AWS Database Blog
Achieve a high-performance migration to Amazon RDS for Oracle from on-premises Oracle with AWS DMS
Many customers deploy the Oracle Database to an on-premises data centers running general purpose hardware or a highly customized Oracle Exadata hardware. These Oracle database customers are now looking to migrate to Amazon Relational Database Service (Amazon RDS) for Oracle, which is a fully managed commercial database that makes it easy to set up, operate, and scale Oracle deployments in the cloud.
Multiple options are available to migrate Oracle databases to Amazon RDS for Oracle (for details, refer to Importing data into Oracle on Amazon RDS). In this post, we cover how AWS Database Migration Service (AWS DMS) helps you migrate existing data to Amazon RDS for Oracle with lower cost and higher performance.
In our last blog post Migrating Oracle databases with near-zero downtime using AWS DMS, we covered how AWS DMS can migrate Oracle databases to AWS with near-zero downtime. Our post’s focus is on importing one-time data to Amazon RDS using AWS DMS as opposed to using Oracle Data Pump, which requires an application outage. This is useful for use cases where Oracle Data Pump isn’t efficient enough, or when the database is really large or has large object (LOB) columns. For instance, while migrating from Oracle Enterprise Edition to Oracle Standard Edition on Amazon RDS, parallel Data Pump Export/Import doesn’t work. Also, while migrating LOBs, Data Pump won’t use the parallel feature even with Enterprise Edition. In this post, we provide best practices for a high-performance migration to Amazon RDS for Oracle with near-zero downtime using one service, AWS DMS.
Solution overview
The following figure depicts how AWS DMS pulls data from the on-premises Oracle database and pushes it to Amazon RDS for Oracle.

In the following sections, we discuss strategies for migrating large tables and LOB columns, splitting tables into multiple tasks, and other important considerations.
Prerequisites
Before we use AWS DMS to migrate the database, you must have the following:
- A source Oracle database running on an existing on-premises environment
- A target Oracle database running on Amazon RDS for Oracle
- An AWS DMS replication instance with the optimal instance type for your migration workload
- Network connectivity from the AWS DMS replication instance to the source and target Oracle databases
- A database user account with required privileges on the source and target Oracle databases
Additionally, review the limitations before starting the migration for the source and target Oracle databases.
Amazon RDS for Oracle considerations during migration
In this section, we discuss some considerations during the migration before diving into the migration methods.
Disable the archive log
An archived redo log file is a copy of one of the filled members of a redo log group. There are many advantages of a database running in archive log mode. For example, it enables the recovery ability in the event of a system crash. However, in this mode, there is a performance impact because the Archiver Process (ARCn) is required to ensure that the archiving of filled online redo logs doesn’t fall behind. And because it adds an overhead of writing archived redo logs to the disk, it increases the I/O overhead on RDS storage.
During the migration, the database on Amazon RDS for Oracle isn’t available for production, so you can temporarily disable the archived logs. This can help in dedicating storage I/O for data migration. Also, in the case of automated backups, Amazon RDS uploads the transaction logs for DB instances to Amazon Simple Storage Service (Amazon S3) every 5 minutes. And in Amazon RDS for Oracle, the archive log can be disabled by just disabling the database backups. Therefore, running target databases in noarchivelog mode with Amazon RDS automated backups disabled makes more sense.
Disable Multi-AZ
Amazon RDS provides the option of deploying databases in Multi-AZ instance deployments for high availability. This enables failover support for Oracle DB instances by deploying a secondary instance in a different Availability Zone using synchronous block-level replication. With Multi-AZ deployment, you pay the infrastructure cost for two DB instances (one primary and one secondary). Additionally, there will be a slight overhead because of synchronous replication between instances in different Availability Zones. Therefore, it’s recommended to run the target RDS for Oracle database in a single Availability Zone at the time of migration. You can later modify the instance to run in Multi-AZ before connecting the production application to Amazon RDS.
Increase the redo log group size
By default, Amazon RDS for Oracle has four online redo logs of 128 MB each. If this is too small, it will cause frequent log switches and additional overhead on the log writer (LGWR) process. With so many log switches, you will notice a degradation in database performance. The Oracle database alert log will have the following message:
This message means that redo logs are being switched so fast that the checkpoint associated with the log switch isn’t getting completed. This means that redo log groups are filled by the Oracle LGWR process and are now waiting for the first checkpoint to complete. Until the first checkpoint is complete, processing is stopped. Although this would be for less time, because of this happening multiple times, it will cause an overall degradation of the database migration. To address this, it’s recommended to increase the redo log size on the target RDS for Oracle database.
Make sure to enable archive logging, enable Multi-AZ, and set the redo log size so that log switches are happening with an interval of 15–30 minutes before moving to production.
Create the primary key and secondary indexes after full load
Disabling the primary key and secondary indexes can significantly improve the performance of the load. With AWS DMS, you have an option to create the primary key after loading the data by changing the task setting CreatePkAfterFullLoad.
Migrate large tables
By default, AWS DMS uses a single thread to read data from the table to be migrated. This means AWS DMS initiates a SELECT statement on the source table during full load data migration phase. It does a full table scan, which isn’t recommended on large tables, because it causes all blocks to be scanned sequentially and a huge amount of unnecessary I/O. This will eventually degrade the overall performance of the source database as well as migration speed.
Although this is acceptable for smaller tables, performing a full table scan on a large table could cause slowness on the entire migration effort and could also result in ORA-01555 errors.
AWS DMS provides built-in options to load tables in parallel using the partition-auto or subpartition-auto feature when using Oracle endpoints, but for tables that aren’t partitioned, you have to identify the ranges manually and use the range partitions feature. For examples of migrating partitioned tables, refer to Speed up database migration by using AWS DMS with parallel load and filter options.
Using parallel load on an indexed column will significantly improve performance, because it forces the optimizer to use an index scan instead of a full table scan during unload. One of the important factors in choosing range segmentation is to identify the right number of partitions and also make sure the data is distributed evenly. For example, if you have a table with 2 billion rows and you’re using five ranges to load them in parallel, you’re still performing a full table scan on the table.
One way to identify if the SELECT query being sent by AWS DMS to the source database isn’t doing a full table scan is by enabling database tracing at the session level using a logon trigger. For example, one table boundary has 1 million rows, whereas another boundary has 1 billion rows. This is also going to affect migration performance, because one range will take more time than the other. Therefore, even if you have partitioned your table, you still have to validate if the data is evenly distributed. If not, it’s better to load them using ranges instead of using the built-in auto or subpartition feature of AWS DMS.
The following query uses the ntile function to identify the column with the exact number of rows in each partition. It also provides the max value, which can be used as a range for your table mapping to load it in parallel. You can use this even if your column is an UUID.
Make sure to run it in your standby or development instance before running on your primary.
The following screenshot shows an example of the query output. ID is the column on which we are planning to create a range boundary for table VIQASH.DUMMY_TABLE. The number of partitions specified is 16, which seems enough for a 10-million-row table.

In table mappings, this can be specified for a non-partitioned table in JSON. For more information, refer to AWS Database Migration Service improves migration speeds by adding support for parallel full load and new LOB migration mechanisms.
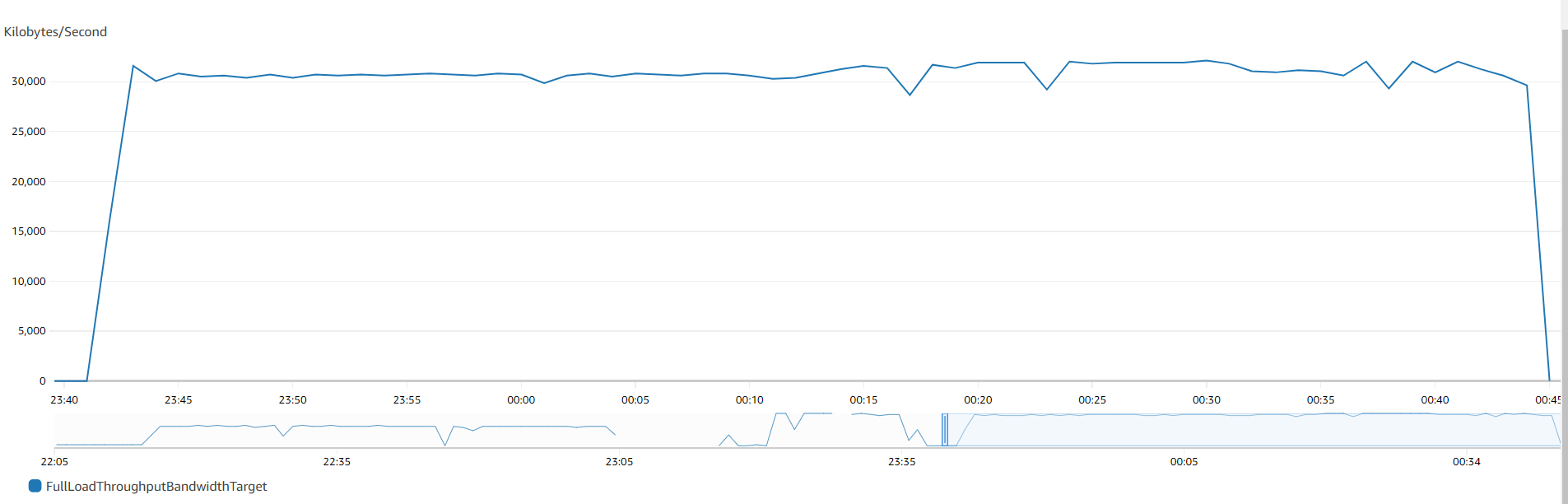
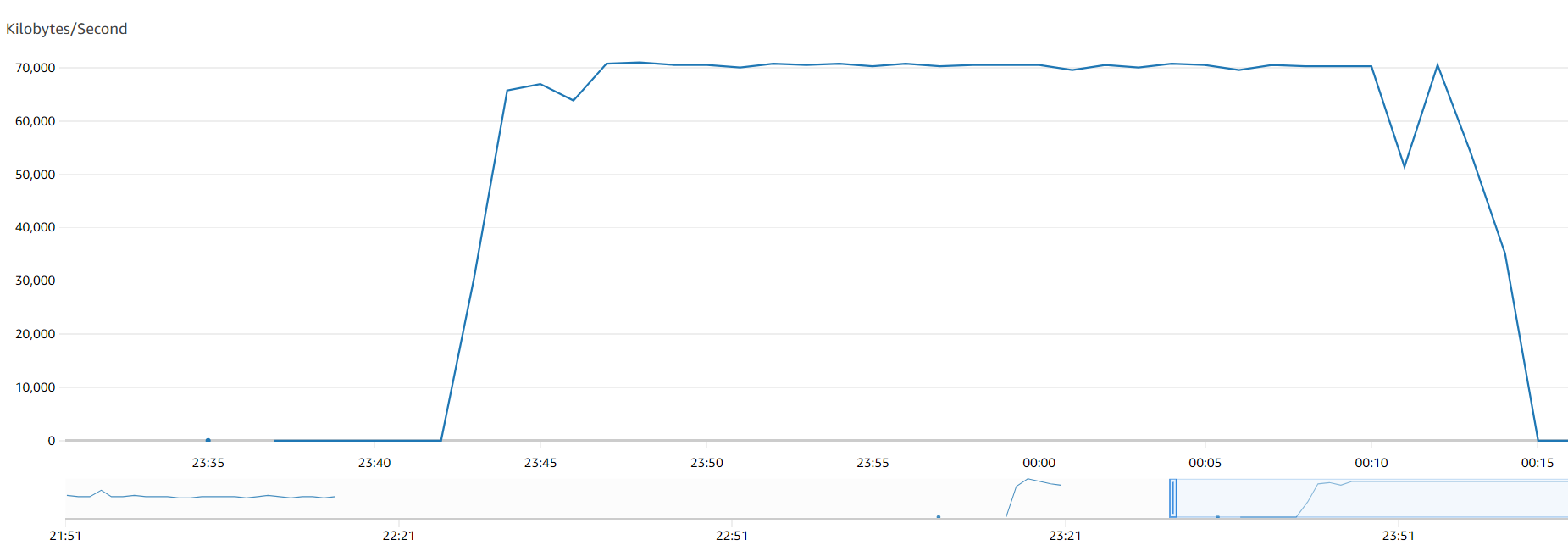
In our test environment (replication instance type dms.R5.xlarge), we migrated a table with 100 million rows in 1 hour and 14 minutes. The table was wide and had a LOB column that was less than 32 KB. With parallel load using 24 range segments, we could load the same table in just 36 minutes. The following graphs show the throughput that was achieved while using single-threaded compared to parallel segments.
The first graph shows a single-threaded method without the parallel load option.
The following graph shows throughput with 24 ranges.
Keep in mind that performance can vary widely based on different factors, such as the following:
- Good network bandwidth – For example, if you have a shared link (VPN) between the on-premises database to the AWS Region, you might not see the same performance as our example, because you might be saturating the network bandwidth. This could impact the load, and you might not be able to use higher parallelism. On the other hand, if you use a dedicated link or AWS Direct Connect, you might see a better performance when loading a large dataset.
- LOBs – With a greater number of LOB columns in your table, additional memory is required to load such tables, and provisioning a replication instance with lower memory will impact the performance of the load. Additional options for replicating LOB data efficiently is covered in the next section.
- Replication instance – Having more CPU and memory is ideal for parallelism. For guidance on choosing the best size, refer to Choosing the best size for a replication instance.
Based on our test, it took us half the time to load the table when using parallel load with optimal configuration, and we avoided full table scans on the source database while unloading the data.
Migrate LOB columns
Migrating LOB columns is challenging for any database migration because of the large amount of data they hold. AWS DMS provides three options to migrate LOB columns: limited, full, and inline mode.
Limited LOB mode
This is the preferred mode of any LOB column migration because it instructs AWS DMS to treat LOB columns as VARCHAR data types, pre-allocates memory, and loads the LOB data in bulk. You have the option to specify the max LOB size (KB), which is recommended to be less than 63 KB. You can set it to greater than 63 KB, but that could affect the performance of the overall full load. For more information about limited LOB mode, refer to Setting LOB support for source databases in an Amazon DMS task.
Any data in the column greater than the max LOB size (KB) will be truncated, and the following warning is written in the AWS DMS logs:
To identify the maximum size of LOB columns (in KB), you can use the following query:
Therefore, if you have LOB columns larger than 63 KB, consider full LOB mode or inline LOB mode, which may give better performance when loading your table.
Full LOB mode
This mode migrates the entire column irrespective of the LOB size. This is the slowest option for LOB migration because AWS DMS has no information about the maximum size of LOBs to expect. It just uses LOB chunk size (KB), which by default is 64 KB, to distribute the LOB data in pieces. Then it sends all chunks to the target, piece by piece, until the entire LOB column is migrated.
Full LOB mode performs a two-step approach for loading the data: it inserts an empty_clob or empty_blob on the target followed by a lookup on the source to perform an update on the target. Therefore, you need a primary key on the source table to load LOBs using full LOB mode. If you don’t have a primary key, AWS DMS prints the following message on the logs:
Inline LOB mode
This mode is a hybrid approach that combines the functionality of limited LOB mode and full LOB mode, and provides better performance when loading LOB objects. Based on your task configuration, AWS DMS will choose to perform inline or LOB lookup based on the size of the data. Because it uses full LOB mode as well, it’s also mandatory to have a primary key or unique key on the source table. The maximum value allowed for inline LOB size is also 2 GB, which is the same as for limited LOB mode.
Understanding your LOB data
As stated earlier, migrating LOBs is tedious in general, so it’s important to understand the LOB distribution of your table before choosing the setting. If your distribution varies a lot across your table, it makes it more challenging to load the data. The following query could be useful for analyzing your LOB distribution and choosing the right setting for your task. This script creates a table for analyzing the LOB distribution of your table:
*Replace LOB-COLUMN-NAME with actual LOB column and LOB_TABLE with actual table name.
Make sure to run it in your standby or development instance before running on your production.
After the table is created, you can use the following query to check LOB distribution in the source table:
The output is similar to the following screenshot (based on the number of rows you have in the source database table).

This query output highlights that there are six rows with a max LOB size of 5 bytes, which accounts for 85% of the entire table data (the first row in query output). There is only one row, which is 120,045,568 bytes (115 MB), which accounts for 14% of the entire data in the table.
Based on this information, it will be more efficient if we migrate six rows with small LOB size using inline LOB mode, and just one row using full LOB mode. To achieve this, we can modify the task settings as follows:
With this task setting, six rows that are 5 bytes each are migrated using inline LOB mode. This is because parameter InlineLobMaxSize is set to 32 KB. It means any rows with LOB size less than 32 KB will use the limited LOB mode method to load the data. The row with size 115 MB will be migrated using full LOB mode with a two-step process.
Split tables into multiple AWS DMS tasks
For large databases, you must always understand and plan the migration first. The most important part of this is deciding how many tasks need to be created in total. One important reason for creating multiple tasks is to better utilize AWS DMS replication instance resources (CPU, memory, and disk I/O). For example, a single task migrating 100 tables won’t be able to utilize all resources, compared to 10 tasks with each task migrating 10 tables.
Replication instance type plays a vital role in deciding how many AWS DMS tasks run on it in parallel. It is entirely dependent on the resources available on the replication instance. This needs to be monitored by looking at the AWS DMS replication instance metrics. Based on resources, you can create additional tasks. There isn’t any magic number for the number of tasks per instance, because each customer migration workload is unique. For example, tables with different LOB sizes, number of tables, size of tables, and so on won’t be the same. Therefore, some analysis is required to distribute tables among multiple AWS DMS tasks.
By default, AWS DMS migrates eight tables in parallel per task, which is based on the parameter MaxFullLoadSubTasks or the Maximum number of tables to load in parallel setting on the AWS DMS console. The maximum value that can be defined for this parameter is 49. This accounts not only for the tables to load in parallel, but also for the number of partitions to load in parallel (in case of using parallel load mode). It’s usually a best practice to increase this parameter when you’re migrating small tables in parallel. This parameter is also important for tables with range segmentation. For example, if you have defined 200 partitions for a single table, AWS DMS will still migrate only 8 partitions in parallel. Therefore, increasing this parameter to a maximum value will increase the speed of migration. Having a large number of threads to read from the source could adversely impact source database performance because of multiple threads. Therefore, it’s important to watch out for resources on the source database and replication instance.
In a test environment (MaxFullLoadSubTasks set to the default of eight) where we had a table with 58 GB and 4.5 TB of LOBs with a maximum size of 80 MB LOB columns, the AWS DMS estimate was around 5 days to migrate all the data. This estimate was calculated by identifying the number of rows transferred in a few hours. With the value set to 49 for MaxFullLoadSubTasks, AWS DMS was able to migrate all the data in 20 hours.
Other important AWS DMS parameters to consider
Stream buffer task settings is important for tables, especially with LOB columns. By default, the memory allocated for a task would be 24 MB with a three-stream buffer, and each buffer has the default 8 MB. Increasing this value helps increase the memory allocated for the outgoing stream buffer size, and increases performance while unloading the LOB data into the target database.
When using parallel load on the target with a direct path load, it’s important to disable the constraints in the target and also add these direct path settings on the target endpoint to avoid any ORA-00054 errors. Additionally, using directPathNoLog won’t generate redo logs while unloading the data.
For more information about directPathNoLog and directPathParallelLoad, refer to Using an Oracle database as a target for AWS Database Migration Service.
Summary
In this post, we discussed how to perform migration between an on-premises Oracle database to Amazon RDS for Oracle efficiently using AWS DMS. We also looked into various AWS DMS settings and used SQL queries to identify the ideal configuration, which will help when migrating your database.
Try these settings in your next Oracle database migration to Amazon RDS for Oracle. If you have any comments or questions, leave them in the comments section.
About the Authors
 Viqash Adwani is a Sr. Database Specialty Architect with Amazon Web Services. He works with internal and external Amazon customers to build secure, scalable, and resilient architectures in the AWS Cloud and help customers perform migrations from on-premises databases to Amazon RDS and Amazon Aurora databases.
Viqash Adwani is a Sr. Database Specialty Architect with Amazon Web Services. He works with internal and external Amazon customers to build secure, scalable, and resilient architectures in the AWS Cloud and help customers perform migrations from on-premises databases to Amazon RDS and Amazon Aurora databases.
 Aswin Sankarapillai is a Sr. Database Engineer in Database Migration Service at AWS. He works with our customers to provide guidance and technical assistance on database migration projects, helping them improve the value of their solutions when using AWS.
Aswin Sankarapillai is a Sr. Database Engineer in Database Migration Service at AWS. He works with our customers to provide guidance and technical assistance on database migration projects, helping them improve the value of their solutions when using AWS.