AWS Database Blog
Category: Advanced (300)

Essential tools for monitoring and optimizing Amazon RDS for SQL Server
In this post, we demonstrate how you can implement a comprehensive monitoring strategy for Amazon RDS for SQL Server by combining AWS native tools with SQL Server diagnostic utilities. We explore AWS services including AWS Trusted Advisor, Amazon CloudWatch Database Insights, Enhanced Monitoring, and Amazon RDS events, alongside native SQL Server tools such as Query Store, Dynamic Management Views (DMVs), and Extended Events. By implementing these monitoring capabilities, you can identify potential bottlenecks before they impact your applications, optimize resource utilization, and maintain consistent database performance as your business scales.

Migrate relational-style data from NoSQL to Amazon Aurora DSQL
In this post, we demonstrate how to efficiently migrate relational-style data from NoSQL to Aurora DSQL, using Kiro CLI as our generative AI tool to optimize schema design and streamline the migration process.

Replication instance sizing for optimal database migrations with AWS DMS
In this post, I show you how to use the new AWS DMS instance estimator tool for initial sizing recommendations, review monitoring strategies to collect accurate benchmark data, and present considerations on how to optimize your database migrations.
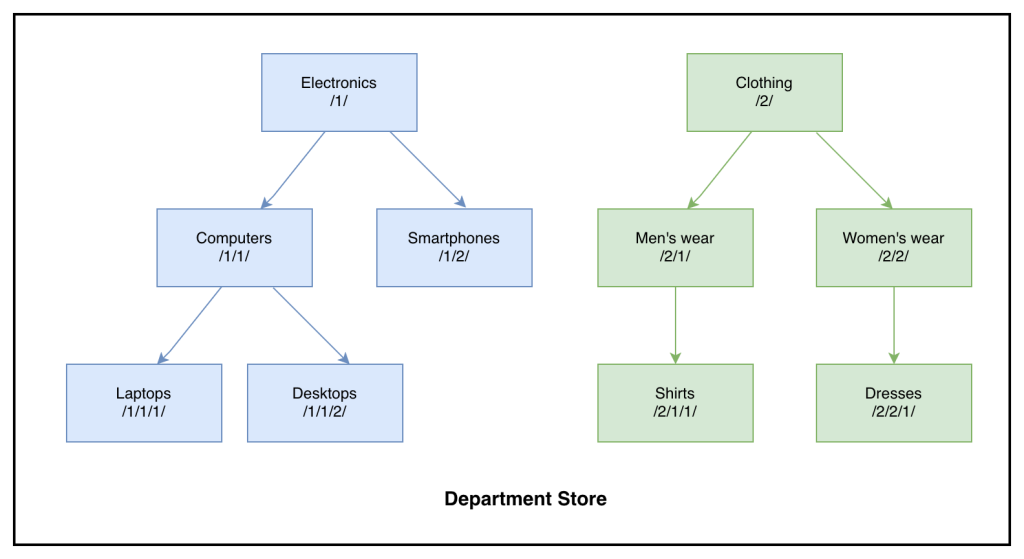
Build a custom solution to migrate SQL Server HierarchyID to PostgreSQL LTREE with AWS DMS
In this post, we discuss configuring AWS DMS tasks to migrate HierarchyID columns from SQL Server to Aurora PostgreSQL-Compatible efficiently.
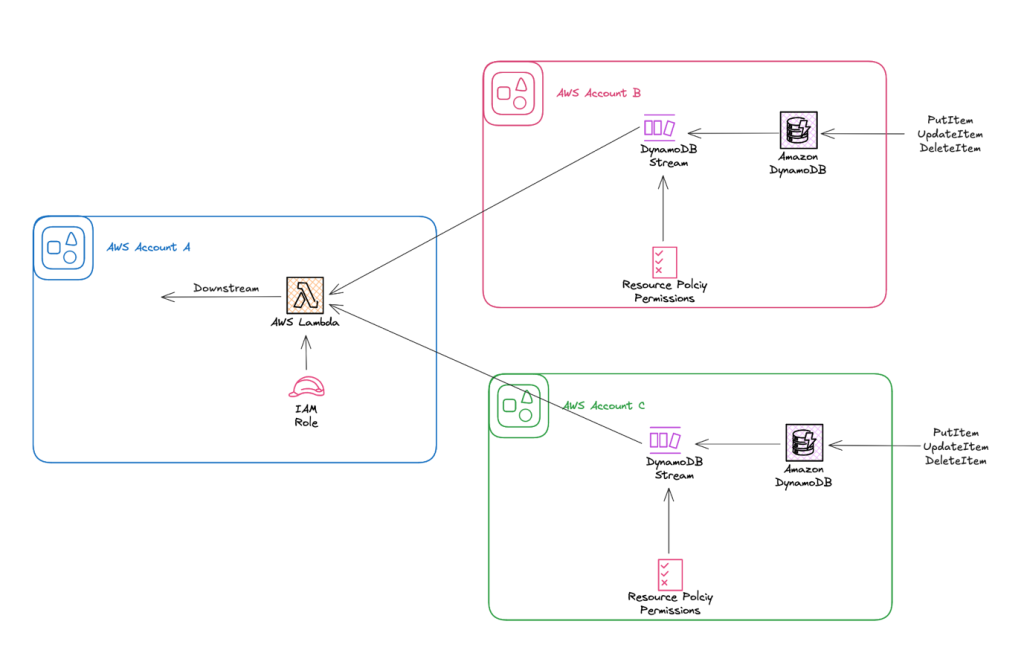
Simplify cross-account stream processing with AWS Lambda and Amazon DynamoDB
In this post, we explore how to use resource-based policies with DynamoDB Streams to enable cross-account Lambda consumption. We focus on a common pattern where application workloads live in isolated accounts, and stream processing happens in a centralized or analytics account.
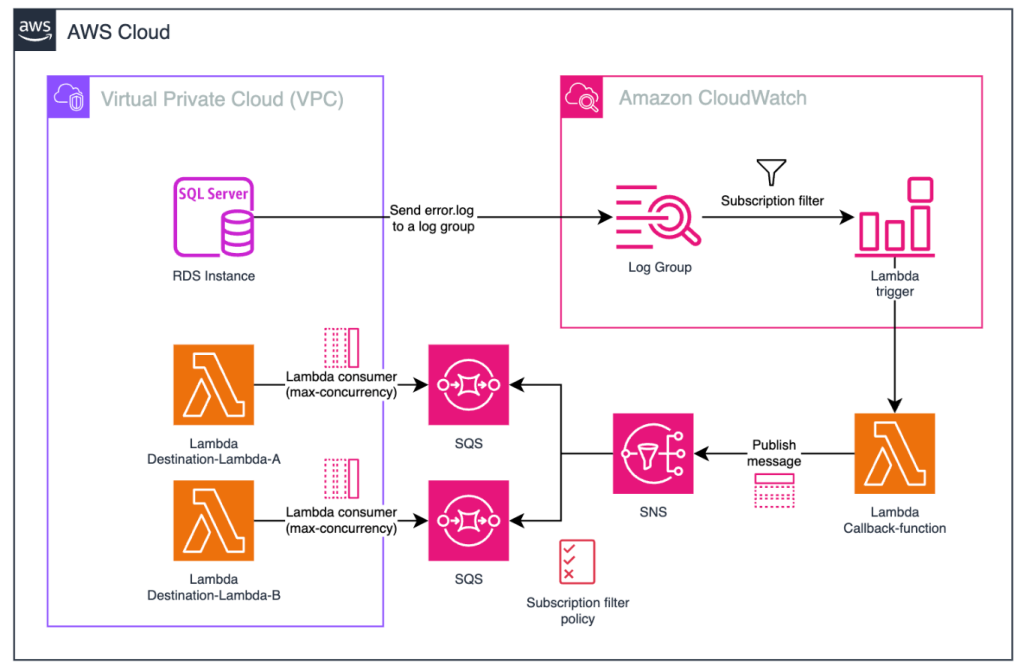
Trigger AWS Lambda functions from Amazon RDS for SQL Server database events
The ability to invoke Lambda functions in response to Amazon RDS for SQL Server database events enables powerful use cases such as triggering automated workflows, sending real-time notifications, calling external APIs, and orchestrating complex business processes. In this post, we demonstrate how to enable this integration by using Amazon CloudWatch subscription filters, Amazon SQS, and Amazon SNS to invoke Lambda functions from RDS for SQL Server stored procedures, helping you build responsive, data-driven applications.
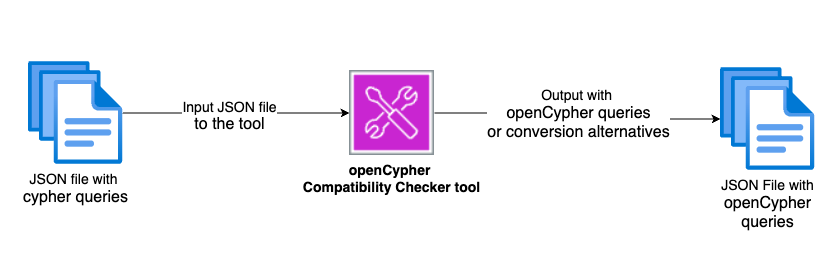
Validate Neo4j Cypher queries for Amazon Neptune migration
In this post, we show you how to validate Neo4j Cypher queries before migrating to Neptune using the openCypher Compatibility Checker tool. You can use this tool to identify compatibility issues early in your migration process, reducing migration time and effort.
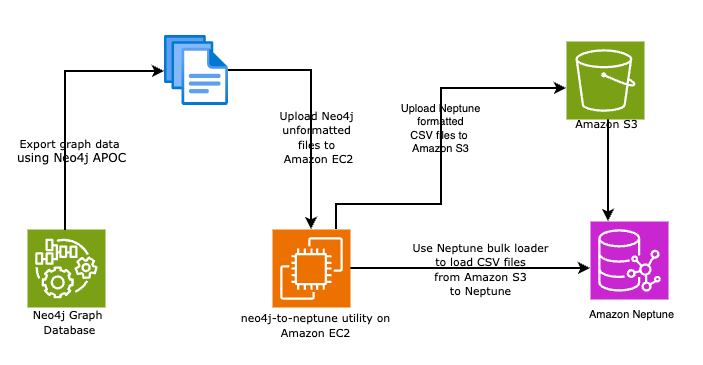
Automate your Neo4j to Amazon Neptune migration using the neo4j-to-neptune utility
In this post, we walk you through two methods to automate your Neo4j database to Neptune using the neo4j-to-neptune utility. This tool offers a fully automated end-to-end process in addition to a step-by-step manual process.

Managing IP address exhaustion for Amazon RDS Proxy
In this post, you will learn how to address IP address exhaustion challenges when working with Amazon RDS Proxy. For customers experiencing IP exhaustion with RDS Proxy, migrating to IPv6 address space can be an effective solution if your workload supports IPv6. This post focuses on workloads that cannot support IPv6 address space and provides an alternative approach using IPv4 subnet expansion. The solution focuses on expanding your Amazon Virtual Private Cloud (Amazon VPC) CIDR range, establishing new subnets, and executing a carefully planned switching of your proxy to a new subnet configuration.

Choosing the right code page and collation for migration from mainframe Db2 to Amazon RDS for Db2
In this post, you learn how to select the appropriate code page and collation sequence when migrating from Db2 mainframe (z/OS) to Amazon RDS for Db2 on Linux. You explore the differences between mainframe CCSIDs and Db2 LUW code pages, understand character compatibility requirements, and discover how to prevent data truncation and maintain consistent sorting behavior across platforms.