AWS Compute Blog
Category: Serverless

Build a custom Java runtime for AWS Lambda
This post is written by Christian Müller, Principal AWS Solutions Architect and Maximilian Schellhorn, AWS Solutions Architect When running applications on AWS Lambda, you have the option to use either one of the managed runtime versions that AWS provides or bring your own custom runtime. The following blog post provides a walkthrough of how you […]

Handling Lambda functions idempotency with AWS Lambda Powertools
Idempotency is a critical piece of serverless architectures and can be difficult to implement. If not done correctly, it can lead to inconsistent data and other issues. This post shows how you can use Lambda Powertools to make Lambda functions idempotent and ensure that critical transactions are handled only once.

Working with events and the Amazon EventBridge schema registry
Event-driven architecture, at its core, is driven by producers creating events and subscribers being made aware of those events and acting upon them. An event is a data representation of something that happened elsewhere in the application or from an outside producer. When building event-driven applications, it is critical to determine what events exist in […]
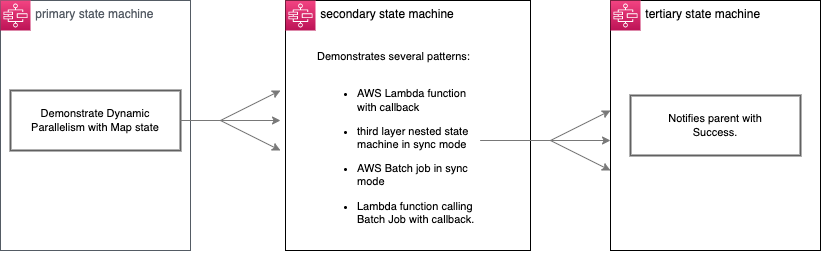
Orchestrating high performance computing with AWS Step Functions and AWS Batch
This blog post describes several challenges common to orchestrating HPC workloads. I describe how Step Functions with AWS Batch can solve many of these challenges. I provide a project that contains several sample patterns and show how to deploy and test this in your account.
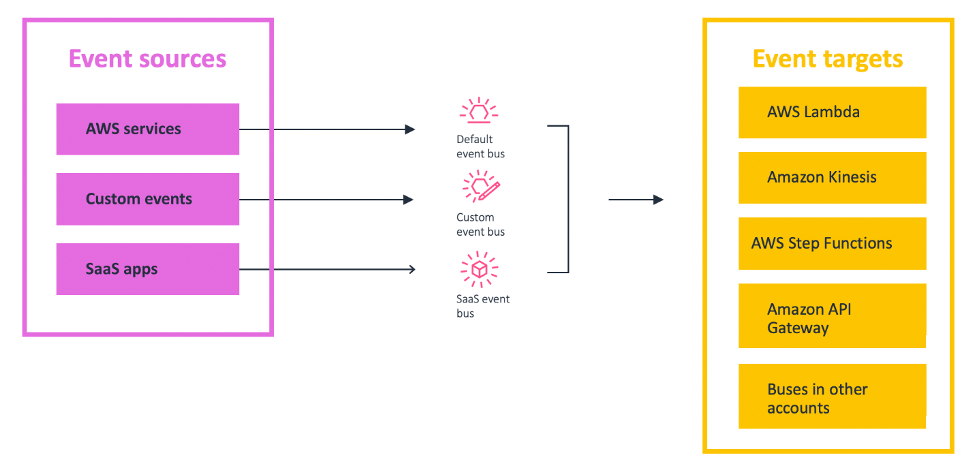
Building an event-driven application with Amazon EventBridge
In event-driven architecture, services interact with each other through events. An event is something that happened in your application (for example, an item was put into a cart, a new order was placed). Events are JSON objects that tell you information about something that happened in your application. In event-driven architecture, each component of the […]

Introducing global endpoints for Amazon EventBridge
This blog shows how to create an EventBridge global endpoint to improve the availability and reliability of event ingestion of event-driven applications. This example shows how to use the PutEvents in the Python AWS SDK to publish events to a global endpoint.
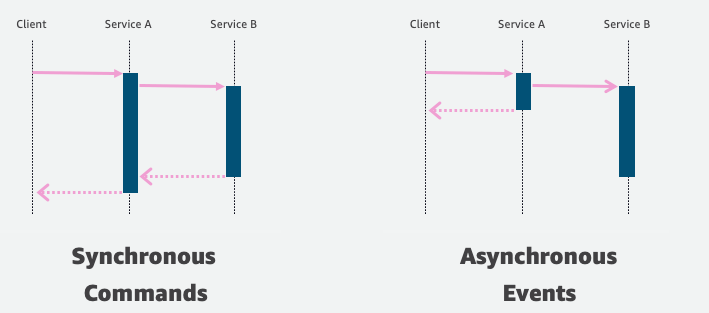
Getting started with event-driven architecture
In modern application development, event-driven architecture is becoming more prominent because it can make building applications in the cloud easier. Event-driven architecture can allow you to decouple your services, which increases developer velocity, and can make it easier for you to debug applications. It also can help remove the bottleneck that occurs when features expand […]
ICYMI: Serverless Q1 2022
Welcome to the 17th edition of the AWS Serverless ICYMI (in case you missed it) quarterly recap. Every quarter, we share all the most recent product launches, feature enhancements, blog posts, webinars, Twitch live streams, and other interesting things that you might have missed! In case you missed our last ICYMI, check out what happened […]
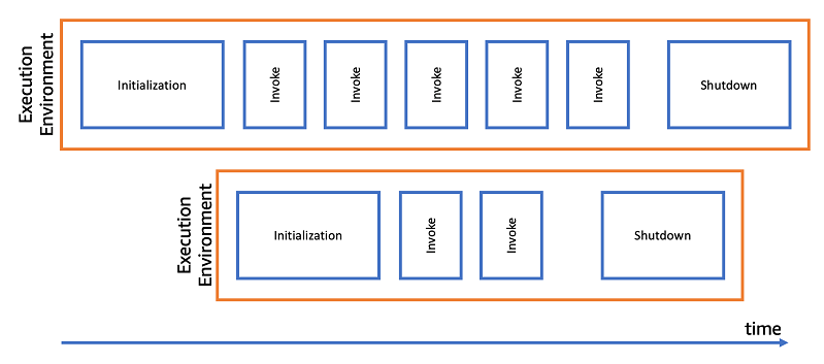
Optimizing AWS Lambda function performance for Java
This post is written by Mark Sailes, Senior Specialist Solutions Architect. This blog post shows how to optimize the performance of AWS Lambda functions written in Java, without altering any of the function code. It shows how Java virtual machine (JVM) settings affect the startup time and performance. You also learn how you can benchmark […]

Using AWS Step Functions and Amazon DynamoDB for business rules orchestration
In this post, you learned how to leverage an orchestration framework using Step Functions, Lambda, DynamoDB, and API Gateway to build an API backed by an open-source Drools rules engine, running on a container. Try this solution for your cloud native business rules orchestration use-case.