AWS Database Blog
Amazon Neptune releases Streams, SPARQL federated query for graphs and more
The latest Amazon Neptune release brings together a host of capabilities that enhance developer productivity with graphs. This post summarizes the key features we have rolled out and pointers for more details.
Getting started
This new engine release will not be automatically applied to your existing cluster. You can choose to upgrade an existing cluster by following the instructions in the release notes. Or you can create a clone of an existing cluster that will receive the latest engine version.
If the Amazon Neptune cluster does not already exist, create a database with version 1.0.1.0.200463.0. Before we test Neptune Streams, we must enable it in lab mode. Based on customer feedback, Neptune is releasing early features in preview for customers to try out and validate their use cases. These preview features are in lab mode until they are productized in a future release. Lab mode allows you to enable (or disable) the experimental features in the Neptune engine using the neptune_lab_mode cluster parameter. You can configured lab mode using the AWS Console or the CLI.
AWS console
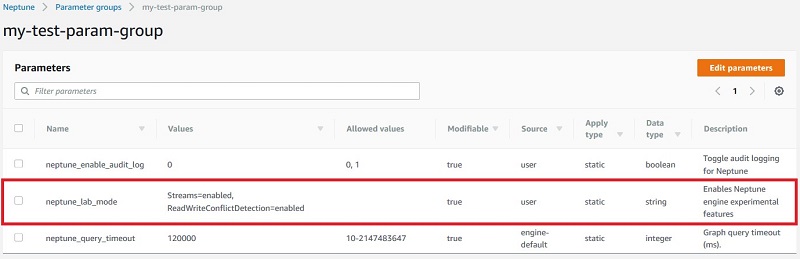
From the AWS console for Neptune, choose Parameter groups from the console left navigation menu. Navigate to the cluster parameter group associated with the Neptune cluster and choose Edit parameters. For the neptune_lab_mode parameter, add the following to enable Streams and Transaction semantics.
Streams=enabled, ReadWriteConflictDetection=enabled
AWS CLI
In addition to the console, you can use the CLI to check the value of the cluster parameter group and set the lab mode parameter. The following two commands can be used respectively:
Confirm that the changes have been made to the parameter group:
Note 1: If the Neptune cluster is associated with the default cluster parameter group (usually default.neptune1), you must create a new cluster parameter group and then associate it with the Neptune cluster.
Note 2: Whenever lab mode cluster parameters changes, you must reboot the instances in the cluster before using preview features.
Neptune Streams preview
Neptune Streams is an easy way to capture changes in your graph. When enabled in preview, Neptune Streams logs changes to your graph as they happen. Streams are available using the REST API https://Neptune-DNS:8182/sparql/stream or https://Neptune-DNS:8182/gremlin/stream for SPARQL and Gremlin respectively.
For example, if you add a vertex for person with name as the property, querying the REST endpoint for Gremlin returns the list of changes to the graph in JSON format. A similar query for SPARQL returns the N-Quads format.
The streams would indicate the operation on the vertex and its property in the stream result below.
SPARQL federated query
Neptune now supports SPARQL 1.1 federated query. Using the SPARQL1.1 SERVICE keyword, customers can execute portions of a query in different SPARQL endpoints within their Virtual Private Cloud (VPC), combine the results and return them to the user.
For example, if a sample query on the person dataset in one cluster retrieves persons with first name “John” and the second query on another cluster retrieves persons with last name “Abercrombie”, you can federate queries using SPARQL 1.1 and retrieve persons with first name “John” and last name “Abercrombie”.
Here is the example using RDF4J running on neptune_cluster_1 and federating query to neptune_cluster_2:
Note: If more than one Neptune cluster is in the same VPC, you must ensure the security group for each of the cluster allows the Neptune clusters to talk to one another over port 8182 (or the configured port).
Gremlin sessions
Sessions in Gremlin define the start and end of a transaction. Transactions are automatically committed only when the session is closed. This is different from the sessionless approach where Neptune automatically manages the transaction boundary for each request. To use sessions, pass the session parameter to the remote connection. The table below illustrates the behavior of two clients connected to the same Neptune cluster. Notice that the updates from the session are not visible until the session is closed.
Gremlin explain query
You can use the Gremlin explain query to understand the query execution plan and identify any bottlenecks. Gremlin explain query is available as a REST query on /gremlin/explain with the query supplied via the parameter as shown below.
Summary
That was a quick tour of the features in the current release (1.0.1.0.200463.0) of Neptune. We encourage you to spin up a test cluster and try out the features in the latest release. More details about each capability are in the documentation. Many of the features in this blog post will also be elaborated in future posts shortly. Stay Tuned.
We are always eager for your feedback. Please reach out using the comments below or via the support forums.
About the Author

Karthik Bharathy leads product for Amazon Neptune.