AWS for Industries
A Reference Architecture for a Front Office Risk Store
Robert Butcher, Solution Architect, Global Financial Services, AWS
Front Office risk data is the lifeblood of Investment Banks. It informs every trading decision that they take, both commercial and prudential, and it’s critical for planning and regulatory reporting purposes.
In this post, we present a reference architecture for a Front Office Risk Store (risk store) using AWS services. The intended audience is solution architects and developers working in the Capital Markets sector, especially within the risk domain. However, it may also interest anyone building a data warehouse in the AWS Cloud with exacting non-functional requirements.
First, we’ll describe the purpose of a risk store. We’ll then discuss the specific challenges presented when architecting a risk store. Finally, we’ll introduce the reference architecture step-by-step, and explain how it utilizes the specific features of particular AWS services to overcome these issues.
This post doesn’t consider how to calculate the risk data using risk engines. For a description of an AWS-supported framework for building risk engines, see this related post.
What is a Front Office Risk Store?
Front Office risk data (risk data) refers to the calculated results for a set of industry-standard risk measures associated with the trading of financial instruments. These different risk measures are often named after Greek letters, and they quantify different risk exposure types. For example, the delta risk of a trade expresses how its value will be expected to change in response to a small change in the value of the underlying. Daily profit and loss (PnL) calculations are also generally included in this domain.
Risk data is calculated via specialized applications referred to as risk engines. Every trading day, a risk engine may process many hundreds of risk jobs. Any individual risk job will involve calculating a specific set of risk measures for a portfolio of trades (often all of the live trades associated with a particular trading desk).
The process of calculating risk is both highly compute-intensive and time-sensitive. To make sure of the timely delivery of risk results, the risk engine will split the overall work associated with a risk job into numerous independent calculation tasks. Each calculation task will consist of a subset of the overall trade portfolio. These calculation tasks are generally executed on a large Enterprise Compute Grid. Splitting the work in this way allows the calculation tasks to be processed concurrently, thus minimizing the wait required to complete the risk job. In other words, the faster risk calculations can be made, the more responsive risk and reporting decisions can become to meet commercial needs.
As each calculation task completes, the resulting risk data is passed to a risk store for storage. The risk store is both responsible for the long-term storage of the data, and for meeting various use cases for querying the data. Traditional on-premises risk store implementations are frequently based on low-latency, in-memory data grids, such as Oracle Coherence or Active Pivot.
Risk data is calculated both intra-day and as part of an overnight batch process. Intra-day risk data is used to support trading decisions (e.g., delta hedging). The overnight batch process is used to calculate the official closing position for the bank, which is commonly referred to as End of Day (EOD). EOD risk is consumed by downstream applications in related functions, such as Market Risk, and used to produce daily reports to the regulators.
Specific challenges when architecting Front Office Risk Stores
The importance of risk data leads to some particularly complex requirements when building risk stores. In this section, we present the main challenges.
Atomic commits
As mentioned above, a risk engine will generally split the work associated with a risk job into multiple risk calculation tasks. These are calculated concurrently, and as each one completes, they will independently send their corresponding results to the risk store.
In turn, the risk results corresponding to different calculation tasks may arrive at the risk store over a period of anything from a few seconds to several hours, depending on the risk job size and complexity, as well as any capacity constraints placed on the Enterprise Compute Grid.
This challenges the risk store architecture, as the risk results associated with a particular risk job must be committed atomically (i.e., all at once, or not at all). This is necessary because, if a user such as a trader were to run a highly-aggregated query against a partially-complete set of risk results, then it would present a false view of the true risk exposure.
Fine-grained access control
The overnight batch process will generate risk results for the whole of the bank. Various regulatory requirements determine who may view which data. In addition, it’s common practice when defining risk management systems that the Principle of Least Entitlement applies: users should only be able to access the data required to perform their job and no more.
For example, traders are generally permitted to view the risk data corresponding to their trading desk. However, they aren’t permitted to view the risk data for other desks. Certain super users, such as the Head of Trading, may be permitted to view all of the risk data, as can control functions such as Middle Office.
Other access control requirements may be more complex. For example, if a bank has a prime brokerage function, then there’s often a requirement that junior risk managers can’t identify individual counterparties (generally hedge funds) for the sake of client confidentiality. In practice, this means that for prime brokerage risk, certain fields (those referring to counterparty, sector, or region) must be hidden from some users.
Therefore, any risk store must support fine-grained access control to the data, both row-based and column-based.
Banks typically require this access control to be based on their existing access control systems. For example, SAML-federated access is based on the membership of existing on-premises Active Directory (AD) groups. Therefore, the risk store should support the authentication and authorization of users using SAML 2.0-compliant identity providers.
Schema evolution
Financial risk data may best be described as semi-structured. A typical risk schema may consist of several hundred fields. Some of these fields are mandatory and will be populated for all risk results. However, most fields are optional and will be null. This is because both trades and risk measures are highly-variable in nature. Therefore, certain fields only make sense within the context of a specific trade type and risk measures.
The schema will gradually evolve over time, with new fields being added in response to new business requirements.
Our risk store should be capable of dealing with the addition of new fields over time, and be optimized for queries that only consider a small subset of the available columns. These two requirements lead us to favor data stores based on columnar storage (as opposed to row-based storage).
Varied query use cases
Risk data is consumed in multiple ways. The following sections describe the most important use cases.
Ad-hoc queries
Individual users, such as traders, must run ad-hoc queries against the risk data. The queries are generally highly-aggregated, with users typically grouping data at the level of trading book, counterparty, or instrument type (among other fields).
When we encounter repeated queries involving aggregation, this indicates that we may use materialized views to minimize both compute usage and query latency.
Downstream applications
Certain downstream applications must consume risk data as an input into their own processing. This is typically conducted as part of the overnight batch processing.
These downstream applications will generally consume the data at its most-granular level (i.e., non-aggregated). They may use Big Data processing applications, such as Apache Spark, to consume the data in parallel and at volume. Therefore, the risk store must support native access by such tools.
The downstream applications typically operate within a limited overnight operations window. In turn, it’s important that the start of their processing isn’t delayed. Moreover, the risk store should provide a facility to notify these systems when any data that they require is available.
Federated queries
Users must frequently combine data held in the risk store with related data in other data stores. For example, it’s frequently required to join risk data with the trade and market data from which it is derived. Combining this data from multiple related (but possibly heterogeneous) data stores is referred to as a federated query.
Back-testing
When developing new risk models, quantitative analysts will generally conduct testing against historic data. This practice is referred to as back-testing.
The risk store should allow users to access historic data efficiently, even if this is only done infrequently.
Performance
The required performance when querying risk data is highly-dependent on the specific use case. For example, traders may require their standard reports to return within a couple of seconds. Other users, running non-standard reports, may be content waiting for several minutes. As a result, different Service Level Objectives (SLOs) may exist for different user groups.
In terms of committing incoming risk results to the risk store, this generally must be completed within a few seconds of the last piece of risk data for a particular risk job being received. It may take only a few minutes to complete the calculations for an intra-day risk job. The results may be needed to support an urgent trading decision. Furthermore, the user will expect their results to be available for querying almost immediately after the calculation is complete. Therefore, the risk store should allow for the risk results associated with a particular risk job to be uploaded, and available for querying, within a few seconds.
Volume
The volume of Front Office risk data generated by a typical investment bank ranges from 10-100 GB per day (in compressed, columnar format). This data must be retained for a seven-year period for regulatory reasons.
However, a strong recency-bias exists when querying this data. The vast majority of queries (at least 95%) are against data from the last 10 trading days.
This suggests that the risk store should utilize tiered storage to balance performance and cost-effectiveness. We should arrange that hot (frequently-accessed) data is served from a highly-performant storage medium (such as local SSDs), while cold (less-frequently accessed) data is served from a less performant, but cheaper data source (such as remote file storage).
Complex presentation
Ad-hoc queries, as submitted by users such as traders, tend to be more complex than simple aggregations. Users typically need the data to be displayed in the form of a pivot query on a desktop client application.
Furthermore, users will often create more complex reports that are composed of multiple pivot queries. For example, a common report format is to run a pivot query for two consecutive business days and display the difference between the two sets of results. The requirements of these reports can be complex and highly user-specific.
Customers typically create a custom domain-specific language (DSL) to represent client requests and responses for reports. Therefore, the risk store must able to present an API in terms of the DSL.
Reference architecture
In the remainder of this post, we’ll describe a reference architecture for a risk store. We’ll walk through the architecture one step at a time, explaining how AWS services may be used to meet the various requirements that we’ve described above. Moreover, we’ll describe how the AWS Cloud can help solve some business needs that traditional on-premises architectures fail to meet.
The complete architecture is displayed in the following figure.
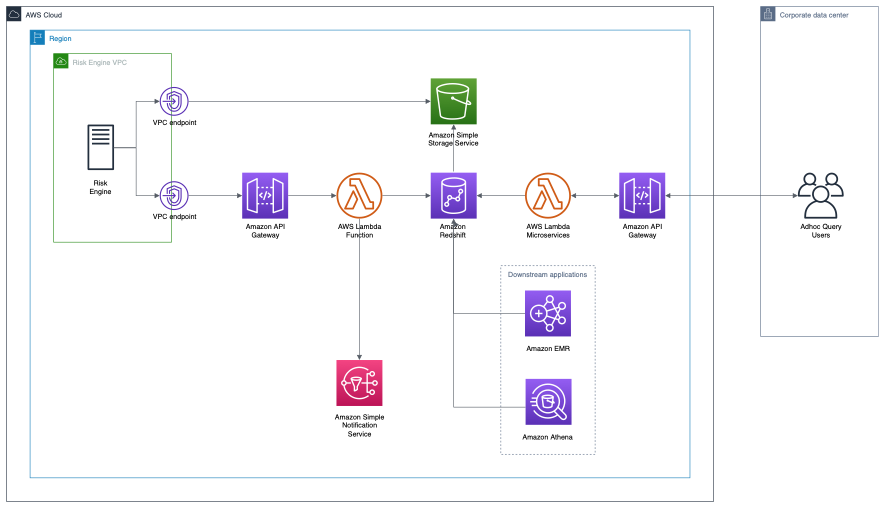
Figure 1: Reference Architecture
Amazon Simple Storage Service (Amazon S3)
Incoming risk data is written directly to an Amazon Simple Storage Service (Amazon S3) bucket by the upstream risk engines. Amazon S3 is well-suited to this task, as it’s both highly-scalable and capable of being written to by potentially thousands of risk engine processes concurrently. Furthermore, it’s highly-durable, highly-available, and secure.
If the risk engine is also hosted on the AWS Cloud, then we recommend writing the risk data to the Amazon S3 bucket via a VPC Endpoint. This will make sure that the data is transferred via the AWS internal network. This is both more performant, and potentially more secure, than routing the data via the public Internet.
Amazon Redshift
Amazon Redshift is used as the data warehouse for storing and serving risk data. Amazon Redshift is a highly-performant data warehouse capable of scaling to handle petabytes of data.
For this application, we recommend using a provisioned cluster based on RA3 nodes. This will let you utilize the tiered storage that RA3 nodes provide, which is a perfect fit for our requirements. Each node of this cluster has local SSDs that are used to efficiently cache data that is hot (frequently queried). Less frequently-accessed data is stored and served from Amazon S3. Given that only a small proportion of the overall data is frequently queried (generally risk for the past few days), this provides both a highly-performant and cost-effective tiered storage solution.
We mentioned that certain users (e.g., traders) have a requirement for very low query latency. However, these same users almost always run queries that are highly-aggregated (by trading book, counterparty, or instrument type). In this case we can greatly accelerate query times by creating materialised views containing pre-aggregated data. Amazon Redshift has excellent support for materialized views. In particular, it supports automatic refresh of materialized views (when the source data changes) and automatic query re-writing.
By utilizing appropriate materialized views, typical aggregated queries can be expected to be processed in double digit milliseconds.
Amazon Redshift supports fine-grained access control, down to the level of individual columns and rows. Furthermore, Amazon Redshift supports SAML-federated access, so it’s possible to control access to data – for example, by using the membership of existing on-premises Active Directory (AD) groups.
AWS Lambda
AWS Lambda is a serverless compute service that lets customers produce highly-scalable applications without having to manage the infrastructure themselves. In the following, we leverage it for two purposes: committing risk data to the data warehouse and the presentation layer.
Committing risk data to the data warehouse
Once the upstream risk engine has written all of the risk results associated with a particular job to the Amazon S3 bucket, it invokes a Lambda function via an HTTP request. This Lambda function uploads the risk results associated with the job from the Amazon S3 bucket to Amazon Redshift. Listing 1 in the following presents a (simplified) code sample to describe what it does.
-
- create temp table staging (like risk);copy staging
from ‘s3://mybucket/risk_job_123.manifest’
iam_role ‘arn:aws:iam::0123456789012:role/MyRedshiftRole’
manifest;begin transaction;delete from risk
using staging
where risk.trade_id = staging.trade_id
and risk.measure = staging.measure
and risk.namespace = staging.namespace
and risk.business_date = staging.business_date;insert into risk
select * from staging;end transaction;
- create temp table staging (like risk);copy staging
- Listing 1
First, the Lambda function uploads the risk data from Amazon S3 into Amazon Redshift. The fastest way to add data to Amazon Redshift is by using the LOAD command. A single call can efficiently read multiple files in parallel. The request body of the Lambda function will include a list of URLs for all of the risk files associated with the job (to identify which files must be loaded). The target for the command is a temporary staging table. At this stage, we verify that the files have indeed all been successfully loaded.
Next, we must remove any pre-existing risk data for the same trades and risk measures. Otherwise, we may end up with duplicate data. In most cases, this will be a no-op.
Having taken this precaution, we can now copy our uploaded risk data from our staging table into the main risk table.
All of the above steps may be included in a single AWS Redshift transaction. This lets us make sure that all of the data associated with a risk job is committed atomically. Furthermore, it makes sure that, in the event of an error, the transaction will be rolled back.
Once the risk data has been successfully committed to Amazon Redshift, an appropriate event may be posted to an Amazon Simple Notification Service (Amazon SNS) queue. Downstream applications may subscribe to these events to be notified when particular risk data that they require is available for querying.
For the sort of data volumes associated with an individual risk job, we would expect this entire ingestion process to complete within single digit seconds.
Presentation layer
We mentioned that ad-hoc query reports are often complex and composed from individual pivot queries with high-level functions applied. Customers frequently create their own DSL to represent client requests and responses. This requires a dedicated presentation layer to interpret requests, query the data warehouse, and compose a response.
It’s tempting to attempt to convert the entire request into a single (possibly very complex and deeply-nested) SQL query. However, this quickly leads to an unmaintainable codebase. We recommend splitting the presentation layer into multiple microservices that each perform one specific function. For example, one microservice might perform SQL queries against the data warehouse, a second might create a report based on comparing the results of two queries, and a third might format the results into a pivot query response. These microservices may be composed to handle arbitrarily complex requests.
Given the lightweight nature of these microservices, and the fact that request rates are likely to be highly-variable, we recommend utilizing AWS Lambda. This should provide a good combination of scalability, performance, and cost-effectiveness. Alternatively, customers who prefer containers may wish to deploy their microservices using Amazon Elastic Container Service (Amazon ECS) or Amazon Elastic Kubernetes Service (Amazon EKS).
Downstream applications
Downstream applications will typically bypass the presentation layer and simply query the data warehouse directly. As we mentioned above, they must typically access the data at its most granular level (i.e., non-aggregated) by using Big Data applications, such as Spark and Presto.
Amazon EMR is a service for running Big Data applications, such as Spark and Presto, and it can query Amazon Redshift both directly and performantly.
Federated queries
As we mentioned above, users may wish to include risk data in query results together with data from other related data sources. For example, a user may wish to include the Mark to Market (MtM) risk value of a trade within a query for trade data.
If the trade data is stored in Amazon Redshift, even in a separate cluster, then it’s possible to perform a native join between the two data sets. Alternatively, if the trade data is stored in a heterogeneous data source (e.g., an Amazon Aurora relational database or Amazon S3), then Amazon Athena may be used to perform a federated join between the two sets of data.
Other Considerations
Availability
The architecture described above is for a single region. However, all of the services described above are designed to be highly-available within that region. With the exception of the Amazon Redshift cluster, all of the services are fully-managed and will withstand the loss of an availability zone within the region where the application is deployed.
The Amazon Redshift cluster is specific to a particular availability zone. In the event of the loss of that availability zone, the cluster will be automatically restarted in another availability zone with no data loss.
Amazon Redshift may be configured to replicate snapshots to a second region. Moreover, this may be used as the basis of an effective disaster recovery plan (in the event of the loss of an entire region).
Conclusion
In this post, we have discussed the particular challenges posed when architecting a risk store. We have also demonstrated that, by leveraging particular features of certain AWS services, it’s possible to overcome these challenges with an elegant, scalable, and flexible architecture.