Containers
Architecture evolution: From zero to future-proof architecture at home24
This blog was co-authored by Aurelijus Banelis, Senior Software Engineer at home24
Introduction
Home24 is a leading pure-play home & living e-commerce platform in continental Europe and Brazil. It has third-party and private-label assortments combined with a tailored user experience — and that is a good foundation for a sustainable technology business. Aurelijus is proud to be one of the employee who’s witnessed the entire home24 AWS journey: from the times of scalability limitations in the data center to Black Friday’s proven agile cloud architecture.
Spending more on marketing, on-boarding additional customers and processing a higher number of orders requires more hardware to meet the demand. In addition, hiring developers and reacting to the market in a timely manner is a challenging combination. It’s a journey of repeatedly overcoming new cultural and technological limitations.
In order to focus on our next goal, we first needed to overcome existing problems. Higher goals meant greater challenges. Faced with the next level of constraints, we had to find an alternative to completely stopping, rewriting, and reorganising everything at once. To ensure gradual migration & modernization, we decided to:
- Keep the business running with all the complex logic that’s slow or risky to rewrite
- Develop a long-term vision of the future-proof architecture to avoid being in an unmaintainable system
- Inspect and adapt – Plans are useful, but our environment changes so quickly that we’ve had to adapt regularly to ensure uninterrupted operations.
Designing a future-proof architecture is a crucial step in preparing for the unknown. To achieve this, we leveraged various levels of abstraction, starting with hardware abstraction through virtual machines and EC2 instances. We then moved to containerization using containers and domain abstraction through microservices. This allowed us to adopt a developer-first approach, ensuring seamless integration and compatibility. The implementation of AWS managed services, specifically Elastic Container Service (Amazon ECS) and AWS Fargate, proved to be the missing link in our quest for a durable architecture. By adopting this microservice architecture using ECS/Fargate, we have positioned ourselves to meet the growing demands of our business in the long term.
When reading this post, We hope to encourage you to rethink your own technical architecture alongside your company culture and business. Let’s dive into home24’s journey…
Solution overview
We were tasked to speed up feature development while following best practices and our values:
- Keep deployable units and team decisions as autonomous as possible. We believed in the teams knowing the domain, the best ways to innovate, keep development iterations small, and retained stable cognitive health while the company grows.
- Introduce tools and processes that are simple to follow. We created repeatable yet simple immutable building blocks. This paradigm allowed us to invest more time in tackling unique challenges.
- Keep the critical failures low yet allow changes to core Infrastructure components, in a gradual, controlled Infra-As-Code (IaC) paradigm which also allows a rapid rollback to a last known working state.
Initially, our monolithic architecture with large frontend and backend teams allowed us to enter the market quickly. However, as our business grew, we realized that this architecture was limiting our future expansion. After careful consideration and numerous brainstorming sessions, we developed a reference architecture based on a multiple, decoupled tier-equals-app approach. To achieve proper isolation, we utilized AWS accounts as boundaries for both, the application and its environment (staging and production).
To maximize efficiency and cost-effectiveness, we selected ECS/AWS Fargate as our container engine. We also developed, in-house horizontally scalable proxy applications at the HTTP and GraphQL levels to further decouple our frontend and backend tiers. This allowed us to route requests across microservices intelligently without the need for a service mesh. This new architecture has not only provided us with the necessary scalability and flexibility, but has also allowed us to continue to grow and evolve as our business demands change.
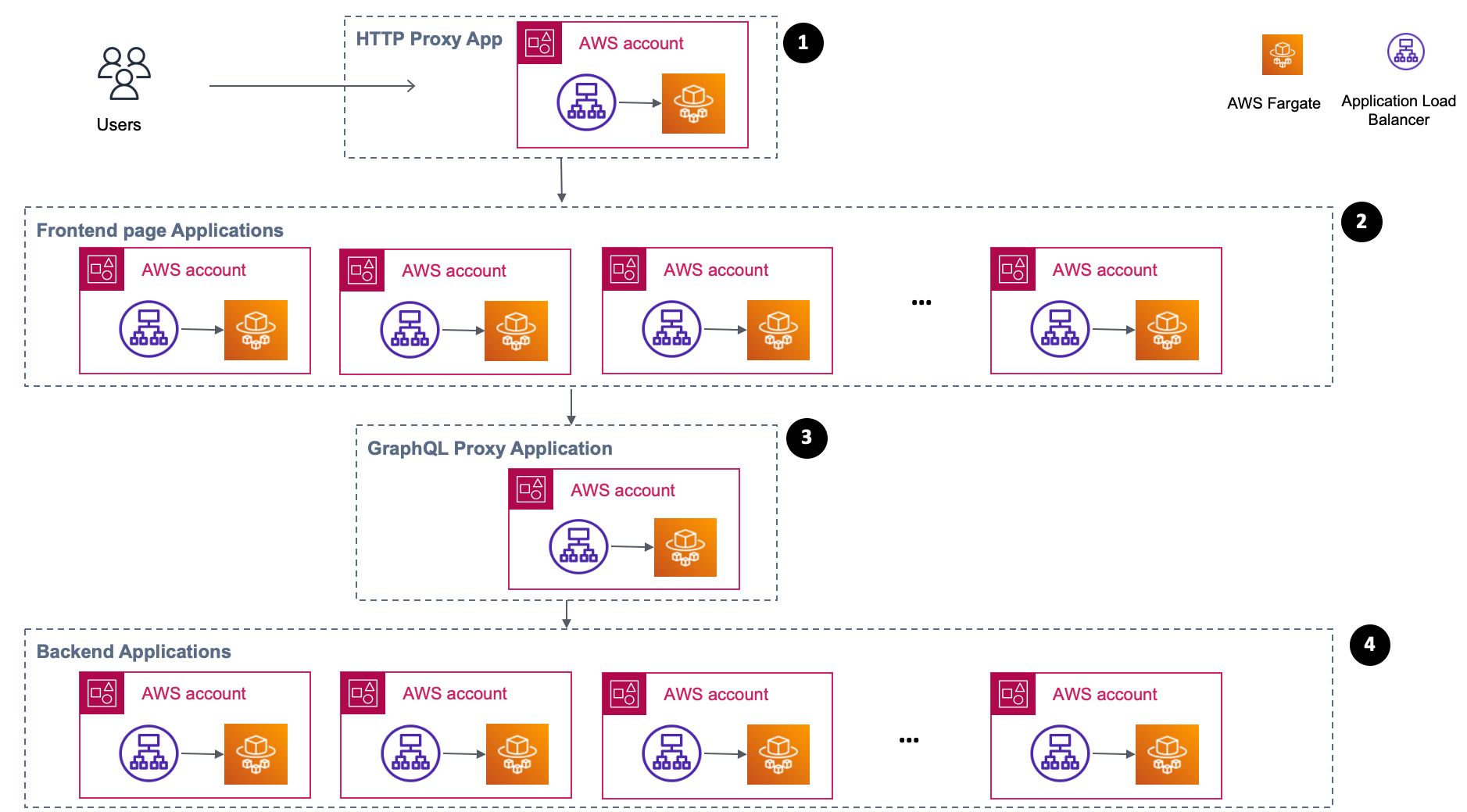
As shown in the previous diagram, we grouped our services into four different application types:
- HTTP proxy app: This service receives 100% of all dynamic shop traffic, but we kept the level of custom logic in this service to a minimum and test coverage to the maximum. The same availability-complexity ratio pattern applies to static traffic served via Content Delivery Network (CDN). As traffic increases, gradual autoscaling handles spikes. This is an ideal place for feature toggles or routing to newly created microservices.
- Fronted page apps (Micro Frontends): These services are stateless and use JavaScript for both the client (i.e., browser) and server rendering. This approach made changes to the end-user faster and easier to develop and test. Micro frontends had independent AWS CloudFormation stacks, which made them appropriate for scheduled auto scaling or keeping other platform parts resilient, for example during Distributed-Denial-of-Service (DDoS) attacks.
- GraphQL proxy app: This stateless service aggregates responses from many downstream microservices or third-party providers. Being a single point to serve traffic from frontend page apps, AJAX, or mobile requests. The GraphQL proxy app is an ideal place for an advanced cache logic. Business logic is minimal.
- Backend apps: these are usually stateful, optimized for a specific function, and use different AWS Services. In case of anomalies, it was easier to identify, scale, or revert broken versions. For example, undocumented application programming interface (API) contracts were caught early during the release, as we saw latency increase in downstream backend services.
This new architecture demonstrated the following tenets:
- Teams Autonomy each team has its own microservice and AWS Account. An AWS account as an isolation boundary ensured the highest freedom for innovation and limited blast radius in case of mistakes. To optimize costs, we grouped a few staging and testing environments into the same AWS account. We also used shared resources across AWS organizational units, avoiding replication of those assets.
- Simplicity is covered by using the AWS CloudFormation template as a deterministic deployable unit. We had both the Docker image (i.e., software code) path and infrastructure (e.g., alarms, scaling parameters, and secrets) information on the same template. If issues occurred, we could roll back everything to the last known good state in a single click using a template/stack (AWS Cloudformation). This allowed us to easily replicate the whole application. Contract between services was ensured using AWS Load Balancer with a readable DNS name (Route53 record). All of these cloud-native and open-source software (OSS) technologies (e.g., DNS, AWS CloudFormation, Docker, and feature toggles) kept home24 continuously evolving.
- Developer experience, using ECS/Fargate meant that our developers could use their laptops to build, test and deploy the containerized application using in-cloud fully managed CI/CD pipelines and dedicated environment spin up using AWS Cloudformation as the IaC tool.
Journey stages
Home24’s migration to AWS started around 2017, we rewrote & decommissioned the last remaining elements of the old infrastructure in mid-2022. The focus wasn’t on the speed of rewriting everything. Instead, it was about an iterative process of change while growing the business. The evolution took place in five stages.

Datacenter to AWS

While the business logic and requirements were relatively simple, it was quicker to develop using a single codebase. We were ordering new hardware on a yearly basis. To overcome scalability planning limitations, we migrated the e-commerce platform via lift-and-shift to Amazon EC2. At the time, we were already using distributed virtual machines, which helped to achieve the next step: introducing Load Balancers, Auto Scaling Groups, and Amazon Relational Database Service (Amazon RDS) for hosting the database. Increased spending on marketing attracted more visitors, and our architecture was able to handle the load. Like many other employees, Aurelijus didn’t have much AWS knowledge back then.
Monolith to microservices

Having a bigger team maintaining a single code base was slowing everybody down. There was even a joke circulating about the developer shouting from the other side of the room: you broke my build. Simply hiring new employees, without changing anything was no longer an option.
In addition, adding more functionality slowed down overall response time, and we were hitting the limitations of the programming language itself. For example, the e-commerce core was written in PHP programming language, where logic was executed synchronously. Migrating to another programming language meant having an independently deployable service.
We started with a GoLang app to proxy all the traffic. Seeing little to no impact in latency, we continued migrating authentication, search engine optimization (SEO), and 1% A/B tests functionality. The goal was to extract shared functionality, so that other teams could split the code base by domain logic.
GoLang was also the first application where we started to use AWS CloudFormation templates with reusable parts. One of those parts was the Amazon ECS Task definition for the container definition. Our platform team intended to make this example template (i.e., blueprint) mature enough to be shared with other groups.
More teams, more versions
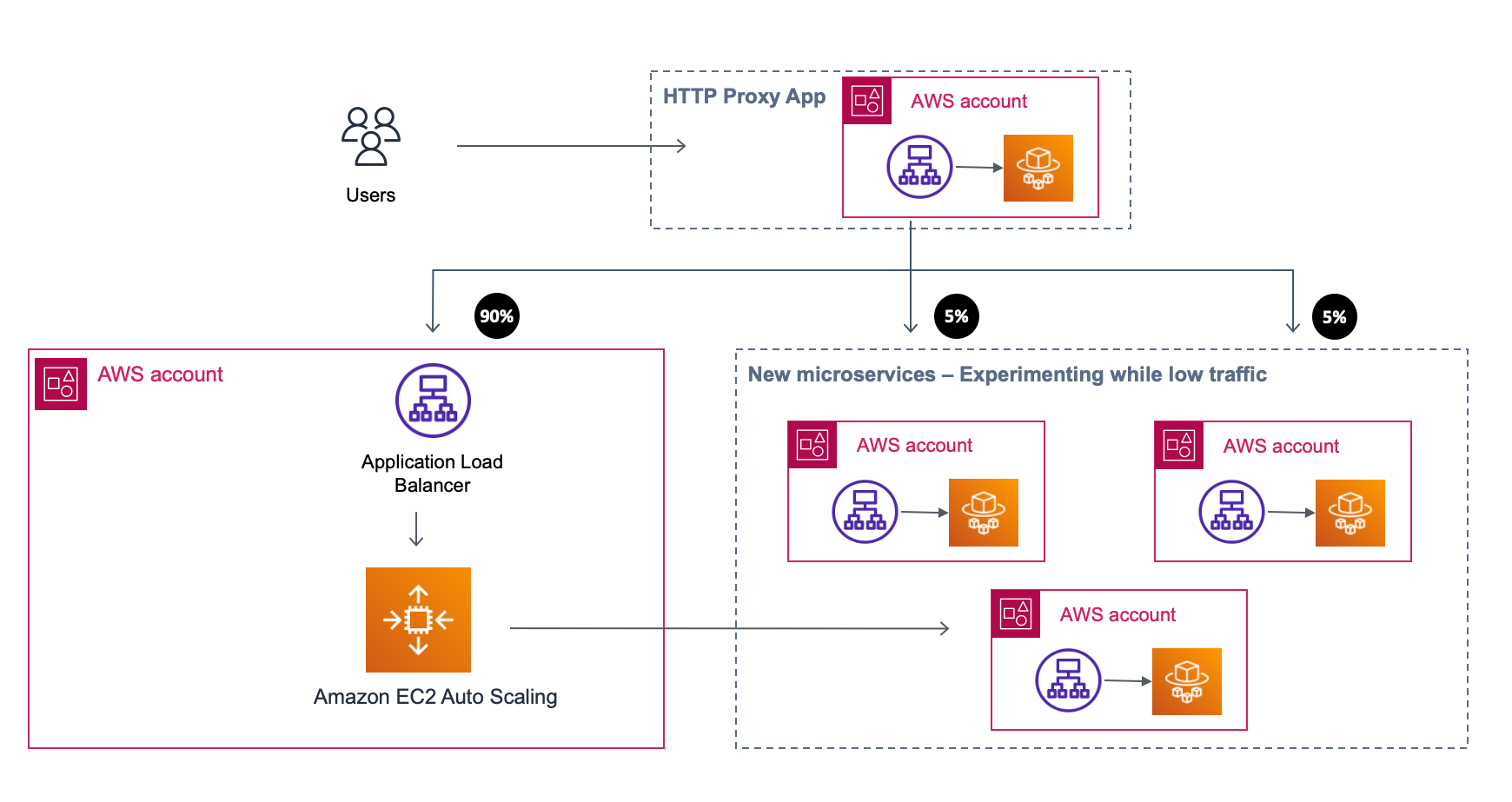
Smaller teams with a smaller codebase and the newest tools were migrating page after page and functionally-after-functionality to the new level of experience. Making changes to the old code base was always slower and more error-prone. Regardless, we needed to work on both compatibility and new functionality streams to keep the business stable and to make well-informed, data-driven decisions.
The level of AWS knowledge in the company gradually increased. AWS announced many new features, and colleagues were adapting blueprint templates to their needs.
Standardization and AWS Fargate
Over time, stack definitions stabilized. As with every year before, the 2021 architecture needed to prove its scalability and high availability during Black Friday. For e-commerce, Black Friday was one of the most critical periods during the year. We planned many marketing activities and pre-ordered products from suppliers. Expecting around double the revenue, the cost of errors would also double. We were advertising to as many customers as possible. A poor customer experience (i.e., latency, service interruptions) or downtime would dramatically impact home24´s reputation as a leader in the e-commerce space.
As described previously, we ended up with an AWS CloudFormation stack per team per service per environment as a deployable unit. These services were usually isolated into an individual AWS account. Each service was derived from the company’s blueprint template. Therefore, each service resulted in an AWS CloudFormation stack with Amazon ECS/AWS Fargate ready to run dockerized applications. Despite those reusable parts, AWS CloudFormation templates also included resources specific to each application (e.g. storage, cache, secrets, etc.)
From application logic, there are four types of services:
- All ingress traffic traverses the HTTP-level proxy application to cover shared authentication, SEO, and A/B testing functionality. Secure Sockets Layer (SSL) is terminated on AWS Load Balancing level;
- Traffic is proxied downstream to stateless micro-frontends;
- GraphQL level proxy serves upstream ingress requests from the frontend apps. Requests are aggregated, optimized and in case of cache miss, redirected to the backend service;
- Backend services were more complex (e.g., state-full, data sensitivity, auditing, and low latency requirements) and therefore optimized for a specific domain or functionality.
This architecture entails a fine balance between copying best practices and deep-dive optimizations for critical and specialized services. For example, it was easy to update scheduled scaling across many customer-facing apps, like traffic spikes correlated to marketing activity. Simultaneously, we used load test insights for more complex optimizations (central processing unit [CPU], memory, disk input/output [I/O] bound). After these preparations, we adopted the term Best Friday and were able to recognize different user behavior patterns even from the traffic, or auto scaling graphs.
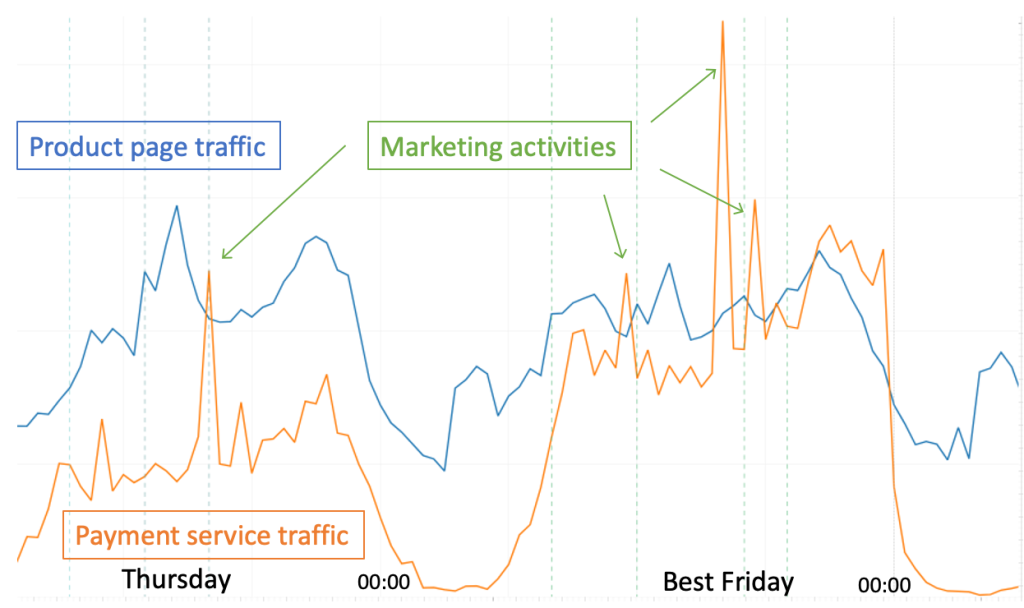
Delegating operational ownership to various teams posed few challenges, mainly around the AWS knowledge levels within those teams. To mitigate this, we decided to deploy our application on AWS Fargate rather than Amazon EC2, which had a 2-fold effect:
- In most cases, it was more cost-effective for setting Amazon ECS and Amazon EC2 auto scaling complex tasks;
- It allowed the teams to focus on modernizing other parts or just on daily business features.
We based services on initial blueprints, so Amazon EC2 to AWS Fargate migration was useful and relatively straightforward.
Future possibilities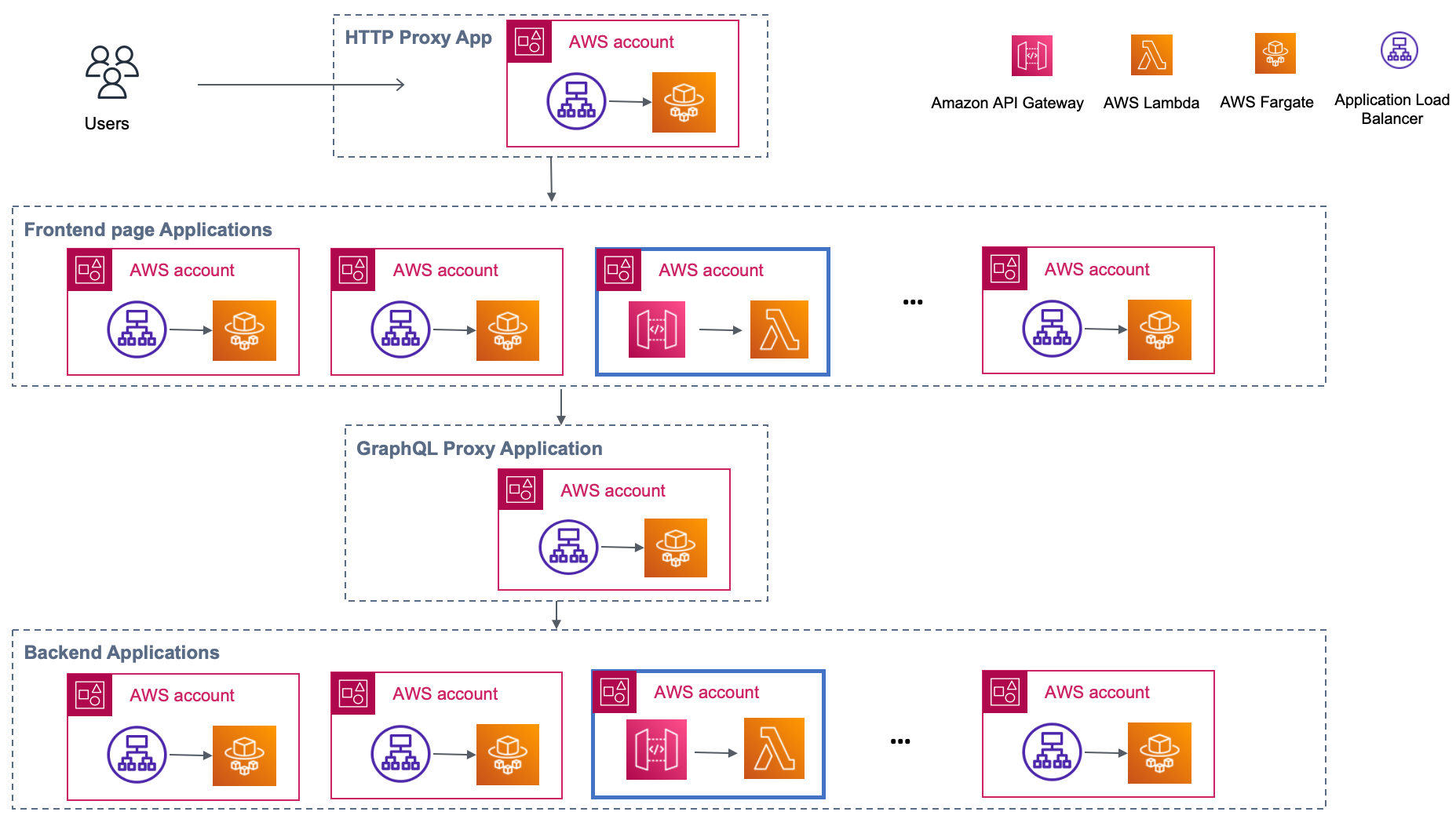
We believe that innovation is the ability to make changes at all levels. We evaluated new services and challenged existing ones to better utilize our technology stack. DNS, HTTP endpoints, GraphQL schemas, AWS CloudFormation, and Docker files provided many innovative solutions. Most importantly, we realised that different technologies could co-exist.
Running with the content web service deployed on AWS Lambda posed a challenge of consistency, because one type and size doesn’t fit all. Re-evaluating this service, we learned that with Amazon ECS/AWS Fargate, we were able to deliver a consistent experience. The opposite example would be the order service that wasn’t sensitive to consistent experience and we needed multiple parallel concurrent AWS Lambda functions to execute and cope with traffic surges, which made it a good choice for AWS Lambda.

We strongly believe that one type (and size) doesn’t fit all because organizations choose the technology based on the best fit and experience of their teams. Consequently, spiky traffic was a better fit for AWS Lambda auto scaling in our scenario. We replaced Amazon ECS with AWS Lambda, but only for a single service where it was reasonable. It survived 2022 Black Friday, even without AWS Lambda-provisioned concurrency.
What about the future? Migrations take time, and it’s good to have a stable foundation for gradual changes. The hard work of modernizing the application toward cloud-native technologies is paying off. With many exciting technologies with which we can innovate further, we’re happy to have compatible migration paths for them.
Here is a list of possible further improvements:
- AWS App Mesh, AWS Copilot, Service Connect, Graviton – based on the same Amazon ECS platform.
- AWS Cloud Development Kit (AWS CDK), AWS CloudFormation modules, and custom resources – based on the same Infrastructure-as-Code constructs.
- Improved compute, cache, or other future specialized services – migration via DNS change.
Conclusion
In this post, we have shown you our architectural model for future-proof cloud environments. It’s tempting to draw a future-proof architecture from scratch, but a bigger picture emerged when looking to the past. AWS helped scale to many machines, but scaling people doesn’t always work. Technological limits keep the shape of the architecture, while freedom among colleagues ensures it can evolve.
We hope this post has inspired you to challenge your own cultural and technical architecture.

Aurelijus Banelis, home24
AWS Certified Associate Developer, Technology enthusiast, conference speaker, and blog writer, with almost 10 years of experience in the IT industry, started as a backend developer, now leading a technology team at home24.