Configure the Spring Boot application to support PostgreSQL and JSON data types
If you’re familiar with setting up a database connection in a Spring Boot application, you can skip this section.
To connect to a PostgreSQL database, you can add two dependencies to the project maven build file pom.xml: the PostgreSQL JDBC (Java Database Connectivity) driver and an open-source Hibernate type library, as shown in the following code. The Hibernate type library provides JSON type support, which isn’t available in the core package of the Hibernate object relational mapping framework (ORM). The Spring Data Java Persistence API (JPA) uses the Hibernate ORM as the default object relational mapping provider.
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>com.vladmihalcea</groupId>
<artifactId>hibernate-types-52</artifactId>
<version>${hibernate-types.version}</version>
</dependency>
Create Spring Profiles to connect to a PostgreSQL database on AWS
If you’re familiar with Spring Profiles and their usage, you can skip this section.
You can create different Spring Profiles for an application to deploy and run the application on different environments, such as one profile to run and test the application locally and one profile to deploy and run the application as a container service in AWS Fargate. Each profile configures the application with the properties suitable for the environment represented by the profile. You can also use the @Profile annotation to map different beans to different profiles.
To connect to your PostgreSQL database, you can modify the profile property files as follows. You may get the database connection information from your database administrator.
spring.datasource.url = jdbc:postgresql://<rds_hostname>:<rds_port>/<rds_database_name>
spring.datasource.username = <rds_username>
spring.datasource.password = <rds_password>
Create database access classes and a Spring Boot service bean
To access the model table created in the PostgreSQL database, you create a JPA entity class. The entity class uses the following annotations:
- @Id – Indicates that the property is a primary key
- @Type(type=”jsonb”) – Specifies that the property uses the jsonb database type in the PostgreSQL database
Review the following code:
@TypeDefs({
@TypeDef(name="jsonb", typeClass = JsonBinaryType.class)
})
@Entity
@Table(name= "model", schema="demo")
public class Model implements Serializable {
@Id
@Column(name = "id")
@JsonProperty("id")
private long id;
@Column(name = "name")
@JsonProperty("name")
private String name;
@Column(name = "version")
@JsonProperty("version")
private Integer version;
@Type(type="jsonb")
@Column(name = "definition_json", columnDefinition = "jsonb")
@JsonProperty("definitionJson")
private Map<String, Object> definitionJson;
}
To store and retrieve information from the table model, you create an extension of the JpaRepository interface. The interface contains the API definitions for creating, reading, updating, deleting, pagination, and sorting operations.
@Repository
public interface ModelRepository extends JpaRepository<Model, Long> {
}
You can then use the spring @Service annotation to create a service provider ModelService.java to implement the business functions to save and retrieve data processing pipeline models.
The saveModel method creates a model object based on an input data transfer object (DTO) modelDto. The DTO represents the sample JSON data in an object format. The method uses the ModelRepository to save the model to the PostgreSQL database table. See the following code:
@AllArgsConstructor
@NoArgsConstructor
@Builder
@Setter
@Getter
public class ModelDto implements Serializable {
@AllArgsConstructor
@NoArgsConstructor
@Builder
@Setter
@Getter
public static class Item implements Serializable {
@JsonProperty("type")
private String type;
}
@AllArgsConstructor
@NoArgsConstructor
@Builder
@Setter
@Getter
public static class Parameter implements Serializable {
@JsonProperty("display")
private String display;
@JsonProperty("type")
private String type;
@JsonProperty("items")
private Item items;
}
@AllArgsConstructor
@NoArgsConstructor
@Builder
@Setter
@Getter
public static class Definition implements Serializable {
@JsonProperty(value = "metaData", required = true)
private ModelMetaInfo metaData;
@JsonProperty(value = "inputParameters", required = true)
private Map<String, Parameter> inputParameters;
@JsonProperty(value = "outputParameters", required = true)
private Map<String, Parameter> outputParameters;
}
@JsonProperty(value = "id", required = true)
private long id;
@JsonProperty(value = "name", required = true)
private String name;
@JsonProperty(value = "version", required = true)
private int version;
@JsonProperty(value = "definition", required = true)
private Definition definition;
}
The getModelListByFilter method queries the PostgreSQL database table and returns a list of models matching with the input filter. The PostgreSQL database provides functions and operators to extract JSON data items and perform value comparisons. The query uses the operator @> to check if the definition_json column field in the PostgreSQL database table contains the right JSON entries defined by the filter. Review the following code:
@Service
public class ModelService {
private static final String FILTER_MODEL_SQL =
"select id, name, version, definition_json from demo.model where definition_json @> '%s'";
@PersistenceContext
private EntityManager entityManager;
private final ModelRepository modelRepository;
public ModelService(ModelRepository modelRepository) {
this.modelRepository = modelRepository;
}
public Model saveModel(ModelDto modelDto) {
try {
Model model = Model.builder().name(modelDto.getName()).id(modelDto.getId())
.version(modelDto.getVersion())
.definitionJson(JsonUtil.objectToMap(modelDto.getDefinition())).build();
return modelRepository.save(model);
} catch (IOException e) {
throw new InternalProcessingException(e.getMessage());
}
}
public List<Model> getModelListByFilter(ModelFilter filter) {
try {
String sql = String.format(FILTER_MODEL_SQL, JsonUtil.toString(filter));
Query query = entityManager.createNativeQuery(sql, Model.class);
return query.getResultList();
} catch (IOException e) {
throw new InternalProcessingException(e.toString());
}
}
}
As an example, you can use the following filter to find the models belonging to the catalog machine learning and suitable for use in the year 2021:
{
"metaData": {
"catalogs": ["machine learning"],
"years": [2021]
}
}
Based on the filter value, the getModelListByFilter method generates the following SQL statement:
select id, name, version, definition_json from demo.model
where definition_json @> '{"metaData":{"catalogs":["machine learning"],"years":[2021]}}'
Create REST APIs to load and retrieve JSON business data
You can add a REST controller called ModelController.java to implement two REST APIs: one for loading models and one for filtering and finding matching models. Review the following code:
@RestController
@RequestMapping("/models")
public class ModelController {
private final ModelService modelService;
public ModelController(ModelService modelService) {
this.modelService = modelService;
}
@PostMapping(value = "", consumes = MediaType.APPLICATION_JSON_VALUE, produces = MediaType.APPLICATION_JSON_VALUE)
public @ResponseBody ResponseEntity<ModelResponse> registerModel(@RequestBody ModelDto modelDto) {
Model model = modelService.saveModel(modelDto);
return new ResponseEntity<>(ModelResponse.builder().data(model).status(HttpStatus.CREATED).build(),
HttpStatus.CREATED);
}
@PostMapping(value = "/filter", consumes = MediaType.APPLICATION_JSON_VALUE, produces = MediaType.APPLICATION_JSON_VALUE)
public @ResponseBody ResponseEntity<ModelListResponse> filterModels(@RequestBody ModelFilter modelFilter) {
List<Model> modelInfoList = modelService.getModelListByFilter(modelFilter);
return new ResponseEntity<>(ModelListResponse.builder().data(modelInfoList).status(HttpStatus.OK).build(),
HttpStatus.OK);
}
}
The REST controller uses the DTOs ModelResponse and ModelListResponse:
@AllArgsConstructor
@NoArgsConstructor
@SuperBuilder
@Getter
@Setter
public class ModelResponse {
protected HttpStatus status;
protected String message;
private Model data;
}
@AllArgsConstructor
@NoArgsConstructor
@SuperBuilder
@Getter
@Setter
public class ModelListResponse {
protected HttpStatus status;
protected String message;
private List<Model> data;
}
While our post focuses on using and supporting JSON data in Amazon RDS for PostgreSQL and Spring Boot applications, you must take additional steps to properly secure applications for production deployment. We recommend securing your application using Spring Security.
Test the REST APIs
Postman is a popular API platform used by developers to design, build, and test APIs. You can use Postman to create two requests to test two APIs created in the REST controller ModelController.java, as shown in the following code. You need to replace the variable your_service_url in the HTTP requests with the root path for the REST controller ModelController.java.
HTTP Request for loading the sample model
POST {{your_service_url}}/models Body Typ JSON Body Content { "id": 1, "name": "testModel", "version": 1, "definition": { "metaData": { "catalogs": [ "machine learning", "classification", "duplicate detection" ], "years": [ 2021, 2022 ], "author": "Test Users", "name": "Duplicate Detection", "container": "duplicate-detection:1.0" }, "inputParameters": { "startDate": { "display": "Start Date", "type": "date-time" }, "endDate": { "display": "End Date", "type": "date-time" } }, "outputParameters": { "result": { "type": "array", "items": { "type": "string" } } } } }
HTTP Request for filtering and finding models
POST {{your_service_url}}/models/filter Body Type JSON Body Content { "metaData": { "catalogs": ["machine learning"], "years": [2021] } }
Create an index to improve query performance
We use the following schema and table to show you how to improve the query performance of the jsonb data type:
CREATE SCHEMA IF NOT EXISTS demo;
CREATE TABLE IF NOT EXISTS demo.model
(id SERIAL PRIMARY KEY,
definition_json jsonb,
name character varying(255),
version integer);
We populate 2 million rows of data into the table demo.model.
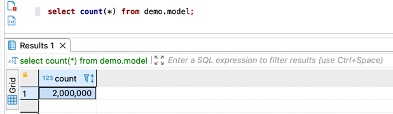
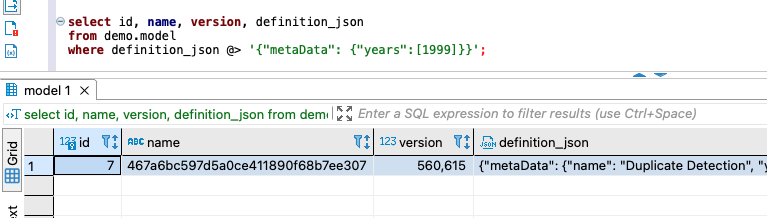
We run the following query, which uses the @> operator to search the JSON’s keys and their values:
select id, name, version, definition_json
from demo.model
where definition_json @> '{"metaData": {"years":[1999]}}';
The following screenshot shows the query result matching one record.
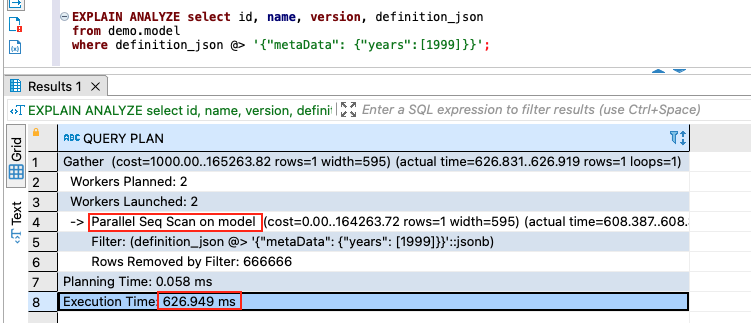
Then, we use the explain analyze command to find the query’s run plan:
EXPLAIN ANALYZE select id, name, version, definition_json
from demo.model
where definition_json @> '{"metaData": {"years":[1999]}}';
Because there is no index created for the column definition_json, the query plan shows Parallel Seq Scan on model. On our testing platform, the runtime is 626.949 milliseconds.
We follow up by modifying the PostgreSQL database by adding a generalized inverted index ( GIN) to the column definition_json using the following SQL statement:
create index idx_definition_json on
demo.model using gin (definition_json);
Then we rerun the same explain analyze command to find the query’s run plan.
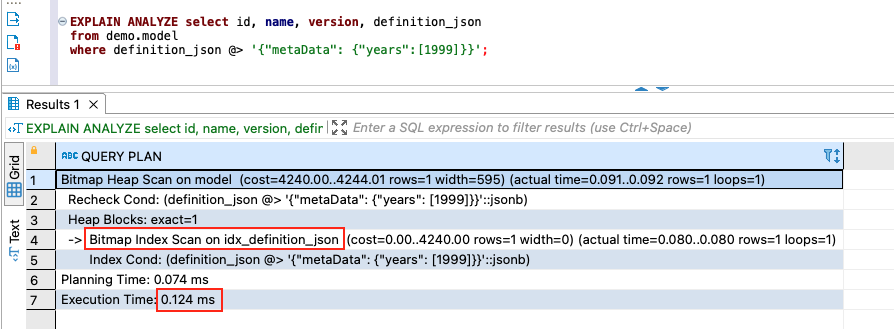
After we create the index idx_definition_json, the new query plan shows Bitmap Index Scan on idx_definition_json. On our testing platform, the runtime is only 0.124 milliseconds. The query’s performance has improved dramatically—it’s 5,056 times faster.
GIN indexes cause additional costs for write operations. You may want to avoid using GIN indexes if your table operations are write-heavy. In our test, loading 2 million records with the index idx_definition_json takes 106 seconds. Without the index, the same loading operation takes 31 seconds. Before adding GIN indexes to database tables, you may want to analyze the database operations used by your applications and test the performance impact of the indexes on your application.
We run another query with two combined keys: "catalogs":["machine learning"] and "years":[1999] under metadata:
EXPLAIN ANALYZE select id, name, version, definition_json
from demo.model
where definition_json @> '{"metaData":{"catalogs":["machine learning"],"years":[1999]}}'
The following screenshot shows the query and its run plan.
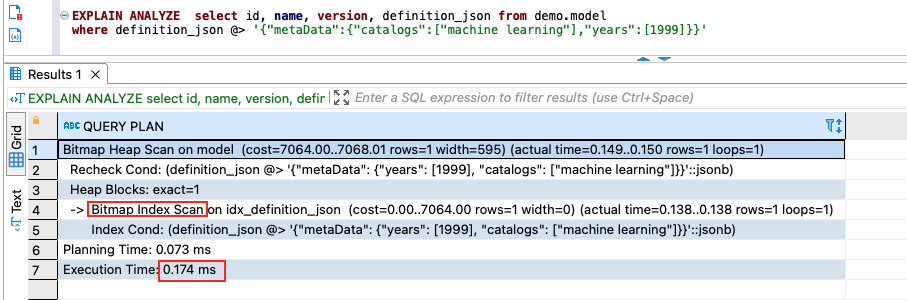
Our tests show that GIN indexes can be used to efficiently search for keys or key/value pairs occurring within a large number of jsonb documents.
Conclusion
In this post, we showed how to create a jsonb data column in Amazon RDS for PostgreSQL to store your business data and how to create an index to improve query performance. We also illustrated how to connect to your PostgreSQL database to load and query JSON data using the popular Spring Boot Java framework. You can apply the same approach to Aurora PostgreSQL.
If you have questions or suggestions, leave them in the comments section below.
About the authors
 Jeff Li is a Senior Cloud Application Architect with the Professional Services team at AWS. He is passionate about diving deep with customers to create solutions and modernize applications that support business innovations. In his spare time, he enjoys playing tennis, listening to music, and reading.
Jeff Li is a Senior Cloud Application Architect with the Professional Services team at AWS. He is passionate about diving deep with customers to create solutions and modernize applications that support business innovations. In his spare time, he enjoys playing tennis, listening to music, and reading.
 Shunan Xiang is a Senior Database Consultant with the Professional Services team at AWS. He works as a database migration specialist to help Amazon customers in design and implementing scalable, secure, performant, and robust database solutions on the cloud. He also develops custom Data Lake House for the customer to support end-to-end supply chain integration.
Shunan Xiang is a Senior Database Consultant with the Professional Services team at AWS. He works as a database migration specialist to help Amazon customers in design and implementing scalable, secure, performant, and robust database solutions on the cloud. He also develops custom Data Lake House for the customer to support end-to-end supply chain integration.