AWS Database Blog
How Wiz used Amazon ElastiCache to improve performance and reduce costs
This is a guest post by Sagi Tsofan, Senior Software Engineer at Wiz in partnership with AWS.
![]()
At Wiz, it’s all about scale. Our platform ingests metadata and telemetry for tens of billions of cloud resources every day. Our agentless scanner collects massive amounts of data that needs to be processed very efficiently. As our company grows, we face significant challenges on how to maintain and scale it efficiently. In this post, we describe a technical challenge and solution using Amazon ElastiCache that has improved both our business efficiency and the value we give to our customers.
When Wiz was founded in 2020, we set out to help security teams reduce their cloud risk. We’ve come a long way in a short time, breaking funding, valuation, and ARR records, becoming the fastest growing software as a service (SaaS) company ever to reach the $100 million ARR milestone.
The Wiz platform presents customers with the latest and most updated view of the state of their cloud environment. This means that each change, whether it is the creation of a new cloud resource, a change to an existing cloud resource, or the removal of an existing cloud resource, should be reflected on the Wiz platform as soon as possible.
The following diagram shows the current view of a customer’s cloud account in the Wiz platform.
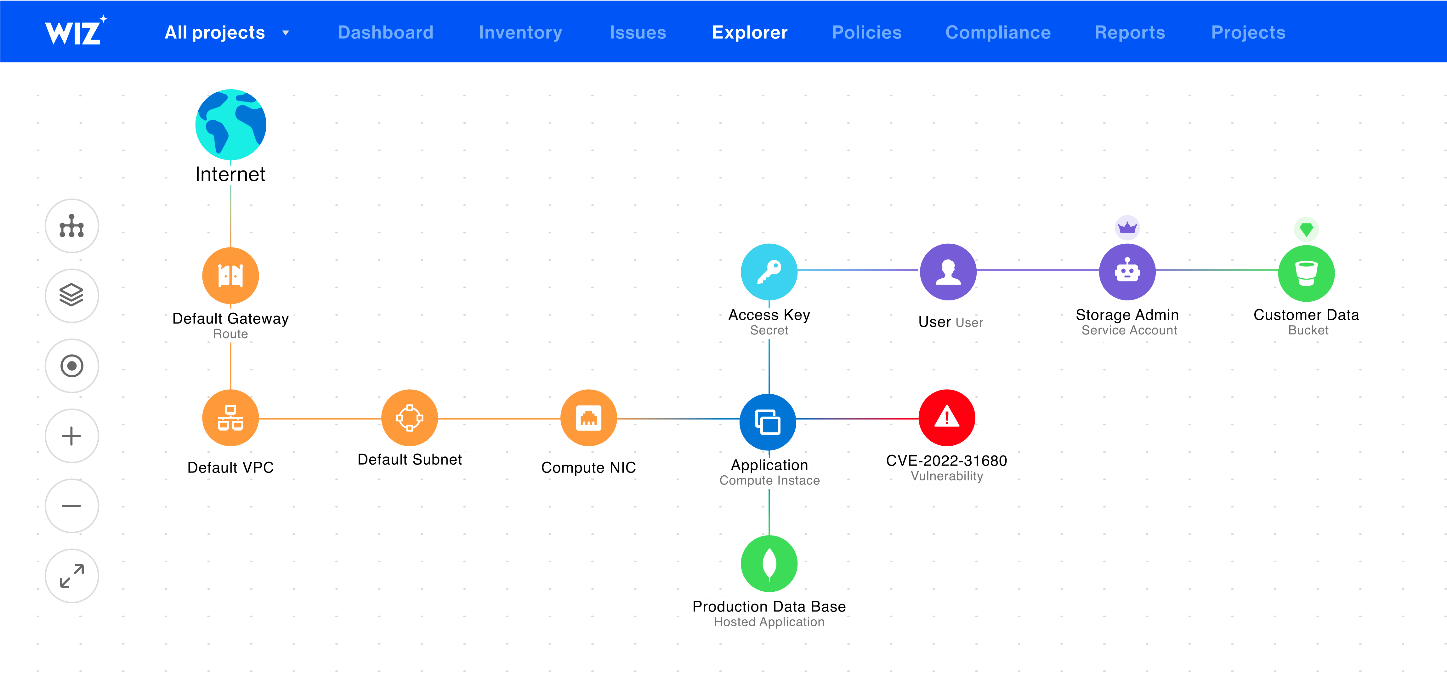
In order to provide this view to our customers, we have implemented an agentless scanner, which frequently scans our customer’s cloud accounts. The scanner’s main task is to catalog all the cloud resources it sees in the customer’s cloud account. Everything from Amazon Elastic Compute Cloud (Amazon EC2) instances to AWS Identity and Access Management (IAM) roles to Amazon Virtual Private Cloud (Amazon VPC) Network Security Groups, and more, is recorded.
The scan results are recorded in the Wiz backend, where each of these cloud resources are ingested through our data pipeline. The steps in this process before we introduced Amazon ElastiCache are shown in the following diagram.
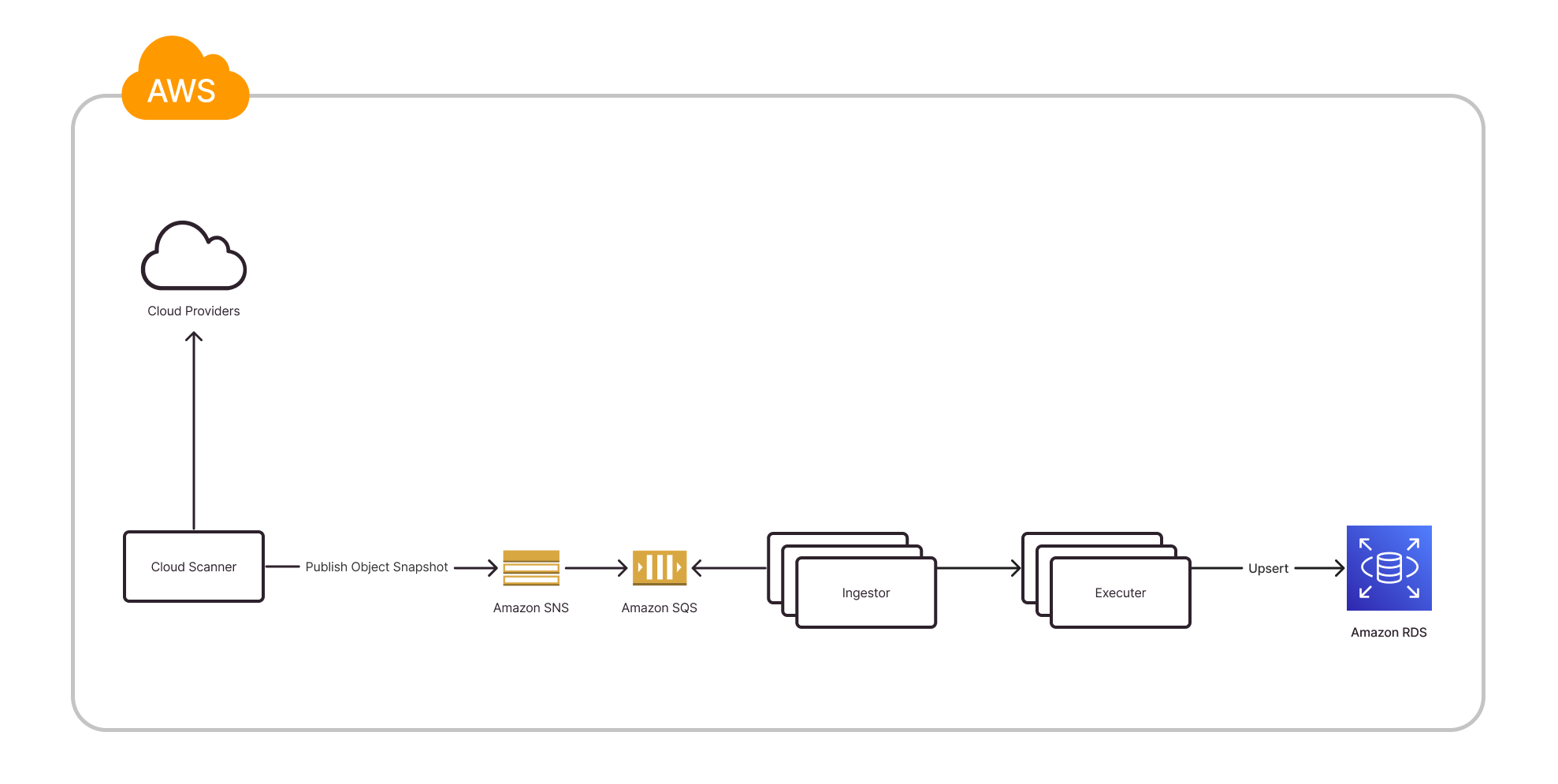
The pipeline consists of the following phases:
- The Cloud Scanner service is triggered on a schedule, initiating a new scan of the customer’s account.
- The scanner enumerates all the cloud resources from the customer cloud account and then publishes information about them to Amazon Simple Queue Service (Amazon SQS) through an Amazon Simple Notification Service (Amazon SNS) topic.
- The ingestors are then responsible for consuming these messages from the SQS queue.
- For each message, a Remote Procedure Call (RPC) is made to the executer component with the relevant cloud resource metadata.
- The Executer’s responsibility is to upsert the cloud resources to the Amazon Aurora PostgreSQL-Compatible Edition database, updating the entire cloud resource metadata including its last seen timestamp and the current scan run ID, which we use later for removing the cloud resources that are no longer seen in the customer’s account.
The challenge
The challenge occurs when we consider the amount of concurrent customers, cloud providers, accounts, subscriptions, workloads, and thousands of concurrent scans all running at the same time.
The Wiz platform ingests tens of billions of updates to cloud resources every day. Previously, we updated every cloud resource’s record after each scan, even if it hadn’t changed since the last scan. We did this because we needed to remember which resources needed to be deleted from the database during step 5, by updating the last seen and run ID values in the resource’s record. This created a lot of additional load on our database.
We needed to think about a more efficient way to calculate which cloud resource needed to be deleted after each scan, while reducing writes to the database.
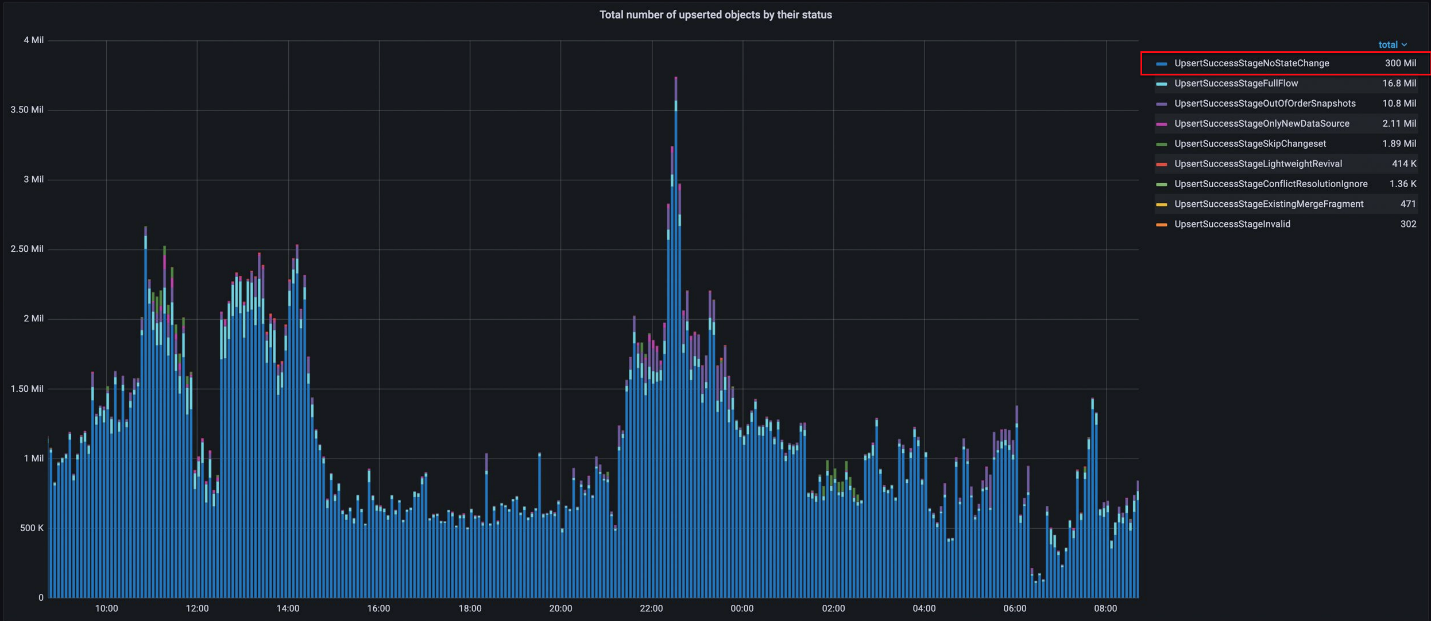
The following diagram shows the total amount of upserted cloud resources grouped by status. For this customer, 90% of the cloud resources haven’t been changed.
Goals
Over the past few months, we implemented a change to optimize our ingestion pipeline. Our main goal was to significantly reduce the number of database writes by avoiding updates when the cloud resources are unchanged. This helps us achieve the following objectives:
- Remove the pressure from the database, which will improve query performance and reduce query latency
- Reduce the consumption of PostgreSQL transaction IDs, and reduce the frequency of autovacuums to avoid transaction ID wraparounds
- Reduce the consumption of CPU, reads, writes, throughput, and IOs
- Right-size the database instance type to optimize cost
ElastiCache to the rescue
Amazon ElastiCache for Redis is a fully managed AWS service. It’s a highly scalable, secure, in-memory caching service that can support the most demanding applications requiring sub-millisecond response times. It also offers built-in security, backup and restore, and cross-region replication capabilities.
We decided to take advantage of Redis’s built-in capabilities and native server-side support for data structures to store and calculate which cloud resources need to be deleted after each scanner runs.
We noticed that this can be achieved by using the Set data model, which is an unordered collection of unique strings, to which data can be added or removed, and which can be compared with other sets.
Each time the scanner observes a cloud resource, its unique identifier is added (using the SADD command) to the current scan run set, so that each scan run will populate its own set key, which eventually will contain all the cloud resource IDs that were observed during the current scan run.
When the scanner finishes and it’s time to calculate which cloud resources should be deleted, we run a comparison (using the SDIFF command) against the previous scan run set. The output of this comparison is a set of cloud resource IDs that need to be deleted from the database. Using ElastiCache’s native support for the Set data type allows us to offload this entire comparison process from our database to the ElastiCache engine.
Let’s examine a basic example:
- Scan 13 published five (new) cloud resources into the set: A, B, C, D, and E
- Scan 14 published four (part new and part existing) cloud resources into the set: A, B, G, and H
- The difference between these scans will be C, D, and E, which means that those are the cloud resources that need to be deleted from the database because they don’t exist anymore
The sets in Redis are populated as follows. For this post, we show how to populate and compare the sets using the Redis CLI.
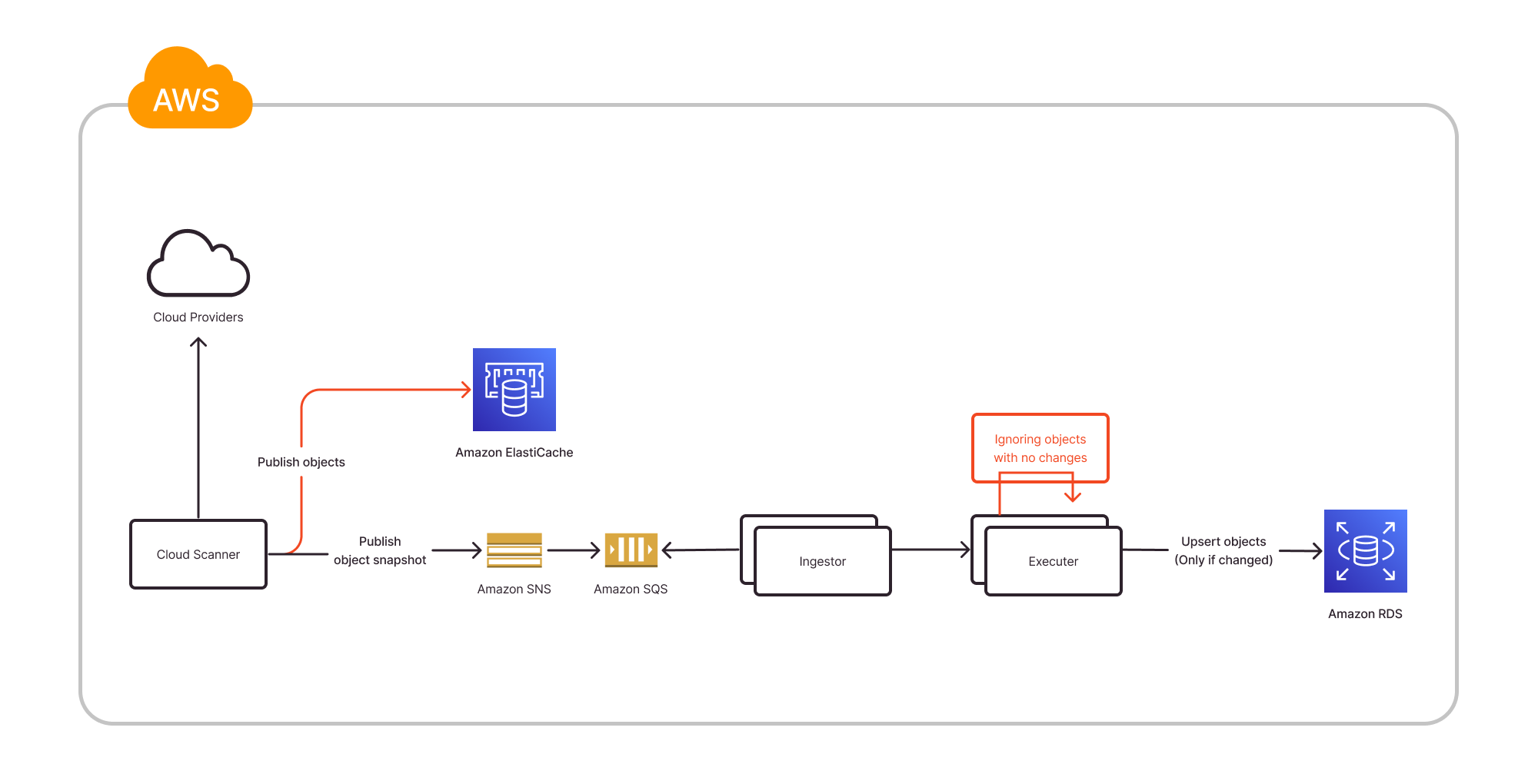
We need to add two new steps, shown in red in the following diagram, to the ingestion pipeline:
- The scanner populates the observed cloud resource IDs into sets in ElastiCache
- The Executer upserts the cloud resources to the database only if we identify an actual cloud resource change since the last scan
The resulting architecture now looks like the following diagram.
When the scanner has finished the account discovery, it sends a “done” message through Amazon SNS and Amazon SQS. The Executer then starts to calculate the difference between the scans using the SDIFF command in Redis, and then deletes the resulting IDs from the database. The following diagram illustrates the deletion flow architecture.
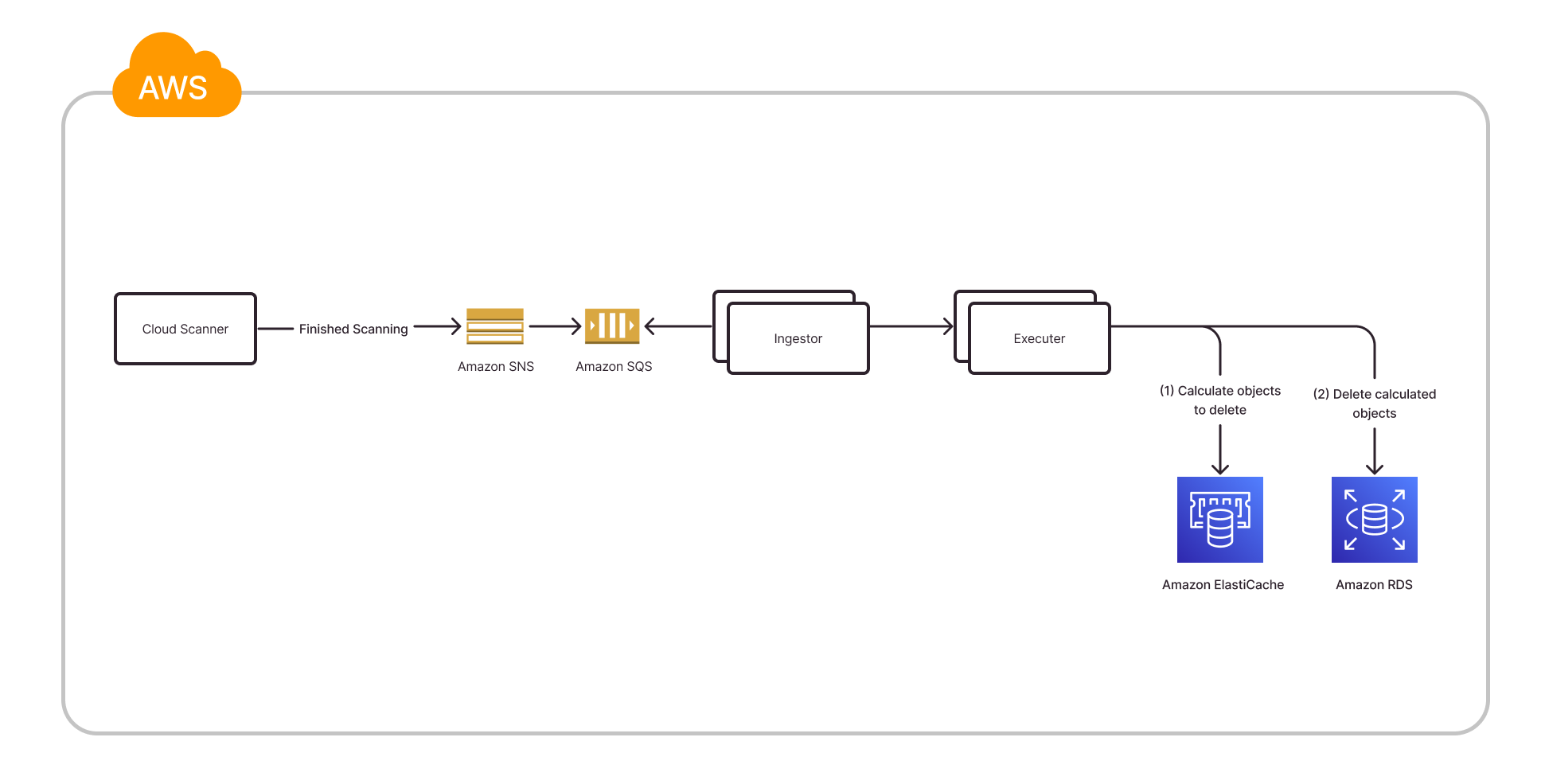
Results
After we deployed the entire change to production, we immediately noticed improvements in our database. Both CPU and memory consumption dropped dramatically, which enabled us to right-size the database instance.
Now, 90% of the cloud resources are skipped without writing to the database at all!

We also observed a corresponding drop in IOs and costs after making the change, as shown in the following AWS Cost Explorer graph.
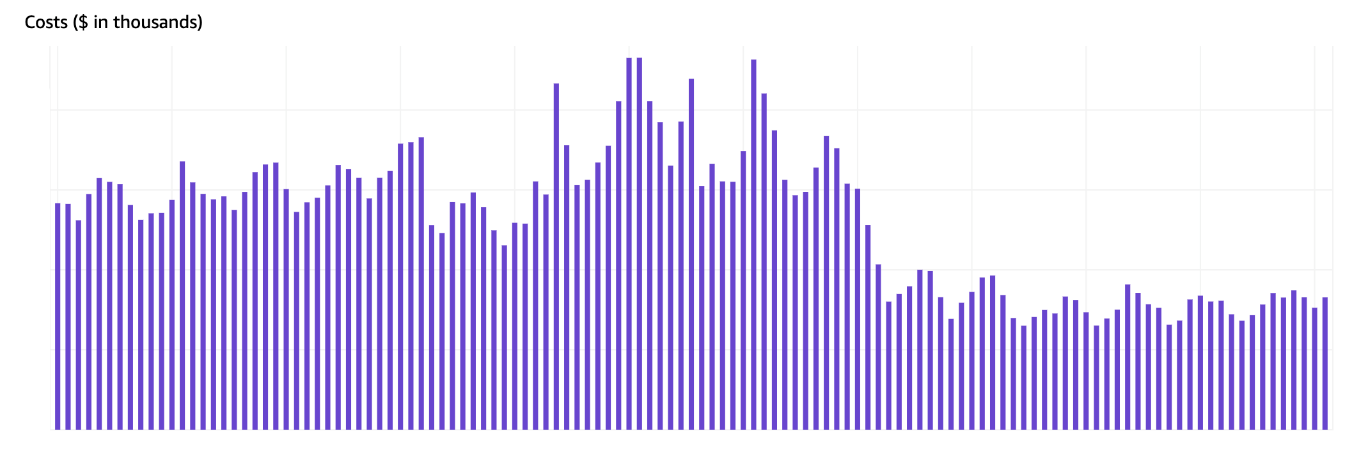
Challenges and lessons learned
During this major infrastructure change, we encountered many challenges, most of which were scaling issues.
Logical sharding
Our scanners enumerate hundreds of millions of cloud resources every scan. Each Redis set can accommodate up to 4 billion items. However, running the SDIFF command on two very large sets consumes a lot of CPU and memory. In our case, running SDIFF on sets with too many entries resulted in our workflow timing out before the comparison could complete.
At the suggestion of the ElastiCache service team, we decided to logically shard our sets. Instead of having one huge set with hundreds of millions of entries, we took advantage of the distributed nature of ElastiCache to split it into several smaller sets, where each contained a portion of the cloud resource IDs. The ElastiCache service team suggested that we put no more than approximately 1.5 million entries in each set. This has resulted in acceptable runtimes for our workload.
The deletion flow now needs to combine and calculate the differences of these multiple sharded sets. The following diagram illustrates the sharding sets structure in ElastiCache: two scans iterations, where each scan sharded the observed cloud resource IDs over multiple sets.

We now must guarantee that we always compare the same sharded sets and store each cloud resource on the same shard. Otherwise, our comparation will cause a corrupted difference result, which can lead to unwanted cloud resource deletions. We accomplish this by deterministically calculating a shard for each cloud resource.
Cluster mode enabled
Because we have a huge number of scans, we also have a huge number of sets, with millions of items inside each one. This much data can’t fit into one ElastiCache node, because we reached the maximum memory size very quickly.
We needed a way to distribute our sets across different shards, and to be able to scale memory without changing the ElastiCache instance class type from time to time.
We decided to migrate to ElastiCache with Cluster Mode Enabled (CME), which enables us to append new shards into the cluster easily whenever we needed more memory.
The migration process from Cluster Mode Disabled to Cluster Mode Enabled includes using a new SDK library, as well as tagging the cache keys to control how groups of keys are located in the same shard.
Pipelines
Redis pipelines are used to improve the performance by running multiple commands all at once without waiting for the response to each individual command.
We adopted the pipelines mechanism to store and batch the commands during scanning, which will be sent to ElastiCache in order to reduce client-server round trips.
This lets us reduce the number of operations per second we perform on the ElastiCache cluster.
Conclusion
By adding ElastiCache in front of our Amazon Aurora PostgreSQL-Compatible Edition database, we improved overall application performance, reduced pressure on our database, were able to right-size our database instances, and saved on overall TCO, all while increasing our scale and handling more customer load.
We eliminated the bulk of our database updates using ElastiCache before the final outcome is stored in the Amazon Aurora PostgreSQL-Compatible Edition database. In so doing, we are taking advantage of each database engine’s strong points. Redis is a great tool for storing high-velocity data, while PostgreSQL is better suited for long-term storage and analysis.
ElastiCache is a critical component in our ingestion pipeline. It lets us scale significantly, allowing us to handle more scans and cloud resource ingestions. By doing that, we managed to improve our database performance, reduce its instance type, and reduce total costs by 30% (including the ElastiCache costs). Additionally, we use ElastiCache reserved nodes to further reduce costs.
About the Authors
 Sagi Tsofan is a Software Engineer in the Wiz engineering team with a primary focus on the product infrastructure and scaling domains. He has over 15 years of experience building large-scale distributed systems with a deep understanding and much experience in the development and architecture of highly scalable solutions for companies like Wiz, Wix, XM Cyber, and IDF. When not in front of screens, he enjoys playing tennis, traveling, and spending time with his friends and family.
Sagi Tsofan is a Software Engineer in the Wiz engineering team with a primary focus on the product infrastructure and scaling domains. He has over 15 years of experience building large-scale distributed systems with a deep understanding and much experience in the development and architecture of highly scalable solutions for companies like Wiz, Wix, XM Cyber, and IDF. When not in front of screens, he enjoys playing tennis, traveling, and spending time with his friends and family.
 Tim Gustafson is a Principal Database Solutions Architect at AWS, focusing on the open-source database engines and Aurora. When not helping customers with their databases on AWS, he enjoys spending time developing his own projects on AWS.
Tim Gustafson is a Principal Database Solutions Architect at AWS, focusing on the open-source database engines and Aurora. When not helping customers with their databases on AWS, he enjoys spending time developing his own projects on AWS.