AWS DevOps & Developer Productivity Blog
Integrate GitHub monorepo with AWS CodePipeline to run project-specific CI/CD pipelines
AWS CodePipeline is a continuous delivery service that enables you to model, visualize, and automate the steps required to release your software. With CodePipeline, you model the full release process for building your code, deploying to pre-production environments, testing your application, and releasing it to production. CodePipeline then builds, tests, and deploys your application according to the defined workflow either in manual mode or automatically every time a code change occurs. A lot of organizations use GitHub as their source code repository. Some organizations choose to embed multiple applications or services in a single GitHub repository separated by folders. This method of organizing your source code in a repository is called a monorepo.
This post demonstrates how to customize GitHub events that invoke a monorepo service-specific pipeline by reading the GitHub event payload using AWS Lambda.
Solution overview
With the default setup in CodePipeline, a release pipeline is invoked whenever a change in the source code repository is detected. When using GitHub as the source for a pipeline, CodePipeline uses a webhook to detect changes in a remote branch and starts the pipeline. When using a monorepo style project with GitHub, it doesn’t matter which folder in the repository you change the code, CodePipeline gets an event at the repository level. If you have a continuous integration and continuous deployment (CI/CD) pipeline for each of the applications and services in a repository, all pipelines detect the change in any of the folders every time. The following diagram illustrates this scenario.

This post demonstrates how to customize GitHub events that invoke a monorepo service-specific pipeline by reading the GitHub event payload using Lambda. This solution has the following benefits:
- Add customizations to start pipelines based on external factors – You can use custom code to evaluate whether a pipeline should be triggered. This allows for further customization beyond polling a source repository or relying on a push event. For example, you can create custom logic to automatically reschedule deployments on holidays to the next available workday.
- Have multiple pipelines with a single source – You can trigger selected pipelines when multiple pipelines are listening to a single GitHub repository. This lets you group small and highly related but independently shipped artifacts such as small microservices without creating thousands of GitHub repos.
- Avoid reacting to unimportant files – You can avoid triggering a pipeline when changing files that don’t affect the application functionality (such as documentation, readme, PDF, and .gitignore files).
In this post, we’re not debating the advantages or disadvantages of a monorepo versus a single repo, or when to create monorepos or single repos for each application or project.
Sample architecture
This post focuses on controlling running pipelines in CodePipeline. CodePipeline can have multiple stages like test, approval, and deploy. Our sample architecture considers a simple pipeline with two stages: source and build.
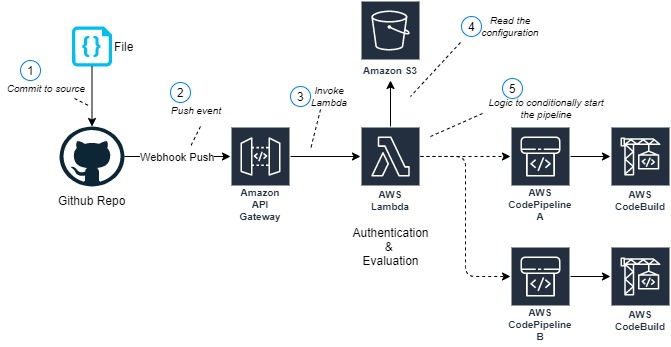
This solution is made up of following parts:
- An Amazon API Gateway endpoint (3) is backed by a Lambda function (5) to receive and authenticate GitHub webhook push events (2)
- The same function evaluates incoming GitHub push events and starts the pipeline on a match
- An Amazon Simple Storage Service (Amazon S3) bucket (4) stores the CodePipeline-specific configuration files
- The pipeline contains a build stage with AWS CodeBuild
Normally, after you create a CI/CD pipeline, it automatically triggers a pipeline to release the latest version of your source code. From then on, every time you make a change in your source code, the pipeline is triggered. You can also manually run the last revision through a pipeline by choosing Release change on the CodePipeline console. This architecture uses the manual mode to run the pipeline. GitHub push events and branch changes are evaluated by the Lambda function to avoid commits that change unimportant files from starting the pipeline.
Creating an API Gateway endpoint
We need a single API Gateway endpoint backed by a Lambda function with the responsibility of authenticating and validating incoming requests from GitHub. You can authenticate requests using HMAC security or GitHub Apps. API Gateway only needs one POST method to consume GitHub push events, as shown in the following screenshot.

Creating the Lambda function
This Lambda function is responsible for authenticating and evaluating the GitHub events. As part of the evaluation process, the function can parse through the GitHub events payload, determine which files are changed, added, or deleted, and perform the appropriate action:
- Start a single pipeline, depending on which folder is changed in GitHub
- Start multiple pipelines
- Ignore the changes if non-relevant files are changed
You can store the project configuration details in Amazon S3. Lambda can read this configuration to decide what needs to be done when a particular folder is matched from a GitHub event. The following code is an example configuration:
{
"GitHubRepo": "SampleRepo",
"GitHubBranch": "main",
"ChangeMatchExpressions": "ProjectA/.*",
"IgnoreFiles": "*.pdf;*.md",
"CodePipelineName": "ProjectA - CodePipeline"
}
For more complex use cases, you can store the configuration file in Amazon DynamoDB.
The following is the sample Lambda function code in Python 3.7 using Boto3:
def lambda_handler(event, context):
import json
modifiedFiles = event["commits"][0]["modified"]
#full path
for filePath in modifiedFiles:
# Extract folder name
folderName = (filePath[:filePath.find("/")])
break
#start the pipeline
if len(folderName)>0:
# Codepipeline name is foldername-job.
# We can read the configuration from S3 as well.
returnCode = start_code_pipeline(folderName + '-job')
return {
'statusCode': 200,
'body': json.dumps('Modified project in repo:' + folderName)
}
def start_code_pipeline(pipelineName):
client = codepipeline_client()
response = client.start_pipeline_execution(name=pipelineName)
return True
cpclient = None
def codepipeline_client():
import boto3
global cpclient
if not cpclient:
cpclient = boto3.client('codepipeline')
return cpclient
Creating a GitHub webhook
GitHub provides webhooks to allow external services to be notified on certain events. For this use case, we create a webhook for a push event. This generates a POST request to the URL (API Gateway URL) specified for any files committed and pushed to the repository. The following screenshot shows our webhook configuration.

Conclusion
In our sample architecture, two pipelines monitor the same GitHub source code repository. A Lambda function decides which pipeline to run based on the GitHub events. The same function can have logic to ignore unimportant files, for example any readme or PDF files.
Using API Gateway, Lambda, and Amazon S3 in combination serves as a general example to introduce custom logic to invoke pipelines. You can expand this solution for increasingly complex processing logic.
About the Author

Vivek is a Solutions Architect at AWS based out of New York. He works with customers providing technical assistance and architectural guidance on various AWS services. He brings more than 23 years of experience in software engineering and architecture roles for various large-scale enterprises.

Gaurav is a Solutions Architect at AWS. He works with digital native business customers providing architectural guidance on AWS services.

Nitin is a Solutions Architect at AWS. He works with digital native business customers providing architectural guidance on AWS services.