AWS Database Blog
Improve Business Continuity with Amazon Aurora Global Database
As your business grows increasingly global, your database needs similarly expand. Resources must be just as available to your team in Zurich as they are to your office in Beijing, with the same speed, security, and ease of access. Amazon Aurora Global Database expands your Amazon Aurora database across the planet.
Aurora builds its storage volumes in 10-GB logical blocks called protection groups. It then replicates the data in each protection group across six storage nodes allocated across three Availability Zones in the same Region. If the volume of data exceeds the currently allocated storage, Aurora seamlessly expands the volume to meet the demand and adds new protection groups as necessary.
Aurora Global Database—announced at re:Invent 2018—extends this replication process out to other Regions. This provides faster cross-Region disaster recovery and enables high performance, low lag, cross-Region read scaling. With Aurora Global Database, you can extend your database to multiple Regions with minimal impact on database performance.
This post introduces Aurora Global Database and discusses the benefits and use cases.
What is an Aurora global database?
An Aurora global database spans multiple Regions, providing disaster recovery from Region-wide outages and enabling low-latency global reads.
As a feature of Aurora, Global Database uses dedicated infrastructure in Aurora’s purpose-built storage layer to handle replication across Regions. Dedicated replication servers in the storage layer handle the replication, which grants you enhanced recovery and availability objectives without compromising database performance.
MySQL binary log replication and the storage-based replication used by Aurora Global Database have a few key differences. Logical replication, or binlog replication, records data-modifying statements or row changes on the replication source (primary) and re-applies them on the replication target (replica). The primary and replica databases are separate and independent and can contain different datasets.
On the other hand, Aurora Global Database employs physical storage-level replication to create a replica of the primary database with an identical dataset, which removes any dependency on binary logs. The secondary Region instance of the global database doesn’t replay data-modifying statements. This dramatically reduces replication overhead and leaves more capacity available for application workloads.
This means that committed transactional changes from the writer are replicated globally to the Regions that you select, typically within one second. While the global database handles this replication, the data remains durably stored in three Availability Zones in each Region of your cluster.
Why use global databases?
Aurora Global Database provides several important features:
- Fast global failover to secondary Regions
- Low replication latency across Regions
- Little to no performance impact on your database
- MySQL-compatibility
Fast global failover to secondary Regions
A confident disaster recovery plan allows you to place greater confidence in your business continuity plans in case an unexpected event occurs. Aurora Global Database excels at two important metrics of disaster recovery:
- RTO (recovery time objective) — How long it takes you to return to a working state after a disaster.
- RPO (recovery point objective) — How much data you could lose.
With Aurora Global Database, RPO is less than 5 seconds—minimizing data loss—and RTO is less than one minute, reducing downtime.
Aurora Global Database provides disaster recovery and the ability to continue operating even in the face of a Region-wide failure. An Aurora global database quickly responds to promote a secondary Region during a potential degradation or isolation of your database. With global storage-based replication, this promoted Region can take full read/write workloads in under a minute, minimizing the impact on application uptime.
Low replication latency across Regions
Beyond providing disaster recovery, Aurora Global Database allows you to offload reads from the primary Region to a secondary Region quickly. Aurora Global Database maintains typical replication latencies of less than one second, with an upper bound of 5 seconds. This low latency grants global read scale-out for online transaction processing (OLTP) workloads.
Low latency lets you serve reads closer to (and quicker from) global client applications for optimal user experience and engagement. Customers operating multi-region application stacks that share common configuration data can rely on Aurora Global Database to replicate data almost instantaneously.
If you have multiple offices around the world and a global customer base, you can upload your content in the primary Region and make it available to customers around the world with local latency.
Little to no performance impact on your database
The Aurora Global Database dedicated infrastructure in the Aurora storage layer keeps the database resources provisioned in the primary and secondary Regions fully available to serve application workloads. Aurora replication has limited or no impact on the primary database cluster’s performance.
Fast cross-region migrations
Aurora Global Database can replicate production databases to another AWS Region for application migrations. After Aurora Global Database updates the secondary Region, you detach the replicated database from the Aurora global database and operate it like any other Aurora database cluster. As soon as you connect the now-independent cluster to the Region’s application stack, it begins serving read/write workloads.
MySQL-compatibility
Aurora Global Database is currently available for Amazon Aurora with MySQL compatibility. Application developers benefit from the familiarity and flexibility of open-source databases, even at a global scale.
Create an Aurora global database
You can create an Aurora global database from the AWS Management Console, AWS CLI, or by running the CreateGlobalCluster action from the AWS CLI or SDK. For more information, see Creating an Aurora Global Database.
In the following screenshot, I launched an Aurora global database with the primary cluster in US West 2 (Oregon) and the secondary cluster in US East 1 (N. Virginia). For information about how to add a secondary cluster, see Adding an AWS Region to an Aurora Global Database.
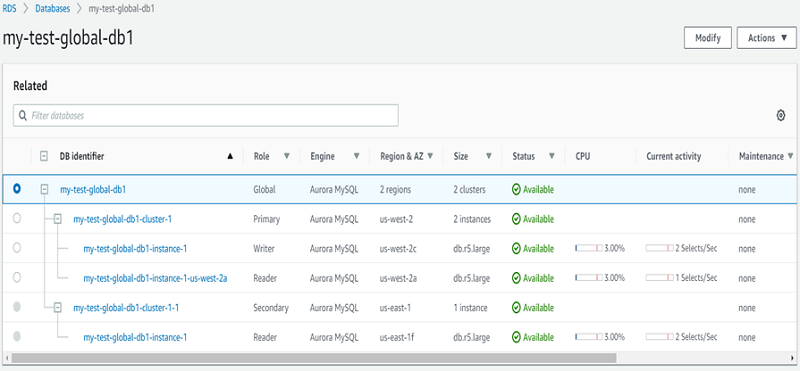
To learn how to remove a cluster from an Aurora global database, perform a failover, or import data, see Working with Amazon Aurora Global Database.
Summary
In this post, I introduced Aurora Global Database. You learned about this feature’s ability to provide fast disaster recovery even in the event of a Region-wide outage, and how it brings data close to your customer applications in different global Regions.
Have follow-up questions or feedback? Let me know at aurora-pm@amazon.com, or leave a comment here. I’d love to hear your thoughts and suggestions.
About the Author

Ahmad Elayat is a product manager for Amazon Aurora at Amazon Web Services.