AWS Compute Blog
Amazon EC2 DL1 instances Deep Dive
This post is written by Amr Ragab, Principal Solutions Architect, Amazon EC2.
AWS is excited to announce that the new Amazon Elastic Compute Cloud (Amazon EC2) DL1 instances are now generally available in US-East (N. Virginia) and US-West (Oregon). DL1 provides up to 40% better price performance for training deep learning models as compared to current generation GPU-based EC2 instances. The dl1.24xlarge instance type features eight Intel-Habana Gaudi accelerators, which are custom-built to train deep learning models. Each Gaudi accelerator has 32 GB of high bandwidth memory (HBM2) and a peer-to-peer bidirectional bandwidth of 100 Gbps RoCE, for a total bidirectional interconnect bandwidth of 700 Gbps per card. Further instance specifications are as follows:
| Instance Size | vCPU | Instance Memory (GiB) | Gaudi Accelerators | Network Bandwidth (Gbps) | Total Accelerator Interconnect (Gbs) | Local Instance Storage | EBS Bandwidth (Gbps) |
| d1.24xlarge | 96 | 768 | 8 | 4×100 Gbps | 700 | 4x1TB NVMe | 19 |
Instance Architecture

As the preceding instance architecture indicates, pairs of Gaudi accelerators (e.g., Gaudi0 and Gaudi1) are attached directly through a PCIe Gen3x16 link. Additionally, peer-to-peer networking via 100 Gbps RoCEv2 links – with seven active links per card – provides a torus configuration with a total of 700 Gbps of interconnect bandwidth per card. This topology is a separate interconnect outside of the two NUMA domains. Furthermore, the instance supports four EFA ENIs and 4x1TB of local NVMe SSD storage. We will provide a peer-direct driver over EFA, which will let you utilize high throughput, low latency peer-direct networking between accelerators across multiple instances to efficiently scale multi-node distributed training workloads.
Quick Start
Quickly get started with DL1 and SynapseAI SDK through with the following options:
1) Habana Deep Learning AMIs provided by AWS.
2) AWS Marketplace AMIs provided by Habana.
3) Using Packer to build a custom Amazon Machine Images (AMI) provided by this GitHub repo. This repo also provides build scripts to create Amazon Elastic Container Service (Amazon ECS) and Amazon Elastic Kubernetes Service (Amazon EKS) AMIs.
After selecting an AMI, launch a dl1.24xlarge instance in either us-east-1 or us-west-2. To help identify in which availability zone(s) dl1.24xlarge is available, run the following command:
aws ec2 describe-instance-type-offerings \
--location-type availability-zone \
--filters Name=instance-type,Values=dl1.24xlarge \
--region us-west-2 \
--output tableOnce launched, you can connect to the instance over SSH (with the correct security group attached).
Habana Collectives Communication Library (HCL/HCCL)
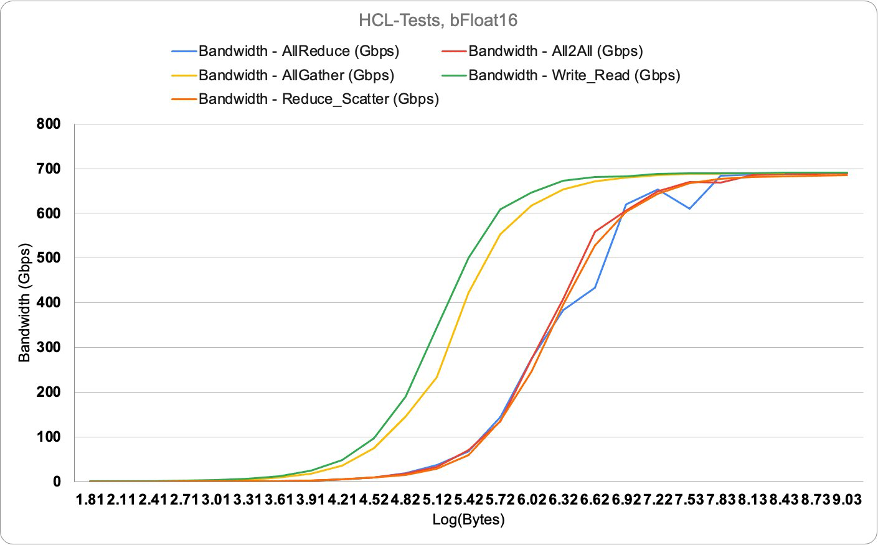
As part of the Habana SynapseAI SDK, Habana Gaudi’s use the HCCL library for handling the collectives between HPUs. Get more information on HCCL here. On DL1 through the HCL-tests, we can confirm close to 700 Gbps (689 Gbps) per card for the collectives tested as follows.
You can confirm these tests by cloning the github repo here.
Amazon EKS Quick Start
Support for DL1 on Amazon EKS is available today with Amazon EKS versions > 1.19. The following is a quick start to get up and running quickly with DL1.
The following dependencies will be needed:
eksctl – You need version 0.70.0+ of eksctl.
kubectl – You use Kubernetes version 1.20 in this post.
Create EKS cluster:
eksctl create cluster --region us-east-1 --without-nodegroup \
--vpc-public-subnets subnet-037d8e430963c2d3e,subnet-0abe898359a7d43e9Nodegroup configuration – save the following codeblock to a file called dl1-managed-ng.yaml. Replace the AMI ID in the code block with the AMI created earlier.
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata:
name: fabulous-rainbow-1635807811
region: us-west-2
vpc:
id: vpc-34f1894c
subnets:
public:
endpoint-one:
id: subnet-4532e73d
endpoint-two:
id: subnet-8f8b7dc5
managedNodeGroups:
- name: dl1-ng-1d
instanceType: dl1.24xlarge
volumeSize: 200
instancePrefix: dl1-ng-1d-worker
ami: ami-072c632cbbc2255b3
iam:
withAddonPolicies:
imageBuilder: true
autoScaler: true
ebs: true
fsx: true
cloudWatch: true
ssh:
allow: true
publicKeyName: amrragab-aws
subnets:
- endpoint-one
minSize: 1
desiredCapacity: 1
maxSize: 4
overrideBootstrapCommand: |
#!/bin/bash
/etc/eks/bootstrap.sh fabulous-rainbow-1635807811
Create the managed nodegroup with the following command:
eksctl create nodegroup -f dl1-managed-ng.yamlOnce the nodegroup has been completed, you must apply the habana-k8s-device-plugin
kubectl create -f https://vault.habana.ai/artifactory/docker-k8s-device-plugin/habana-k8s-device-plugin.yamlOnce completed, you should see the Gaudi devices as an allocatable resource in your EKS
cluster, presenting 8 Gaudi accelerators per DL1 node in the cluster.
Allocatable:
attachable-volumes-aws-ebs: 39
cpu: 95690m
ephemeral-storage: 192188443124
habana.ai/gaudi: 8
hugepages-1Gi: 0
hugepages-2Mi: 30000Mi
memory: 753055132Ki
pods: 15Example Distributed Machine Learning (ML) Workloads
The following tables are examples of Mixed Precision/FP32 training results comparing DL1 to the common GPU instances used for ML training.
Model: ResNet50
Framework: TensorFlow 2
Dataset: Imagenet2012
GitHub: https://github.com/HabanaAI/Model-
References/tree/master/TensorFlow/computer_vision/Resnets/resnet_keras
| Instance Type | Batch Size
|
Mixed Precision Training Throughput (images/sec) |
| 8x Gaudi – 32 GB (dl1.24xlarge) | 256 | 13036 |
| 8x A100 – 40 GB (p4d.24xlarge) | 256 | 17921 |
| 8x V100 – 32 GB (p3dn.24xlarge) | 256 | 9685 |
| 8x V100 – 16GB (p3.16xlarge) | 256 | 8945 |
Model: Bert Large – Pretraining
Framework: Pytorch 1.9
Dataset: Wikipedia/BooksCorpus
GitHub: https://github.com/HabanaAI/Model-References/tree/master/PyTorch/nlp/bert
| Instance Type | Batch Size
@128 Sequence Length |
Mixed Precision Training Throughput (seq/sec) |
| 8x Gaudi – 32 GB (dl1.24xlarge) | 256 | 1318 |
| 8x A100 – 40 GB (p4d.24xlarge) | 8192 | 2979 |
| 8x V100 – 32 GB (p3dn.24xlarge) | 8192 | 1458 |
| 8x V100 – 16GB (p3.16xlarge) | 8192 | 1013 |
You can find a more comprehensive list of ML models supported with performance data here. Support for containers with TensorFlow and Pytorch are also available. Furthermore, you can stay up-to-date with the operator support for TensorFlow and Pytorch.
CONCLUSION
We are excited to innovate on behalf of our customers and provide a diverse choice in ML accelerators with DL1 instances. The DL1 instances powered by Gaudi accelerators can provide up to 40% better price performance for training deep learning models as compared to current generation GPU-based EC2 instances. DL1 instances use the Habana SynapseAI SDK with framework support in Pytorch and TensorFlow. Additional future support for EFA with peer direct HPUs across nodes will also be supported. Now it’s time to go power up your ML workloads with Amazon EC2 DL1 instances.