AWS Big Data Blog
How 3M Health Information Systems built a healthcare data reporting tool with Amazon Redshift
 3M Health Information Systems (HIS), a business of 3M Health Care, in their own words: 3m Health Information Systems works with providers, payers, and government agencies to anticipate and navigate a changing healthcare landscape. 3M provides healthcare performance measurement and management solutions, analysis and strategic services that help clients move from volume to value-based health care, resulting in millions of dollars in savings, improved provider performance and higher quality care. 3M’s innovative software is designed to raise the bar for computer-assisted coding, clinical documentation improvement, performance monitoring, quality outcomes reporting, and terminology management.
3M Health Information Systems (HIS), a business of 3M Health Care, in their own words: 3m Health Information Systems works with providers, payers, and government agencies to anticipate and navigate a changing healthcare landscape. 3M provides healthcare performance measurement and management solutions, analysis and strategic services that help clients move from volume to value-based health care, resulting in millions of dollars in savings, improved provider performance and higher quality care. 3M’s innovative software is designed to raise the bar for computer-assisted coding, clinical documentation improvement, performance monitoring, quality outcomes reporting, and terminology management.
There was an ongoing initiative at 3M HIS to migrate applications installed on-premises or on other cloud hosting providers to Amazon Web Services (AWS). 3M HIS began migration to AWS to take advantage of compute, storage and network elasticity. We wanted to build on a solid foundation that would help us focus more of our efforts on delivering customer value while also scaling to support business growth that we expected over the next several years. 3M HIS was already processing healthcare data for many customers which is complex in nature, requiring a lot of complex transformations to get data into a format useful for analytics or machine learning.
After reviewing many solutions, 3M HIS chose Amazon Redshift as the appropriate data warehouse solution. We concluded Amazon Redshift met our needs; a fast, fully managed, petabyte-scale data warehouse solution that uses columnar storage to minimize I/O, provides high data compression rates, and offers fast performance. We quickly spun up a cluster in our development environment, built out the dimensional model, loaded data, and made it available to perform benchmarking and testing of the user data. An extract, transform, load (ETL) tool was used to process and load the data from various sources into Amazon Redshift.
3M legacy implementation
3M HIS processes a large volume of data through this data warehouse. We ingest healthcare data from clients, representing millions of procedure codes, diagnosis codes and all the associated meta data for each of those codes. The legacy process loaded this data into the data warehouse once every two weeks.
For reporting, we published 25 static reports and 6 static HTML reports for over 1000 customers every week. To provide business intelligence reports, we built analytical cubes on a legacy relational database and provided reports from those cubes.
With the ever-increasing amounts of data to be processed meeting the SLA’s was a challenge. It was time to replace our SQL database with a modern architecture and tooling that would auto scale based on the data to be processed and be performant.
How 3M modernized the data warehouse with Amazon Redshift
When choosing a new solution, first we had to ensure that we were able to load data in near real-time. Second, we had to ensure that the solution was scalable, because the amount of data stored in the data warehouse would be 10x larger as compared to the existing solution. Third, the solution needed to be able to provide reports for massive queries in reasonable amount of time without impacting the ETL processing that would be running 24/7. Last, we needed a cost-effective data warehouse that could integrate with other analytics services that were part of the overall solution.
We evaluated data warehouses such as Amazon Redshift and Snowflake. We chose Amazon Redshift because it fulfilled the preceding criteria and aligned with our preference for native AWS managed services. But also, we did so because Amazon Redshift would be a solution for the future that could keep pace with the growth of the business in an economically sustainable way.
To build the reporting tool, we migrated our multi-terabyte data warehouse to Amazon Redshift. The data was processed through the ETL workflow into an Amazon S3 bucket and then bulk-copied into Amazon Redshift. The GitHub repository provided by AWS, a collection of scripts and utilities, helped us set up the cluster and get the best performance possible from Amazon Redshift.
Top lessons that we learned during the implementation
During the initial development, we encountered challenges loading the data into the Amazon Redshift tables because we were trying to load the data from an Amazon RDS staging instance into Amazon Redshift. After some research, we identified that a bulk load from Amazon S3 bucket was the best practice to get large amounts of data loaded into the Amazon Redshift tables.
The second challenge was that the Amazon Redshift VACUUM and ANALYZE operations were holding up our ETL pipeline, because these operations had been baked into the ETL process. We performed frequent data loads into the Amazon Redshift tables and a lot of DELETE operations as part of the ETL processing. These two concerns meant that the VACUUM and ANALYZE operations had to be performed frequently, resulting in the tables being locked for the operations’ duration and conflicting with the ETL process. Triggering the process after all the loads were complete helped eliminate the performance issues we were encountering. VACUUM and ANALYZE have recently been automated, which we expect to prevent such issues arising in the future.
The final challenge was to find a way to use windowing functions which previously resided in the Analysis Services cube layer, whose functionality Amazon Redshift now fulfilled. However, most of the windowing functions that we need are built into Amazon Redshift allowing for an easy transition to port the existing functionality to Amazon Redshift and provide the same results.
During the port, we used Amazon Redshift’s comprehensive best practices guide and tuning techniques. We found these helped us set up the Amazon Redshift cluster for optimal performance.
Flow diagram of the new implementation
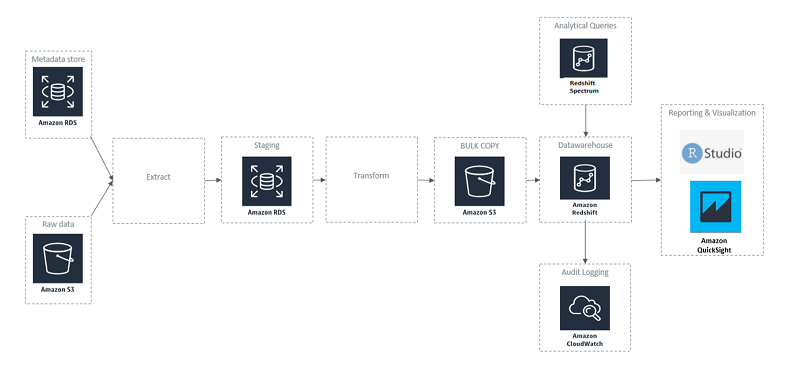
Benefits of the updated implementation
With the legacy solution, our implementation had grown complex, we found it difficult to support the growing volume of new data we needed to incorporate into the database and then report on in near real-time. Reports executing on the data were slowly drifting away from the initial SLA requirements. With Amazon Redshift, we’re working to solve those problems with less need for manual maintenance and care and feeding of the solution. First, it has the potential to allow us to store a larger quantity of data for a longer time. Second, adding nodes to the cluster when needed is simple and we can do it in minutes with the Elastic Resize feature. Likewise, we can scale back nodes when cost sensitivity is an issue. Third, Amazon Redshift also gives better support for computing analytics over large sets of grouped data than our previous solution. Often, we want to look at how recent data compares to historical data. In some cases, we want more than a year or two of historical data to rule out seasonality and we have found that Amazon Redshift is a more scalable solution for this type of operation.
Conclusion
At 3M HIS, we’re transforming health care from a system that treats disease to one that improves health and wellness with accurate health and clinical information from the start. 3M’s nearly 40 years of clinical knowledge, from data management and nosology to reimbursement and risk adjustment, opens the door for our providers and payers clients to find innovative solutions that improve outcomes across the continuum of care. We help our clients ensure accurate and compliant reimbursement, as well as leverage 3M’s analytical capabilities, powered by AWS, to improve health system and health plan performance while lowering costs.
The content and opinions in this post are those of the third-party author and AWS is not responsible for the content or accuracy of this post.
About the Author
 Dhanraj Shriyan is an Enterprise Data Architect at 3M Health Information Systems with a Masters in Predictive Analytics from Northwestern University, Chicago. He loves helping customers in exploring their data, and providing valuable insights and implementing a scalable solution, using the right database technology based on their needs. He has several years of experience in building large scale data warehouse business intelligence solutions in-cloud as well as on-prem. Currently, Dhanraj is exploring graph technologies and Lake Formation services in AWS.
Dhanraj Shriyan is an Enterprise Data Architect at 3M Health Information Systems with a Masters in Predictive Analytics from Northwestern University, Chicago. He loves helping customers in exploring their data, and providing valuable insights and implementing a scalable solution, using the right database technology based on their needs. He has several years of experience in building large scale data warehouse business intelligence solutions in-cloud as well as on-prem. Currently, Dhanraj is exploring graph technologies and Lake Formation services in AWS.