AWS Glue metadata catalog:
Finally, a query is run in Amazon Athena, and the S3 objects resulting from this operation are read in parallel into a Modin data frame:
The Amazon CloudWatch logs of the job provide insights into the performance achieved from reading blocks in parallel in a multi-node Ray cluster.

For simplicity, this example showcased Amazon S3 and Athena APIs only, but AWS SDK for pandas supports other services, including Amazon Timestream and Amazon Redshift.
For a full list of the APIs that support distribution, refer to Supported APIs.
Clean up AWS resources
To prevent unwanted charges to your AWS account, you can delete the AWS resources that you used for this example:
- On the Amazon S3 console, empty data from both buckets with prefix
glue-ray-.
- On the AWS CloudFormation console, delete the
SDKPandasOnGlueRaystack.
The resources created as part of the stack are automatically deleted with it.
Conclusion
In this post, we demonstrated how you can run your workloads at scale using AWS SDK for pandas. When used in combination with AWS Glue with Ray, this gives you access to a fully managed environment to distribute your Python scripts. We hope this solution can help with migrating your existing pandas jobs to achieve higher performance and speedups across multiple data stores on AWS.
For more examples, check out the tutorials in the AWS SDK for pandas documentation.
About the Authors
 Abdel Jaidi is a Senior Cloud Engineer for AWS Professional Services. He works on open-source projects focused on AWS Data & Analytics services. In his spare time, he enjoys playing tennis and hiking.
Abdel Jaidi is a Senior Cloud Engineer for AWS Professional Services. He works on open-source projects focused on AWS Data & Analytics services. In his spare time, he enjoys playing tennis and hiking.
 Anton Kukushkin is a Data Engineer for AWS Professional Services based in London, United Kingdom. He works with AWS customers, helping them build and scale their data and analytics.
Anton Kukushkin is a Data Engineer for AWS Professional Services based in London, United Kingdom. He works with AWS customers, helping them build and scale their data and analytics.
 Leon Luttenberger is a Data Engineer for AWS Professional Services based in Austin, Texas. He works on AWS open-source solutions that help our customers analyze their data at scale.
Leon Luttenberger is a Data Engineer for AWS Professional Services based in Austin, Texas. He works on AWS open-source solutions that help our customers analyze their data at scale.
 Lucas Hanson is Senior Cloud Engineer for AWS Professional Services. He focuses on helping customers with infrastructure management and DevOps processes for data management solutions. Outside of work, he enjoys music production and practicing yoga.
Lucas Hanson is Senior Cloud Engineer for AWS Professional Services. He focuses on helping customers with infrastructure management and DevOps processes for data management solutions. Outside of work, he enjoys music production and practicing yoga.