AWS for Industries
Automate prior authorization form filling using Amazon HealthLake
In this blog post, we discuss how to leverage Amazon HealthLake, Amazon Textract, Amazon Comprehend Medical, Amazon Athena, and Amazon QuickSight to further innovate and simplify healthcare prior authorization form completion. In our previous blog post, we discussed prior authorizations and how the often manual process can lead to delays or denials for care. These roadblocks cause frustration for providers and patients, while adding to the mountain of paperwork for healthcare systems.
Amazon Web Services provides a comprehensive list of machine learning and analytics services that enables developers to integrate machine learning and analytics technology into their applications. AWS AI and analytics services can not only help create a complete patient view, but also run queries and perform analytics to automate a prior authorization form to help speed the process of delivering care.
Not all prior authorization workflows are the same, and they can be complex. We attempt to present this in HIPAA-eligible, end-to-end architecture, including instructions that you can replicate and customize to accommodate your own workflows and process.
Prerequisites
We recommend you have the following to get the most out of this blog post:
- An AWS account
- High-level knowledge of FHIR (Fast Healthcare Interoperability Resources)
We also recommend familiarizing yourself with the following technologies and standards, which will be used throughout this post:
- Amazon HealthLake is a HIPAA-eligible service that offers healthcare and life sciences companies a complete view of individual or patient population health data for query and analytics at scale.
- Amazon Comprehend Medical is a HIPAA-eligible natural language processing (NLP) service that uses machine learning to extract health data from medical text. No machine learning experience is required.
- Amazon Textract is a machine learning service that automatically extracts text, handwriting, and data from scanned documents. It goes beyond simple optical character recognition (OCR) to identify, understand, and extract data from forms and tables.
- Amazon Simple Storage Service (Amazon S3) is an object storage service that offers industry-leading scalability, data availability, security, and performance.
- Amazon Athena is an interactive query service that makes it easy to analyze data in Amazon S3 using standard SQL. Athena is serverless, so there is no infrastructure to manage, and you pay only for the queries that you run.
Now, let’s look at our technical architecture.
Architecture overview
For this blog, we will discuss the use case to generate a prior authorization form for a magnetic resonance imaging (MRI) scan. We will fill the required information, such as patient demographics, provider information, exam request, and prior treatments, from our FHIR resources. You can find a sample prior authorization form here. For this blog, we loaded the Patient, Claim, Organization, DocumentReference, and Condition FHIR resources into Amazon HealthLake.
Once the FHIR resources are loaded into HealthLake, the imported FHIR resources are augmented with additional insight and metadata. Once we have the aggregated, transformed patient data on Amazon HealthLake, clinically relevant information is extracted from the aggregated data to create a longitudinal patient view. Finally, we query the required information to fill the prior authorization form for an MRI procedure. We also create a dashboard for a complete view of the patient. The goal is to make this workflow completely automated and event-based, requiring no human intervention.
The following architecture diagram showcases the AWS services used to build the serverless, event-based architecture for this workflow. The details of each component are explained in the eleven steps following the diagram, which correspond to the numbers in the diagram.
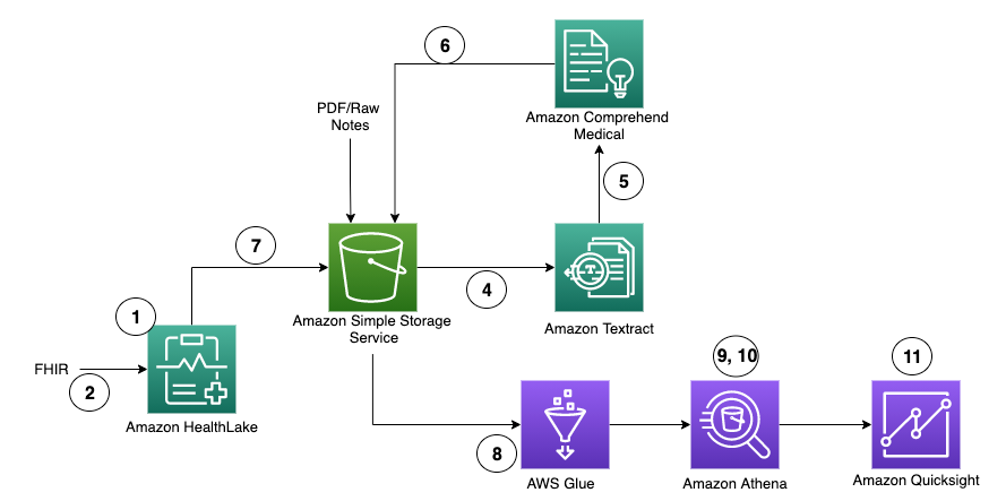
- Create an Amazon HealthLake Data Store mapped to your S3 bucket. You can create the HealthLake Data Store from the AWS Management Console or through the AWS Command Line Interface (AWS CLI). The following image shows the Create Data Store page in the console. The creating a Data Store section of the online documentation provides more details about creating a Data Store from the AWS CLI. The below image shows an example of creating a data store in Amazon HealthLake.

- FHIR resources are used as input for Amazon HealthLake. To load the resources into HealthLake, you have the following options:
- One option is to run a create query on the console. With this approach you can only load one record at a time.
- A second option is to run an import job. An import job can be run from the console, AWS CLI, or using APIs. The Importing files to an FHIR Data Store section of the online documentation provides more details.
- Amazon HealthLake transforms the FHIR resources and stores them in your Amazon S3 bucket mapped to the Data Store.
- If you have raw documents, such as clinical notes, these documents can be stored in an S3 bucket. An S3 event can be configured to trigger a Lambda function which will call an Amazon Textract job. Amazon Textract will extract the contents of the document.
(Sample code for steps 4, 5, and 6 can be found here.)
- The text extracted with Amazon Textract is fed into Amazon Comprehend Medical.
- Amazon Comprehend Medical will extract health data from the document and store the results in an Amazon S3 bucket.
- Data from HealthLake can be exported into an Amazon S3 bucket for further analysis. For the use case discussed in this blog, the data exported from Amazon HealthLake to Amazon S3 bucket will have five folders: Patient, Organization, Claim, Condition, and DocumentReference. Each folder will have a corresponding file postfixed with .ndjson format. The Exporting files from a FHIR Data Store documentation provides further details on how to export files using the console, AWS CLI, and APIs. Amazon HealthLake adds additional extensions to DocumentReference resource with additional tags.
- Next, we create an AWS Glue crawler that will create tables in the AWS Glue Data Catalog for each folder. We will have a table for Patient, Organization, Claim, Condition, and DocumentReference. Once these tables have been created in the Data Catalog, we can start querying these tables in Amazon Athena.
The ndjson files exported from HealthLake have nested json. The best practice is to run these files through AWS Glue ETL to flatten and transform them and store them in parquet format. To keep it simple, in this blog we directly query the json files using Athena. Please view the Amazon HealthLake workshop for additional details.
- The following relationships between our tables are used to join tables in Athena.
- Claims <–> Patient
- The patient.reference field in the Claims table can be used to join to the Patient table.
- Claims <–> Organization
- The provider.reference field in the Claims table can be used to join to the Organization table.
- Condition <–> Patient
- The subject.reference field in the Condition table can be used to join to the Patient table.
- Documentreference <– >Patient
- The subject.reference field in the Documentreference table can be used to join to the Patient table.
- Claims <–> Patient
- Using the joins, we create five views in Athena.
- claims_v: This view will contain all the claims information for a patient.
- condition_v: This view will contain all information related to the injury and condition for a patient.
- documentreference_v: This view will primarily contain information about the prior medication of the patient.
- patient_timeline_v: In this view, we will extract all the dates from the claims, condition, and documentreference table and union them all to generate a patient timeline.
- priorauthorization_v: This view will contain all the information needed to pre-fill the prior authorization form.
- Amazon QuickSight is used to create visualizations. Dashboards can be built using Amazon QuickSight by connecting to the views in Athena, providing a holistic view of the patient. For this, first create a new dataset in Amazon QuickSight using Athena data. This will import the views created in Athena into Amazon QuickSight as a dataset. Once it is imported, we can create an analysis in QuickSight. Once you have tested your analysis, you can create a dashboard and share it with other members of your organization.
Result
Using the described steps, a dashboard can be created in Amazon QuickSight. This dashboard has three tabs:
- Patient History
- Claims
- Patient Prior Authorization
Patient View
The below image shows the Patient History tab in the Amazon Quicksight dashboard.
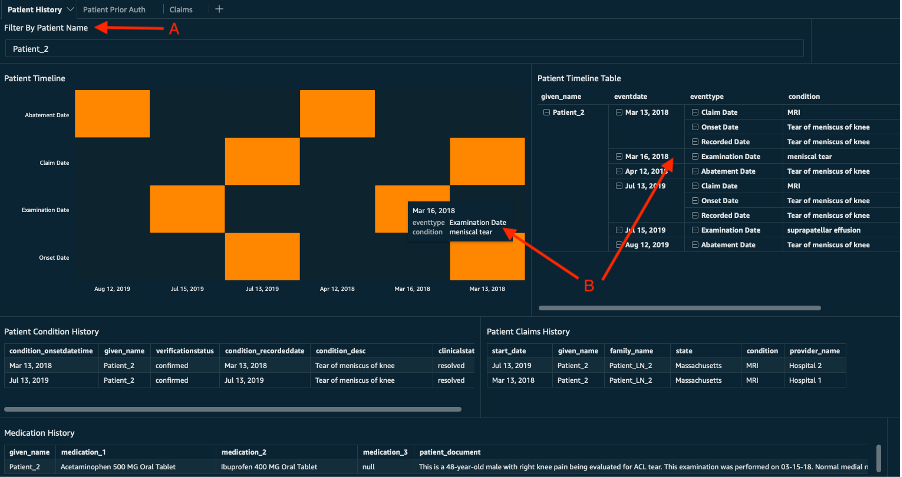
This chart can be filtered for an individual patient, as shown by the red arrow marked A in the image.
- The patient timeline report shows the different events that the patient has gone through. For example, as shown by the arrow marked B, the patient had an examination for a meniscal tear on March 16, 2018. The Patient Timeline table shows the same information in a tabular form. We highly recommend you review the Time Expression for Amazon Comprehend Medical feature for more detailed information.
- This analysis also includes the history of the different conditions the patient has been diagnosed with in the past.
- Patient claims history gives you information about different claims that have been submitted by or for the patient.
- Medication history gives the detailed report of patient medications, including non-prescription medications, extracted from doctors’ notes.
Prior authorization form field extraction
Coming back to our main use case on auto-filling the prior authorization form for an MRI, the following information (which is not an exhaustive list) will need to be extracted and made available to the healthcare professional.
- Patient/Member name
- Member ID number/group number
- Member date of birth
- Member health plan
- Ordering providers’ names
- Ordering providers’ contact information (including phone numbers and fax numbers)
- Providers’ specialties
- NPI (National Provider Number)
- TIN (Tax ID number)
- Prior authorizer Name and Contact details
- ICD10
- Medication and dosage
We are implementing a subset of the previously mentioned information from our FHIR resources for the filling of prior authorization. The necessary information required for filling can be extracted from the priorauthorization_v view. This data is extracted into a flat file.
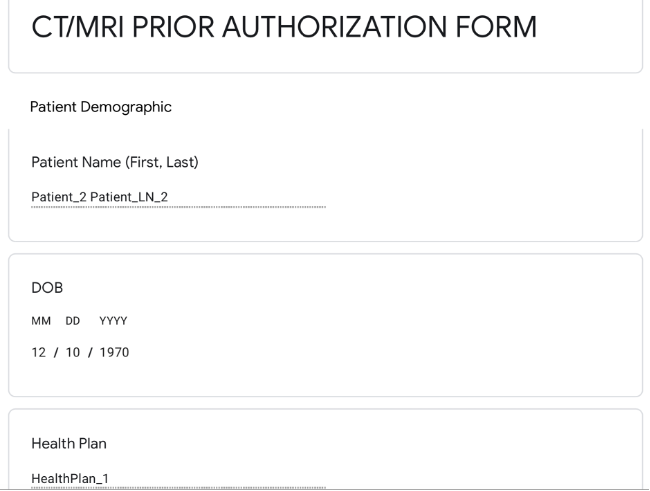
For this use case we will create a separate analysis in QuickSight and include it as a new tab in the QuickSight Dashboard. The below image shows the Patient Prior Authorization tab in the Amazon Quicksight dashboard.

We have already created priorauthorization_v view in a previous step. The view can be invoked from within a lambda function to automatically populate a prior authorization form for a patient. You can run this on-demand or scheduled.
For our use case, we ran on-demand queries on the priorauthorization_v view to extract information such as Patient Name, DOB, health plan, and treatment information (such as medication and dosage information from unstructured doctor notes in the DocumentReference FHIR resource). You can use Lambda code to generate the pre-filled sample of an auto-generated MRI prior authorization form. The below image shows an auto-generated prior authorization form generated using the method described above.

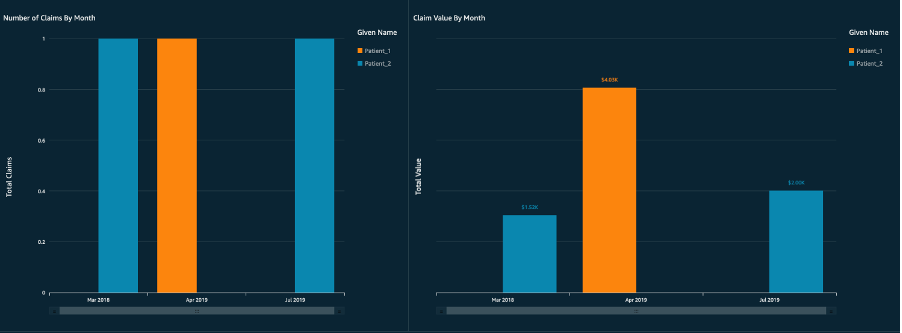
Claims History
The second analysis that we have created is a glimpse of population health with a specific focus on claims history. Refer to the Population health applications with Amazon HealthLake blog post for a detailed population health use case. To replicate this use case, we added additional sample patients’ FHIR resources to Amazon HealthLake following steps outlined in the “Create aggregated FHIR resource and clinical repository” section.
The below image shows an analysis of the states where the claims are being submitted, the gender of the patient population, the number of claims submitted per month, and the total value of those claims. This information can be examined further by filtering for an individual patient or by adding additional filters to the reports.

Conclusion
Machine learning allows organizations to increase operational efficiency by automating redundant manual tasks. In this post, we demonstrated an end-to-end serverless workflow for filling prior authorization forms for MRI treatments. We also showed dashboards for patient view and claims history for easy visualization. We demonstrated how, in a world where speed and agility are paramount, machine learning can give organizations a competitive advantage.
Although we demonstrated an automated process that can speed the delivery of care, please note:
- You will not be able to automate everything. Tasks requiring analytical thinking may still require human intervention. Always have provisions for human intervention in your workflow when needed.
- In this blog post, we ran analytics on our FHIR synthetic resources. We did not cover a unique way for ID matching across cross-functional entities.
To learn more about AWS for Health —an offering of curated AWS services and AWS Partner Network solutions used by thousands of healthcare and life sciences customers globally, visit AWS for Health and AWS Healthcare Solutions webpages.