AWS Database Blog
Amazon Elasticsearch Service Now Supports the Seunjeon Plugin for Improved Korean Language Analysis
September 8, 2021: Amazon Elasticsearch Service has been renamed to Amazon OpenSearch Service. See details.
To ensure high fidelity parsing and matching for Korean text, Amazon Elasticsearch Service (Amazon ES) now supports the Seunjeon plugin. Using this plugin, you can create a custom analyzer that gives your users better results.
Processing Asian languages for search
When you use a search engine, you type words into the search box. The search engine then matches those words to words appearing in the documents that you have indexed. To match correctly, the search engine needs to parse the words (in other words, the search terms) out of the source string.
The engine does this by a sequence of steps. Some examples of steps are tokenizing on whitespace, applying stemming to bring words to their root form, removing stop words (frequent, low-value terms), and more.
The processing of Asian language text is complicated, because many words can be compound and not separated by white space. The same string of characters can mean different things in their compound context.
The most basic processing of Asian languages in Elasticsearch is provided through the cjk analyzer. This analyzer splits on whitespace and then creates bigrams—two-character pairs—of the characters in the resulting text. For example, the string 아마존으로 adds the following terms to the index.
아마
마존
존으
으로
Elasticsearch does the same analysis when you query. The more bigrams in the query that match bigrams in the index, the better the match.
Unfortunately, matching bigrams can lead to unexpected results. For example, 아마존이, 아마존은, 아마존으로, 아마존을, and so on, are all words meaning Amazon. Extracting terms by whitespace or computing bigrams can lead to poor results. If we query 아마존, documents including 아마존이, 아마존은, 아마존으로, and 아마존을 might not be in the results, because of how whitespace analysis works. Or such documents might not score highly enough to appear in the search results, because of how bigram analysis works. When users write queries, they most often simply search all the sentences including 아마존 (Amazon). In our example, if they do, many results are missing.
A better Korean analyzer: Seunjeon
Supporting high-fidelity matching requires a Korean analyzer that can do more than process terms based on whitespace or by splitting into bigrams. Seunjeon is a widely used, open-source Korean analyzer, now available in Amazon ES. This analyzer is based on mecab-ko-dic, which is a Korean language dictionary. The dictionary is an important part of the analyzer, with entries for source text and the correct terms for that text. Amazon ES currently provides mecab-ko-dic-2.0.1-20150920.
To enable the plugin to work well with instances that have low memory, we have made multiple optimizations to its internal data structures and functions, and contributed our enhancements back to the community. The resultant plugin has a 59 percent lower memory footprint and is now also available as a separate, optimized version in the bitbucket repository.
How to create a mapping using the Seunjeon plugin
Amazon ES comes prepackaged with the Seunjeon analyzer that is automatically deployed and managed for you. You can just start searching with a Korean keyword after configuring an analyzer for your source fields.
The following code creates an index with the Korean analyzer.
In the preceding Elasticsearch mapping, we define a custom field analyzer [1], named korean [2] that uses a custom tokenizer [3] (a tokenizer takes the string and converts to terms). We also define the tokenizer [4] in the mapping, using seunjeon_tokenizer. At this point, we set some options and added some custom terms [5] to the user dictionary. Finally, we apply our analyzer to the status field [6]. When you send documents to Amazon Elasticsearch Service in this case, it always uses the korean analyzer for the text in the status field.
You can call the analyzer directly and see how the tokenization and analysis work.
This call’s output follows.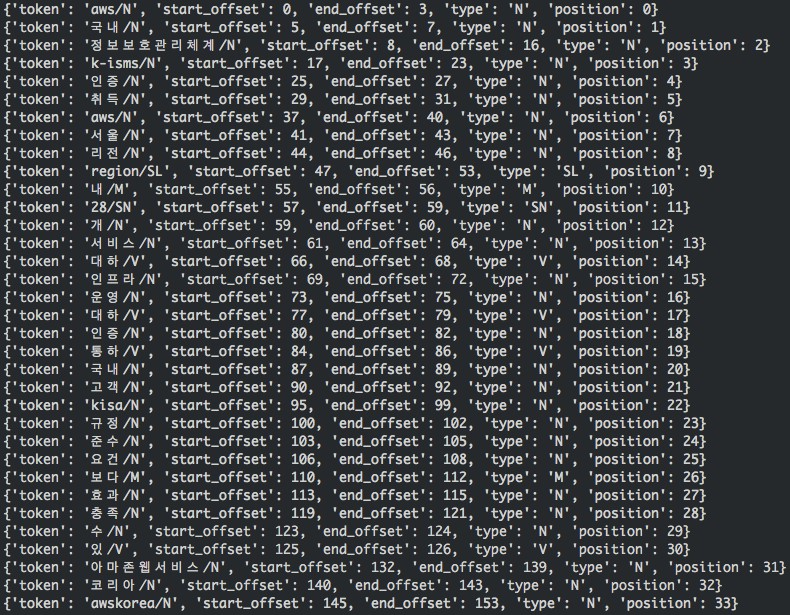
You can see that most of the terms are analyzed by the Seunjeon plugin based on the embedded mecab-ko dictionary. You can also see terms that were output based on our custom dictionary entries: aws, awskorea, 아마존웹서비스, 정보보호관리체계, k-isms,10, and kisa,10. Without the custom dictionary, 정보보호관리체계 (Information Security Management System) is treated as a series of bigrams like the following.
The custom dictionary entries improve the search quality and provide better results.
Summary
To ensure high fidelity parsing and matching for Korean text, use the Seunjeon plugin in Amazon Elasticsearch Service. You can create a custom analyzer with base tokenization and custom words, then apply that analyzer to a string field that contains your data. The Seunjeon plugin also parses and tokenizes queries against that field, giving you better results.
About the Authors
 Piljoong Kim is a solutions architect at Amazon Web Services. He works with our customers to provide architectural guidance and technical assistance on AWS services. Prior to AWS, he developed and launched mobile games, web and mobile applications on microservices architecture.
Piljoong Kim is a solutions architect at Amazon Web Services. He works with our customers to provide architectural guidance and technical assistance on AWS services. Prior to AWS, he developed and launched mobile games, web and mobile applications on microservices architecture.
 Dr. Jon Handler (@_searchgeek) is an AWS solutions architect specializing in search technologies. He works with our customers to provide guidance and technical assistance on database projects, helping them improve the value of their solutions when using AWS.
Dr. Jon Handler (@_searchgeek) is an AWS solutions architect specializing in search technologies. He works with our customers to provide guidance and technical assistance on database projects, helping them improve the value of their solutions when using AWS.