AWS Compute Blog
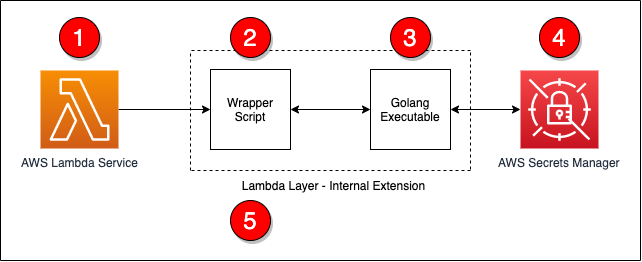
Creating AWS Lambda environment variables from AWS Secrets Manager
This solution provides a way to convert information from Secrets Manager into Lambda environment variables. By following this approach, you can centralize the management of information through Secrets Manager, instead of at the function level.
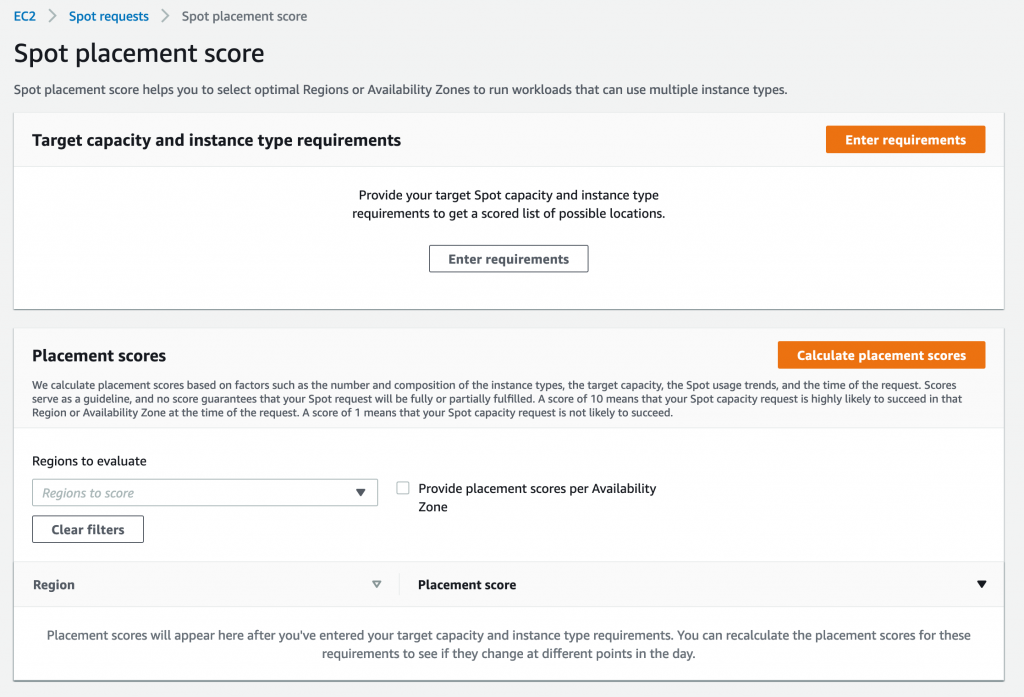
Identifying optimal locations for flexible workloads with Spot placement score
This post is written by Jessie Xie, Solutions Architect for EC2 Spot, and Peter Manastyrny, Senior Product Manager for EC2 Auto Scaling and EC2 Fleet. Amazon EC2 Spot Instances let you run flexible, fault-tolerant, or stateless applications in the AWS Cloud at up to a 90% discount from On-Demand prices. Since we introduced Spot Instances […]

Accelerating serverless development with AWS SAM Accelerate
Building a serverless application changes the way developers think about testing their code. Previously, developers would emulate the complete infrastructure locally and only commit code ready for testing. However, with serverless, local emulation can be more complex. In this post, I show you how to bypass most local emulation by testing serverless applications in the […]
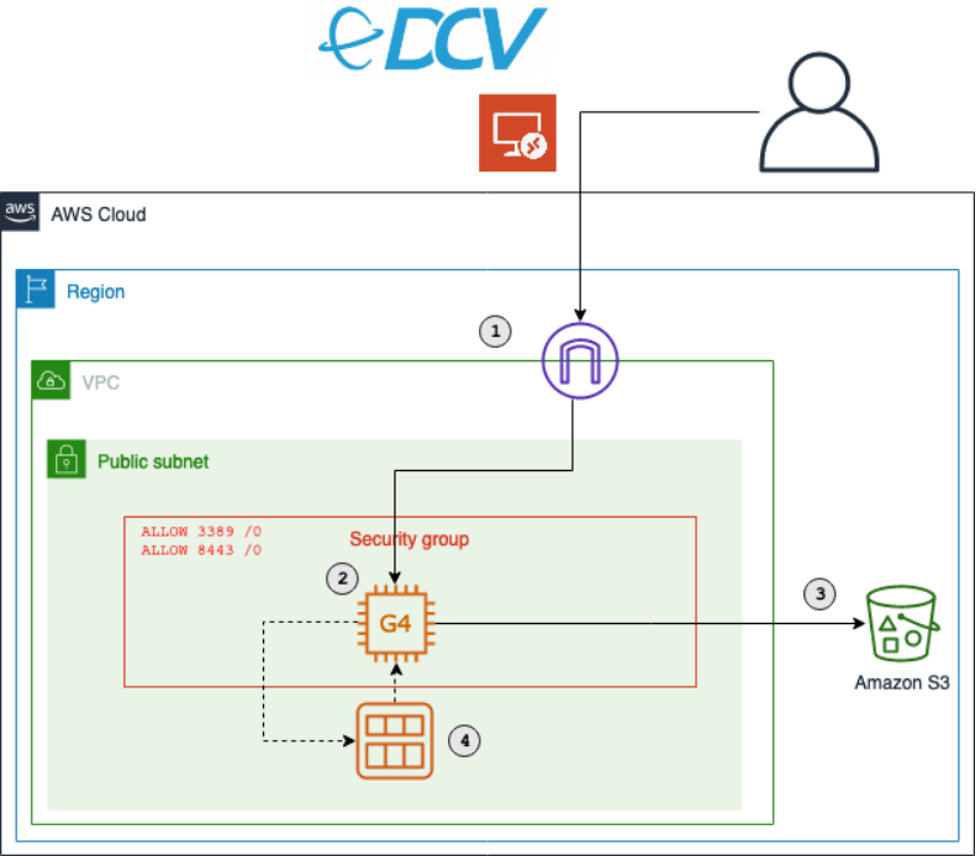
Use Amazon EC2 for cost-efficient cloud gaming with pay-as-you-go pricing
July 2025c2: This post was reviewed for accuracy. Cloud gaming enables access to high-performance gaming without upfront hardware investment, using pay-as-you-go pricing instead. Cloud gaming platforms such as Amazon Luna are an entryway, but users are limited to the games available on the service. Furthermore, many users also prefer to own their games, or they […]
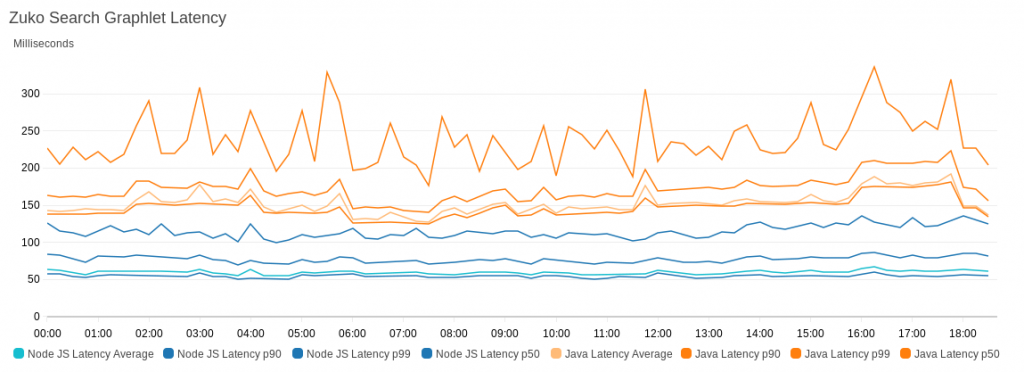
Monitoring and tuning federated GraphQL performance on AWS Lambda
There are multiple factors to consider when tuning a federated GQL system. You must be aware of trade-offs when deciding on factors like the runtime environment of Lambda functions. An extensive testing strategy can help you scale systems and narrow down issues quickly. Well-defined testing can also keep pipelines clean of false-positive blockages.
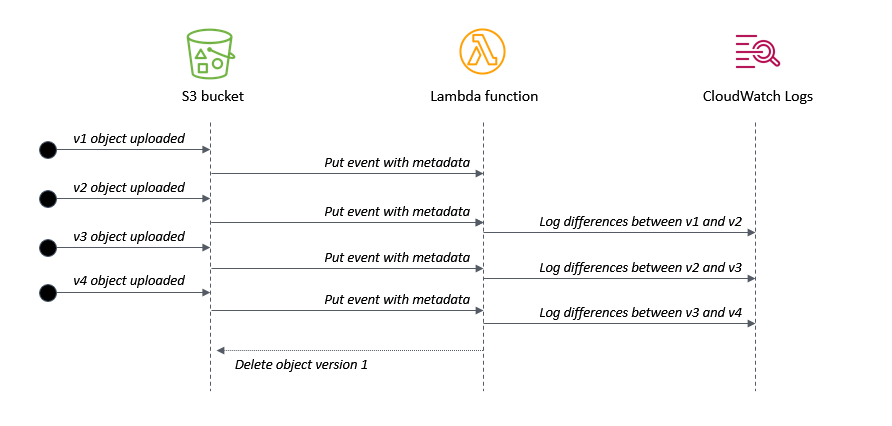
Building a difference checker with Amazon S3 and AWS Lambda
This blog post shows how to create a scalable difference checking tool for objects stored in S3 buckets. The Lambda function is invoked when S3 writes new versions of an object to the bucket. This example also shows how to remove earlier versions of object and define a set number of versions to retain.
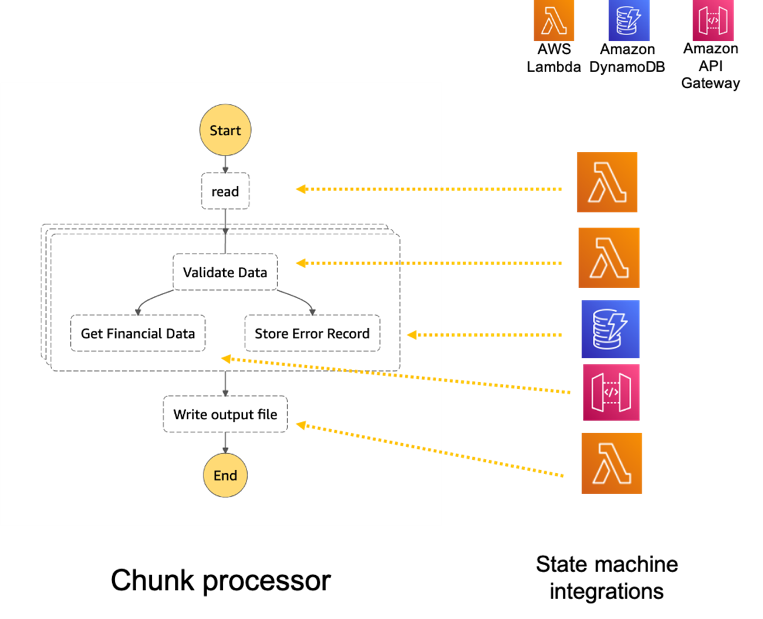
Creating AWS Serverless batch processing architectures
This blog post shows how to use Step Functions’ features and integrations to orchestrate a batch processing solution. You use two Steps Functions workflows to implement batch processing, with one workflow splitting the original file and a second workflow processing each chunk file.

Amazon EC2 Auto Scaling will no longer add support for new EC2 features to Launch Configurations
This post is written by Scott Horsfield, Principal Solutions Architect, EC2 Scalability and Surabhi Agarwal, Sr. Product Manager, EC2. In 2010, AWS released launch configurations as a way to define the parameters of instances launched by EC2 Auto Scaling groups. In 2017, AWS released launch templates, the successor of launch configurations, as a way to streamline […]
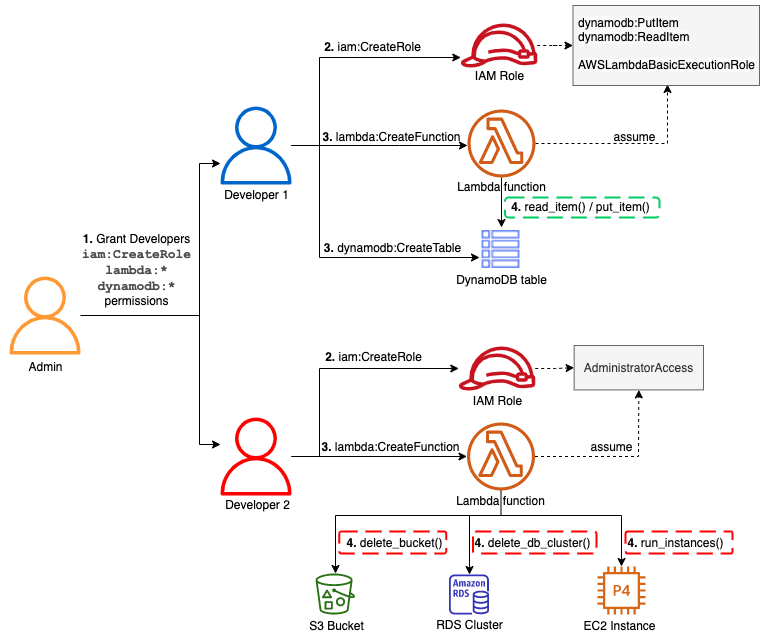
Operating serverless at scale: Keeping control of resources – Part 3
This post describes guardrails that you can set up in your accounts or across the organization to keep control over deployed resources. These guardrails can be more or less restrictive according to your requirements.
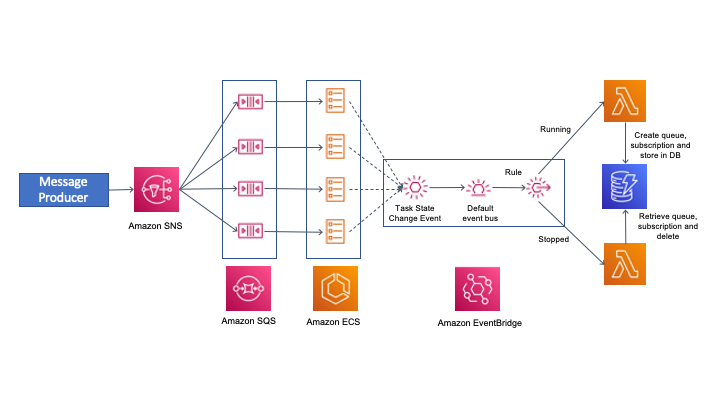
Building dynamic Amazon SNS subscriptions for auto scaling container workloads
This blog shows an event driven approach to handling dynamic SNS subscription requirements. It relies on the ECS service events to trigger appropriate Lambda functions. These create the subscription queue, subscribe it to a topic, and delete it once the container instance is terminated.