AWS HPC Blog
Dynamic HPC budget control using a core-limit approach with AWS ParallelCluster
 Cloud computing provides an experience similar to uncapped or unlimited resources for HPC workloads, helping organizations to accelerate research and development. When using cloud, the business owner typically allocates a fixed annual budget for HPC resources. The budget then needs to be split by multiple groups, across departments, business units, or projects.
Cloud computing provides an experience similar to uncapped or unlimited resources for HPC workloads, helping organizations to accelerate research and development. When using cloud, the business owner typically allocates a fixed annual budget for HPC resources. The budget then needs to be split by multiple groups, across departments, business units, or projects.
But while budgets are fixed, HPC workload needs fluctuate throughout the year for nearly everyone. That’s challenging, and can often make the shift to cloud too much of a puzzle for some.
In this post, we’ll describe a solution for managing your budget using a dynamic Amazon Elastic Compute Cloud (Amazon EC2) core allocation limit for each group asking for HPC resources. It automatically sets the resource limit for each group every week based on the spending of that group in the previous week. The solution can be easily customized and enhanced to meet the specific workload and environmental needs.
HPC in the cloud is different, yet familiar
Budget management for HPC in the cloud can be challenging because it presents a different set of problems than most customers are used to.
Due to project deadlines, HPC workloads must have Quality of Service (QoS) configured in the workload scheduler. When HPC workloads are executed through the workload scheduler as jobs, each job has a run-time and a number of required CPU cores. The QoS is managed by both the cloud resource provider and the HPC workload scheduler. To make this work requires integration between the workload scheduler and the cloud resource provisioning.
HPC workloads frequently spike, or have unexpected deadlines. Budget decisions might be subject to revisions and adaptations over time, as well as accommodating new projects that pop-up anytime during the budget year.
Generic cloud budget control services like AWS Budgets are often too coarse-grained for HPC workloads. Without some effort, they can’t provide the necessary insights to track usage and cost details for HPC jobs running on shared nodes, and it’s hard for them to adapt quickly to HPC workload changes that the business requires.
Finally, although Reserved Instances and Savings Plans can provide up to 72% discount for stable workloads, fluctuating HPC workloads may still need to use the on-demand pay–per–use pricing model.
Our solution
To manage budgets in this environment, the EC2 core allocation limit can be enforced by the HPC workload scheduler. This has a key advantage: it’s a familiar mechanism you’ve probably used elsewhere, which is easy to measure.
It works like this: HPC jobs from a group that would exceed their weekly quota limit will be kept in the queue in pending status until cores are released by finished jobs. An appropriate job pending reason can be provided, making business or job owners aware of their spending implications. Since the cloud provides a “virtually unlimited” capacity, urgent jobs can still be run by shifting a budget up.
For our purposes, we’ll configure the core allocation limit based on physical CPU cores rather vCPUs, because many HPC applications perform better with the hyperthreading disabled, and more customers are used to working this way.
We tested our solution with AWS ParallelCluster 3.5+ with SLURM and job accounting enabled. You can get a complete ParallelCluster environment, with Slurm accounting enabled from the HPC Recipes Library. If this works for you, you can adapt the recipes for your own purposes by customizing them to suit your local needs.
Overview of the solution
To calculate past spending, we query data from AWS Cost Explorer, and calculate the spending of each subgroup in the past week. We then compare the result with the allocated budget of the subgroup, and set the EC2 core limit of the subgroup in the coming week. This is implemented by a weekly cron task running on the cluster head node.
The solution consists of a configuration files and a weekly script run from cron.
The configuration file, located on the HPC head node, lists the weekly budget for each subgroup. A subgroup could be a business unit, a project, or just an arbitrary group of users. In this example:
<BU1>,<BU1 weekly budget>
<BU2>,<BU2 weekly budget>
Where BU1, BU2 are subgroup identifiers or labels, followed by their respective weekly budgets (in dollars), separated by comma. This file can be modified anytime by administrators or budget owners if the workload or business priorities change.
The script, executed weekly (e.g. Sunday at midnight) on the HPC head node by the Linux cron daemon, reads the configuration file, queries Cost Explorer and appends a new row to a CSV file (e.g. control.csv) with contents like this:
date, BU1, BU1 cost, BU1 budget, BU1 core limit, BU2, BU2 cost, BU2 budget, BU2 core limit,...
In this file:
dateis the day/timestamp of what the row representsBU1,BU2,BUnare subgroup identifiers from the configuration file described in step 1costis the accumulated EC2 cost of this subgroup during the past week, retrieved from the AWS Cost Explorer by this scriptbudgetis the weekly budget of the subgroup specified in the configuration file described in the step 1cores limitis calculated by this script according to cost and budget. The calculation is described in the next step.
An example of core limit calculation uses the formula like this:
if Cost > Budget:
core limit = default core limit / (Cost / Budget)
if Cost <= Budget:
core limit = default core limitHere, default core limit is calculated from the single-core weekly cost of a sample EC2 instance type for memory intensive workloads, e.g. 23.6880 USD, which is the weekly cost for a single core of an r5.large in the AWS region eu-west-1. So:
default core limit = budget / 1 core weekly costFinally, for each subgroup defined in the configuration file, our dynamic resource scheduler keeps track of the available number of EC2 cores as:
current BU core limit - currently allocated coresNote that this solution requires jobs to specify the number of required cores. Using the information from the scheduler and Cost Explorer, the solution limits the total number of cores used by a subgroup to the defined allocation in the configuration file. Any job that would exceed the limit will be pending until cores are freed up by finished jobs of the same subgroup.
An example
We’ll use a simple configuration for this example based on two business units BU1 and BU2, with different weekly budgets.
BU1 1000
BU2 2000
Our script will calculate default core limits of 42 and 84 respectively, according to an EC2 r5.large weekly core cost of 23.688 USD (Ireland-Dublin region).
The following table lists budgets, actual spending (costs) and calculated core limits of the following weeks for two subgroups: BU1 and BU2:
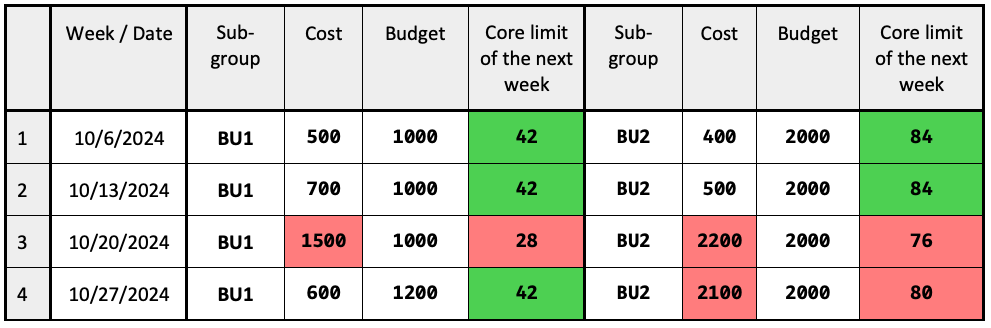
Table 1: sample budgets, with actual spend and calculated core limits over a period of 4 weeks.
In this example (under-limit values are marked in green, over-limit ones are in red):
- In week 3, BU1 exceeds its budget by 1.5 (50%). Its core limit for the next week is calculated and set as: 42 / 1.5 = 28.
- In week 3, BU2 exceeds its budget by 1.1 (10%). Its core limit for the next week is calculated and set as: 84 / 1.1 = 76.
- In week 4, BU1 exceeds its budget by 1.05 (5%). Its core limit for the next week is calculated and set as: 84 / 1.05 = 80.
- All other limits are defaults because of the spending under the corresponding budget.
Figure 1 illustrates the solution high level logic. The script budget.control.updater.sh is invoked regularly as a cron task, queries budget control configuration together with Cost Explorer, adds a new line into budget control table CSV, and updates scheduler configuration. The scheduler enforces each job to run only if its related subgroup budget is not over spent.
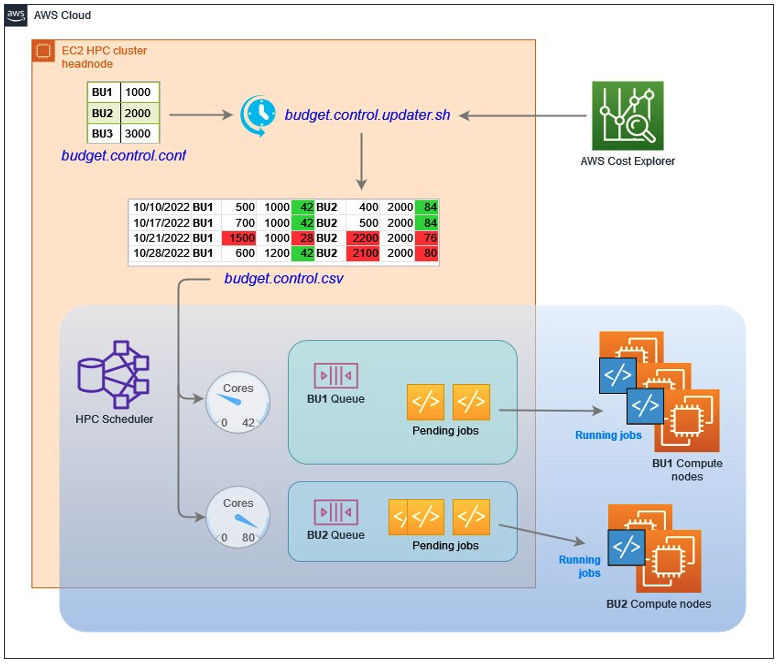
Figure 1: Dynamic budget control high level architecture.
Getting started and making this your own
We’ve put our code, including sample scripts and some examples in a specific AWS Samples repository on GitHub. You can try out this solution in your own AWS account by following the walk-through and code that we provided there.
You can also further customize and improve the solution in a couple of different ways, for example:
- Manage more instance types. You can augment your scripts to filter the Cost Explorer query output according to the job’s instance-type requirement. Administrators could add multiple 1 core/hour instance-type costs in the budget configuration file.
- Send email notifications when a daily cost exceeds the budget. You can do that by integrating the sendmail process on the head node with the AWS Simple Email Service as described in our documentation.
- Enforce job submission cores resource requirement – for example by using SLURM’s
PrologSlurmctld(see SLURM prolog and epilog guide). Prologs and epilogs can be extremely useful if you need to implement input-validation checks, perform data movements, or do pre-execution environment setup. - Retrieve 1-core cost automatically by querying AWS Price List Query APIs. This will ensure calculations always use up-to-date AWS pricing.
- Modify the core logic or timings for a specific HPC environment, for example, more frequent budget and limit controls, or smoothing limit changes.
- Subgroup tags, together with others could be enforced and validated as suggested in the Enforce and validate AWS resource tags
Conclusion
In this post, we described a straight-forward, but fine-grained and dynamic solution to keep work groups or business unit budgets under control. This has several advantages.
It allows administrators to manually update budgets and core limits according to the business needs. Admins can modify budgets limits in simple config files. The changes get picked up by automated cron tasks.
Historical budgets and calculated core-limits are recorded in a CSV file, which makes further analysis possible using Amazon QuickSight or a spreadsheet. This is useful for annual budget reviews, justifying more investments, spotting trends, and making forecasts.
HPC jobs breaching the limits are kept in pending status until more cores are freed up or job condition changes. In addition, the scheduler provides the information about job pending reasons when core limits are reached, helping users better understand and manage their own budgets.