AWS Database Blog
Building a customer 360 knowledge repository with Amazon Neptune and Amazon Redshift
Organizations build and deploy large-scale data platforms like data lakes, data warehouses, and lakehouses to capture and analyze a holistic view of their customer’s journey. The objective of such a data platform is to understand customer behavior patterns that influence satisfaction and drive more engagement. Applications today capture each point of contact with a customer, but that data is spread across different locations (such as external partners, outsourced SaaS like chatbots or call centers, on-premises systems, or public clouds like Google Analytics) with little or no links between the data captured. Therefore, the challenge is to connect these disparate data sources as your customer navigates from initial contact to their current state in the journey. You need a 360-degree view of your customer through a knowledge base containing key attributes of their journey and links pointing to detailed data. This knowledge base must be flexible, agile, and extensible to support new data patterns as your data landscape evolves.
Amazon Neptune is a purpose-built graph database to store connected data patterns, which you can use to build a customer 360 view by capturing data from a customer journey in near-real time. The connected data solution can serve business insights to your customer service representatives, assist with new sales, provide recommendations for customers, power customer 360 dashboards, or serve as a data repository to perform machine learning (ML)-based analytics.
This post shows how you can use Neptune to build a customer 360 knowledge base solution using a customer journey in home insurance. You walk through the following steps:
- Build a sandbox environment to show proof of value (POV) for the connected data platform
- Define the customer journey steps from initial contact to an engaged, active customer
- Use Amazon Redshift SQL and analytic features and understand the data patterns and associated links between data from different sources involved in a customer journey
- Define business state entities and associated relationship in the entity relationship (ER) diagram
- Create a graph model that identifies vertices, edges, and properties from the ER diagram and sandbox data
- Generate Neptune load files on Amazon S3 from Amazon Redshift
- Perform bulk loading of the connected graph data in Neptune
- Build customer 360 applications that prove the business value of the connected data
- Integrate Neptune with the data pipeline for connecting data stores and publishing new facts in purpose-built databases
The following diagram illustrates this process.

Overview of solution
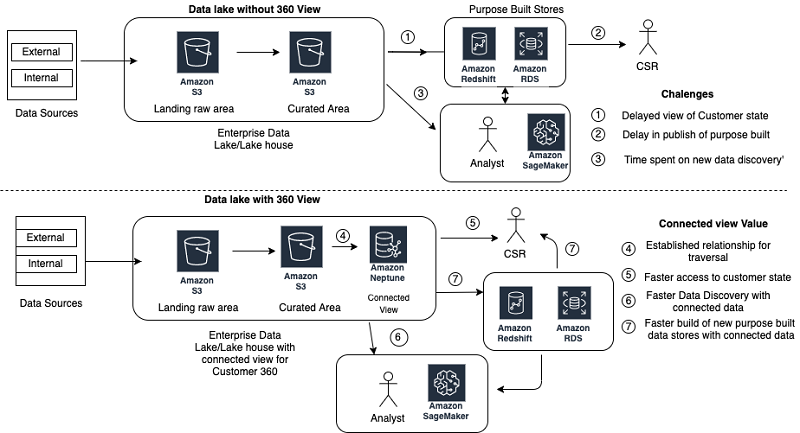
An enterprise data platform ingests customer journey data using a variety of data capture mechanisms (web front ends, mobile applications, call centers, external feeds, external data agencies and partners, cloud fronts, and internal hosted applications). In a typical data platform, to understand customer behavior patterns, you ingest, transform, and curate all variety of data in different types of data stores. You can broadly classify the data source patterns as external structured, external unstructured, internal structured, and internal unstructured. As the data patterns grow and change with new or modified customer-centric products, the customer journey data gets disjointed in multiple data stores. Connecting all the data associated with a customer to provide a holistic data state can be challenging. The insights become stale and the latency to provide the latest customer-focused insights starts growing. Data lakes become swamps, and you need to clean and build new purpose-built stores to address the unresolved business challenges to reduce customer dissatisfaction.
You can capture the relationship between data entities as vertices and associated edges in the curated layer of the enterprise data lake by using the Tinkerpop property graph. With the Neptune capabilities of variable schema (new properties) and extensibility to add new entities (vertex and edge), you can store customer data from new feeds in near real time and publish customer 360 views faster. The following diagram compares these architectures.
Walkthrough
In this post’s use case, your home insurance company wants to understand your customer behavior in a new insurance paradigm that uses modern applications to sign new customers up for home or apartment insurance. You need to understand the current state of a customer’s journey depending on the path taken (web browser, mobile app, or call center) and sell an insurance policy at the right price and coverage, which results in higher satisfaction for a long-lasting, engaged customer.
This post looks at the four different data ingestion patterns, the associated challenges to analyze the unrelated data, how to use Amazon Redshift to analyze and create graph data, and how Neptune can add value to connect the dots between the data to provide a holistic customer 360 view in near real time. The following table summarizes the four ingestion patterns.
| Source origin | Data type | Source type | Data description |
| External | Structured data | Call center data |
Call center supported by SAAS solution. Vendor provides daily call logs related to customer call and agent interaction with customer. The system is focused on customer call-handling efficiency. |
| External | Unstructured data | Web analytics data |
Web analytics captured by third party. Daily pull of page views and events. Data is gleaned to understand customer web patterns and improve web application usage. |
| Internal | Structured data | Core transaction data |
Insurance data for quotes, policy, and customer information captured in relational database. Data is used for generating metrics on new policies and metrics on customer journey abandons. |
| Internal | Unstructured data | Application server logs |
Application server events captured in Amazon CloudWatch containing browser information with key application entity tracking. Using log analytics, data is scanned to improve reliability and availability of web applications. |
Building the sandbox environment
You build a sandbox environment with AWS platform components (Amazon S3, Amazon Redshift, Neptune) to create a POV for a connected data platform. For more information about commands and procedures, see AWS Documentation.
To build your environment, complete the following steps:
- Create an S3 bucket (
cjsandboxpov<last five digits of account>) with the following folders to store example data from the existing data platform:- /landingarea – Landing area folder to collect data from all four sources in CSV or Parquet format
- /neptune_vertex – Neptune load vertex folder to dump CSV load files for dump data regarding graph vertices
- /neptune_edge – Neptune load edge folder to dump CSV load files for dump data regarding graph edges
This post uses the S3 bucket name
cjsandboxpov99999. - Leave all secure bucket policies at their default.
- Create an Amazon Redshift cluster in your VPC sandbox environment to upload the source data.
- The cluster size should support data storage twice the size of raw data (for example, select 2 node ds2.xlarge cluster for up to 2 TB of raw data)
- Associate the IAM role for Amazon Redshift to read and write to the S3 buckets.
For more information, see Authorizing COPY, UNLOAD, and CREATE EXTERNAL SCHEMA operations using IAM roles.
- Use the Amazon Redshift query editor to connect to the Amazon Redshift database and create the sandbox schema
cjsandboxto define the incoming source objects. - Create a Neptune cluster to capture the graph attributes to build a knowledge base:
- Choose the latest version with a db.r5large cluster with no read replica
- Choose
cjsandboxas the database identifier and select the defaults as options - Initiate creation of the Neptune cluster
Discovering the customer journey and capturing key states
The following diagram illustrates the various paths a customer can take on their journey.

In the home insurance landscape for home, apartment, or property insurance, individuals have multiple options to engage with an insurance provider. An individual journey to buy an insurance policy could be simple and fast, using a mobile application for an apartment, or complex based on the size and location of the property with different coverage needs.
Insurance companies support the growing diverse market by providing multiple options (mobile, web, or call center) for initial first contact with potential customers. Your goal is to provide the best customer experience and quickly assist when a customer runs into a challenge or decides to abandon their inquiry.
The best customer experience requires capturing the customer journey state as quickly as possible, so you can provide options for quicker decisions that lead to the customer signing a policy. The goal is to reduce the abandons due to poor user interface experience, complexity of coverage selection, non-availability of optimal choices and cost options, or complexity of navigation in the provided interface. Also, you need to empower your enterprise representatives (sales and service representatives, or application developers) with the latest trends regarding the customer state and metrics to guide the customer to a successful policy purchase.
From the customer journey, you capture the following key states:
- Initial customer information – Email, address, phone
- Call center data – Phone, agent, state
- Web application logs – Session, quote, last state
- Web analytics logs – Visits, page views, page events
- Core journey data – Policy, quote, customer abandon or reject
Capturing the customer journey ER diagram and model graph with vertices and edges
After you define the customer journey states, identify the key transaction entities where the data is captured for the interaction. Build an ER diagram of the known entities and associated relationship with each other. The following diagram illustrates four isolated customer views.

Each data store consists of key fact tables. The following table summarizes the fact tables and their associated key attributes.
| Data store | Table | Key ID column | Key attributes | Reference columns to other facts |
| Web Analytics | VISIT | VISIT_ID | Visit time, browser ID | SESSION_ID generated by application (SESSION) |
| PAGE_VIEW | PAGE_ID | VISIT_ID, PAGE INFO | VISIT_ID to VISIT | |
| PAGE_EVENTS | EVENT_IG | PAGE_ID, EVENT_INFO | PAGE_ID to PAGE_VIEW | |
| CALL Data | CALL | CALL_ID | AGENT_ID, PHONE_NO, CALL_DETAILS |
PHONE_NO to CUSTOMER AGENT_ID to AGENT |
| AGENT | AGENT_ID | AGENT_INFO | AGENT_ID to CALL | |
| LOG Data | SESSION | SESSION_ID | QUOTE_ID, EMAIL, CUSTOMER_INFO |
QUOTE ID to QUOTE EMAIL to Customer SESSION_ID to VISIT |
| CORE Data | CUSTOMER | CUSTOMER_ID |
PHONE, EMAIL, DEMOGRAPHICS, ADDRESS_INFO |
PHONE to CALL EMAIL to SESSION ADDRESS_ID to ADDRESS |
| ADDRESS | ADDRESS_ID | City, Zip, State, Property address | ADDRESS_ID to CUSTOMER | |
| QUOTE | QUOTE_ID |
Quote info, Email, CALL_ID , SESSION_ID |
Email to CUSTOMER CALL_ID to CALL SESSION_ID to SESSION SESSION_ID to VISIT |
|
| POLICY | POLICY_ID |
Policy info, QUOTE_ID, CUSTOMER_ID |
CUSTOMER_ID to CUSTOMER QUOTE_ID to QUOTE |
After you review the data in the tables and their associated relationships, analyze the ER diagram for key entities for the graph model. Each key table fact acts as the source for the main vertices, such as CUSTOMER, ADDRESS, CALL, QUOTE, SESSION, VISIT, PAGE_VIEW, and PAGE EVENT. Identify other key entities as vertices, which are key attributes to connect different entities, such as PHONE and ZIP. Identify edges between the vertices by referring to the relationship between the tables. The following graph model is based on the identified vertices and edges.

The next key step is to design the graph model to support the Neptune Tinkerpop property graph requirements. Your Neptune database needs a unique ID for each of its vertex and edge entities. You can generate the ID with a combination of the prefix value and current unique business identifier for an entity. The following table describes some examples of the vertex and edge naming standards used to create unique identities for the Neptune database. Vertex entities are associated with three-letter acronyms concatenated with a database unique identifier. The edge name is derived by the direction of edge <from vertex>_<to_vertex_code>_<child unique id> describing one to many relationships between two vertices. Because the primary key values are unique for an entity, concatenating with a prefix makes the value unique across the Neptune database.
| Entity | Entity type | ID format | Sample ID |
| Customer | Vertex | CUS|| <CUSTOMER_ID> | CUS12345789 |
| Session | Vertex | SES||<SESSION_ID> | SES12345678 |
| Quote | Vertex | QTE||<QUOTE_ID> | QTE12345678 |
| VISIT | Vertex | GAV||<VISIT_ID> | GAEabcderfgtg |
| PAGE VIEW | Vertex | GAP||<PAGE_ID> | GAPadbcdefgh |
| PAGE EVENT | Vertex | GAE||<PAGE_EVENT_ID> | GAEabcdefight |
| ADDRESS | Vertex | ADD||<ADDRESS_ID> | ADD123344555 |
| CALL | Vertex | CLL||<CALL_ID> | CLL45467890 |
| AGENT | Vertex | AGT||<AGENT_ID> | AGT12345467 |
| PHONE | Vertex | PHN||<PHONEID> | PHN7035551212 |
| ZIP | Vertex | ZIP||<ZIPCODE> | ZIP20191 |
|
Customer->Session (1 -> Many) |
Edge | CUS_SES||<SESSION_ID> | CUS_SESS12345678 |
|
Session-> Customer (Many -> 1) |
Edge | SES_CUS||<SESSION_ID> | SES_CUST12345678 |
|
ZIP->ADDRESS (1 -> Many) |
Edge | ZIP_ADD||<ADDRESS_ID> | ZIP_ADD1234567 |
|
ADDRESS-> ZIP Many-> 1) |
Edge | ADD_ZIP||<ADDRESS_ID> | ADD_ZIP1234567 |
Analyzing the curated data for relationships in Amazon Redshift
Amazon Redshift provides a massively parallel processing (MPP) platform to review data patterns in large amounts of data. You can use other programming options like AWS Glue to create Neptune bulk load files for data stored in an Amazon S3-curated data lake. However, Amazon Redshift offers a database platform to analyze the data patterns and find connectivity between disparate sources, and an SQL interface to generate the bulk load files. An SQL interface is preferred for database-centric analysts and avoids the learning curve for building PySpark-based libraries. This post assumes the curated data for the data stores is published in the Amazon S3-based data lake in a CSV or Parquet format. You can load curated data in a data lake into the Amazon Redshift database using the COPY command.
To create a customer table in the sandbox schema, enter the following code:
To copy data from Amazon S3 to the customer table, enter the following code:
Dumping vertices and edges dump files to Amazon S3
The Neptune database supports bulk loads using CSV files. Each file needs to have a header record. The vertex file needs to have vertex ID attributes and label attributes as needed. The remaining property attributes need to specify the attribute format for each attribute in the header. The edge dump file needs to have an ID, from vertex ID, to vertex ID, and label as required attributes. The edge data can have additional property attributes.
The following code is a sample session vertex dump record:
The following code is a sample session quote edge dump record:
Because all the related data resides in Amazon Redshift, you can use a view definition to simplify the creation of the dump files for Neptune bulk loads. A view definition makes sure the header record is always the first record in the dump file. However, creating dump files to Amazon S3 has some limitations:
- The
NULLvalue in a column makes the entire string null. View uses theNVLfunction to avoid the challenge of skipping vertices in case one of the attributes has aNULL - Commas or other unique characters in attribute data invalidate the dump file data format. View uses the
replacefunction to suppress those characters in the data stream. - The
unloadcommand has a limit of 6 GB to create a single dump file. Any overflow files don’t have the header record, which invalidates the Neptune load format. View lets you sort the data by key columns to unload data in chunks, with each chunk having the Neptune format header.
The following example code is a view definition for a vertex source view:
The following example code is a view definition for an edge source view:
To create the vertex and edge dump files, use the UNLOAD command in Amazon Redshift. See the following code:
Loading vertices and edges dump files to Neptune database
The vertex and edge dump files are created in two different Amazon S3 folders. The vertex dump files are loaded first as edges, which requires the from and to for an edge to be present in the database. You can load the files one at a time or as a folder. The following code is the Neptune load command:
The load jobs create a distinct loader ID for each job. You can monitor the load job progress by passing the loader ID as a variable to the wget command.
To review the state of the load status, enter the following code:
To review load status with errors, enter the following code:
Performing POV of connected database
You need to verify the new solutions you implemented for their value to address the business outcomes. The connected Neptune database can now create a holistic view for a customer service representative. This post includes an example Python code to describe how to share a customer 360 of the connected data with an end-user. Complete the following steps:
- Using a customer ID, like email, identify the start vertex. For example, the following code is a Gremlin query:
- Navigate to the address vertex connected to customer vertex and get all associated address information. For example, see the following code:
- Navigate to all phone vertex and capture all call data in chronological order.
- Navigate to session and web analytics visit to capture all web activity.
- Navigate to associated quote and see the pattern for insurance selection.
- Identify the current state of the customer.
The visualization of a connected universe for a customer’s data provides the greatest value for a Neptune graph database. You can analyze the graph to discover new datasets and data patterns. You can then use these new patterns as input for ML to assist with optimizing the customer journey. The graph database reduces discovery time to understand data patterns for seed data to build ML models.
You can explore the connectivity between different entities by using a graphical browser interface for a graph database. The Show Neighborhood option in most graph browsers allows you to traverse different paths the customer takes. Complete the following steps:
- Start with a gremlin query to get the customer vertex.
- To see the associated phone, address, web sessions, and quotes, choose Show neighborhood for the customer vertex.
- To see all visits for a session, choose Show neighborhood for a session.
- To see all calls associated with a customer, choose Show neighborhood for a phone.
- To see all policies associated with a quote, choose Show neighborhood for a quote.
- To see all associated page views, choose Show neighborhood for a visit.

You can use the connected customer journey view to enhance the user interface (mobile or web) to set default coverage options using most widely selected options for a demographic (one-click insurance). For a zip code or a city, when you traverse the graph, you can identify customers and associated quotes and policies to identify the pattern for the deductibles and coverage chosen by satisfied customers. For abandon analysis, you can select the quotes with no policies to navigate to web analytics and find which form or event triggers customer abandon due to a complex user interface. To reduce call volumes to the call center, traverse the graph to capture trends of events that trigger a customer call.
Integrating the data lake with Neptune
After you establish the value of connected data, you can enhance the daily data pipeline to include the connected Neptune database. After you curate the data and publish it in the data lake, you can glean connected data to add new vertices, edges, and properties. You can trigger AWS Glue jobs to capture new customers, connect new application sessions to customers, and integrate the incremental web analytics data with session and customer information. This post includes an example AWS Glue job for maintaining vertices and edges.
After you publish a new curated data fact, trigger an AWS Lambda function to start an AWS Glue job to capture the latest entities added or modified, make sure their dependent data is already published, and then add or modify the vertex, edge, or property information. For example, when new session data arrives in the curated area of your data lake, initiate a job to add customer session-related entities to the Neptune database.
Code examples
The following code example is for a customer 360 using Python and Gremlin:
The following code example is an AWS Glue program that creates a Neptune CSV file as incremental data is curated:
Conclusion
You can use Neptune to build an enterprise knowledge base for a customer 360 solution that connects disparate data sources for customer state dashboards, enhanced analytics, online recommendation engines, and cohort trend analysis.
A customer 360 solution with a Neptune database provides the following benefits:
- Access to all activities in near-real time performed by a customer during their journey. You can traverse the graph to better support the customer
- Ability to build a recommendation engine to assist customers during their journey with feedback based on preferences of similar cohorts based on demographics, location, and preferences
- Segmentation analysis based on geography and demographics to understand challenges with the current market and opportunities for new markets
- Business case analysis to narrow down on a challenge by traversing the neighborhood to triage factors affecting your business
- Testing and validating new application deployment effectiveness to improve the customer journey experience
You can apply this solution to similar knowledge bases, such as vehicles or accounts. For example, a vehicle 360 knowledge base can track a journey of an automobile customer from pre-sales, dealer interactions, regular maintenance, warranty, recalls, and resell to calculate the best incentive value for a vehicle.
About the Author

Ram Bhandarkar is a Sr Data Architect with AWS Professional Services. Ram specializes in designing and deploying large-scale AWS data platforms (Data Lake, NoSQL, Amazon Redshift). He also assists in migrating large-scale legacy Oracle databases and DW platforms to AWS Cloud.