AWS Database Blog
Migrate data from partitioned tables in PostgreSQL using AWS DMS
Migrating workloads from PostgreSQL to a data warehouse like Amazon Redshift can pose challenges during the change data capture (CDC) phase when dealing with partitioned tables.
In this post, we illustrate how we can migrate data from PostgreSQL partitioned tables to a single table on the target database using AWS Database Migration Service (AWS DMS). We use Amazon Redshift as our target endpoint. However, you can use this process for other target databases as well, such as PostgreSQL, MySQL, and Oracle. We also discuss on how the changes are captured for PostgreSQL partitioned tables during the ongoing changes phase and the role of table mapping in migrating the data.
Solution overview
The solution uses an Amazon RDS for PostgreSQL instance as the source and Amazon Redshift as the target database. The following diagram illustrates the architecture.
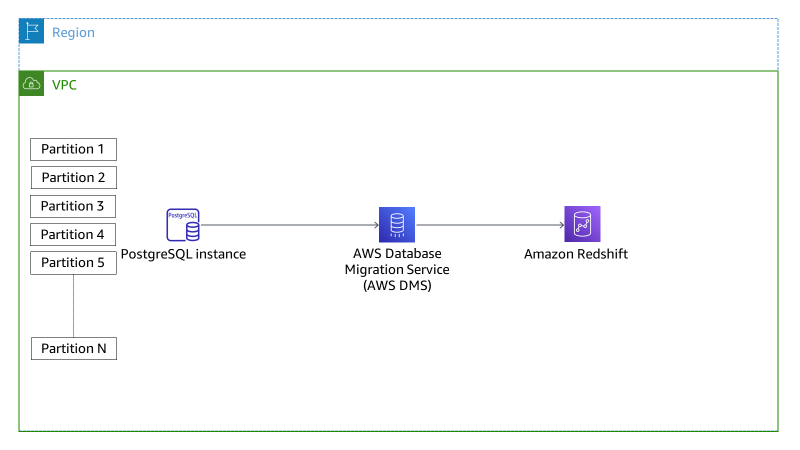
In this scenario, we have set up an AWS DMS task to transfer data from a PostgreSQL instance. The specific table being migrated is called sales, and it is located under the public schema. The sales table has been partitioned into four sections. Our aim is to showcase how data is migrated during the initial load phase and ongoing changes phase using the mapping rules defined on the AWS DMS task.
Prerequisites
To follow along with this post, you should have familiarity with the following AWS services:
- AWS DMS
- Amazon Redshift
- Amazon RDS for PostgreSQL
Additionally, you need an AWS account with sufficient privileges to launch the resources necessary for this solution.
Create the table, partitions, and AWS DMS task
To set up our resources, complete the following steps:
- Use the following table DDL on our source (PostgreSQL) instance to create the
salestable with four partitions:
- Insert the following records as part of the initial load phase:
- Create an AWS DMS task using the option Migrate existing data and replicate ongoing changes.
- Make sure the initial load for the task is complete and in the running state.
- During the ongoing replication phase, insert the following record in the PostgreSQL database:
Now we can investigate how the records will migrate based on the mapping rule.
Investigating data with the table mapping rule including the parent table
We set up the AWS DMS task with the following table mapping to migrate the sales table under the public schema:
We can see from the table statistics that the one record inserted during the ongoing changes phase has not come through (highlighted in red in the following screenshot). However, the four records inserted during the initial load phase have come through (highlighted in green).

Investigating data with the table mapping rule including the partitioned tables
We create another AWS DMS task with the following table mapping to migrate the partitioned table using the wildcard sales_p_%, which encompasses all the partitions of the sales table under the public schema. We perform the same insert operation as before (four inserts during the initial load phase and one record during the ongoing phase). See the following code:
We can see in the following screenshot that one insert was recorded by the AWS DMS task in addition to the four records that were inserted during the initial load phase. However, we can see that the four tables were created on Amazon Redshift: sales_p_q1, sales_p_q2, sales_p_q3, and sales_p_q4.

The reason the DML change was recorded in this AWS DMS task is because the Write-Ahead Log (WAL) records the information under the specific partition. This can be seen by querying the replication slot using the test decoding plugin and pg_logical_slot_peek_changes function, as shown in the following screenshot.

Including the parent table in the mapping rule doesn’t result in changes being replicated during the CDC phase. However, when the partitioned tables are included in the mapping rule, the changes are replicated during the CDC phase. This results in AWS DMS creating separate tables based on the partitions defined on the source.
There are two proposed solutions to migrate all the data from partitioned tables on the source into a single table on the target:
- Use a single AWS DMS task – To accomplish this, we modify the mapping rules for the AWS DMS task to include all the partitioned tables on the source, and consolidate the data from all partitions into a single table on the target.
- Use separate AWS DMS tasks – With this option, we use multiple tasks to migrate data from the partitioned tables on the source to a single table on the target. In the first AWS DMS task, we migrate the data from the parent table to the desired table on the target. We then use a second AWS DMS task to consolidate the data from all the partitions of the parent table into the single aforementioned table on the target. This approach requires additional effort and resources as compared to the first option; however, it allows us to keep the initial load and CDC processes separate.
The first solution is suitable when you have to perform both the initial load and replication of ongoing changes using a single AWS DMS task. The second solution is appropriate when you have to use separate AWS DMS tasks for the initial load and CDC processes.
Combine the initial load and CDC into a single task
We create a task to migrate existing data and replicate ongoing changes with the following steps:
- Create a single table on Amazon Redshift.
- Use the following mapping rule while creating the AWS DMS task:
Separate the initial load and CDC into different tasks
To separate the phases into different tasks, complete the following steps:
- Create a task to migrate the existing data with the parent table (
salesunder the public schema):
- Create a task to replicate changes only. For instructions, refer to To use a new replication slot not previously created as part of another DMS task.
Note that to create a task to replicate changes only, you need to pre-create a replication slot. Make sure you provide the endpoint settings and extra connection attributes: PluginName=pglogical;slotName=<Created Slot Name>;
- Use the following table mapping rule while creating the AWS DMS task:
With the preceding mapping rule, AWS DMS combines changes from partitioned tables on the source into a single table on the target. The following screenshot shows the records on the target.

Summary
In this post, we demonstrated how to migrate a partitioned table from PostgreSQL into a single table on Amazon Redshift by using table mappings. We also highlighted why we need to use the partition tables in the table mappings for replication as opposed to only using the parent table. We then presented two solutions: one with a single AWS DMS task to perform the initial load and ongoing changes, and the other separating the initial load and ongoing replication into different tasks. With this post, you should be able to develop a strategy to successfully migrate all your partitioned tables from PostgreSQL.
To familiarize yourself more with AWS DMS, visit Getting started with AWS Database Migration Service. Please share your thoughts in the comments section on how this approach worked for you or your customers.
About the Authors
 Prabhu Ayyakkannu is a Data Migration Specialist Solutions Architect at Amazon Web Services. He works on challenges related to data migrations and works closely with customers to help them realize the true potential of AWS Database Migration Service (DMS).
Prabhu Ayyakkannu is a Data Migration Specialist Solutions Architect at Amazon Web Services. He works on challenges related to data migrations and works closely with customers to help them realize the true potential of AWS Database Migration Service (DMS).
 Suchindranath Hegde is a Data Migration Specialist Solutions Architect at Amazon Web Services. He works with our customers to provide guidance and technical assistance on data migration into the AWS Cloud using Database Migration Service (DMS).
Suchindranath Hegde is a Data Migration Specialist Solutions Architect at Amazon Web Services. He works with our customers to provide guidance and technical assistance on data migration into the AWS Cloud using Database Migration Service (DMS).
 Alex Anto is a Data Migration Specialist Solutions Architect with the Amazon Database Migration Accelerator team at Amazon Web Services. He works as an Amazon DMA Advisor to help AWS customers to migrate their on-premises data to AWS Cloud database solutions.
Alex Anto is a Data Migration Specialist Solutions Architect with the Amazon Database Migration Accelerator team at Amazon Web Services. He works as an Amazon DMA Advisor to help AWS customers to migrate their on-premises data to AWS Cloud database solutions.