AWS for Industries
Simplify Prior Authorization in Healthcare with AWS and HL7 FHIR
Prior authorization is a process to obtain approval from a health insurer or plan that may be required before you get a health care service, treatment plan, prescription drug, or durable medical equipment in order for the service or prescription to be covered by your plan. Your health insurance company uses a prior authorization requirement as a way of keeping health care cost-effective, safe, necessary, and appropriate for each patient. However, the process of requesting and receiving prior authorizations can be slow and inefficient. They can often lead to treatment delays and be an obstacle between patients and the care they need. Prior authorizations are often solicited by fax or payor-specific portals, and usually need manual intervention to enter the relevant information. This requires manual transcription on the payor side, potentially resulting in significant time and cost prior to a decision being made.
Healthcare data interoperability can offer frictionless data exchange among various stakeholders in the healthcare community such as payors, providers, and vendors, and can be a mechanism to address challenges related to prior authorization. Direct submission of prior authorization requests from an electronic health record (EHR) will not only reduce costs for both providers and payors but will also result in faster prior authorization decisions. The Da Vinci Project created an implementation guide to address this challenge. Da Vinci is working to accelerate the adoption of HL7 Fast Healthcare Interoperability Resources (HL7® FHIR®) as the standard to support and integrate value-based care (VBC) data exchange across communities. But this healthcare data interoperability creates an additional challenge to connect and coordinate the exchange of different information systems—devices or applications—within and across organizational boundaries. AWS provides a cloud-enabled platform with modern, scalable architectures and microservices to enable true healthcare data portability. Because of a broad offering of container orchestrators, you can run your containers on AWS regardless of your choice of tools or APIs.
In this blog, we demonstrate how to use Amazon Elastic Container Service (ECS) to deploy part of the Da Vinci implementation for healthcare data interoperability. In this interoperability solution, we will be using AWS Fargate, a serverless compute engine for containers.
In this two-part series, we share a sample architecture to deploy Da Vinci leveraging AWS as a scalable, secure platform. In part two of this two-part series, we will also share ideas on how to create innovation from healthcare data using AWS machine learning and analytics services.
Prerequisites
Be sure to have the following to get the most out of this blog post:
- An AWS account;
- Find the reference implementation to Da Vinci
- Prior experience with Amazon CloudWatch is recommended, but not required
Before diving into the solution, we also recommend familiarizing yourself with the technologies and standards used throughout this post.
- Amazon Elastic Container Service (ECS) as a container orchestration service, and Amazon Elastic Container Registry (ECR) a fully managed container repository
- AWS Fargate, a serverless compute engine for containers that works with ECS.
- Amazon DynamoDB and Amazon Simple Storage Service (S3) as a scalable data store
Solution overview
The Da Vinci community has developed reference implementations for FHIR interoperability, and in this blogpost, we discuss one such use case on prior authorization with Coverage Requirements Discovery (CRD). Prior authorization enables direct submission of prior authorization requests to payors, resulting in lower costs and faster processing of prior authorization decisions. CRD defines a workflow to allow payors to provide information about coverage requirements to healthcare providers. The combined architecture of prior authorization with CRD offers further increased efficiency and better patient outcome.
 Figure 1 – High-level architecture of communication between CRD and prior authorization
Figure 1 – High-level architecture of communication between CRD and prior authorization
In this blogpost, we are focusing on deployment of the CRD server, which acts as a healthcare payor information system by leveraging the AWS container platform. The following diagram shows how AWS services Amazon ECR and Amazon ECS with AWS Fargate, Amazon S3, Amazon DynamoDB, and Amazon CloudWatch work together to deliver a resilient, secure architecture.
Architecture
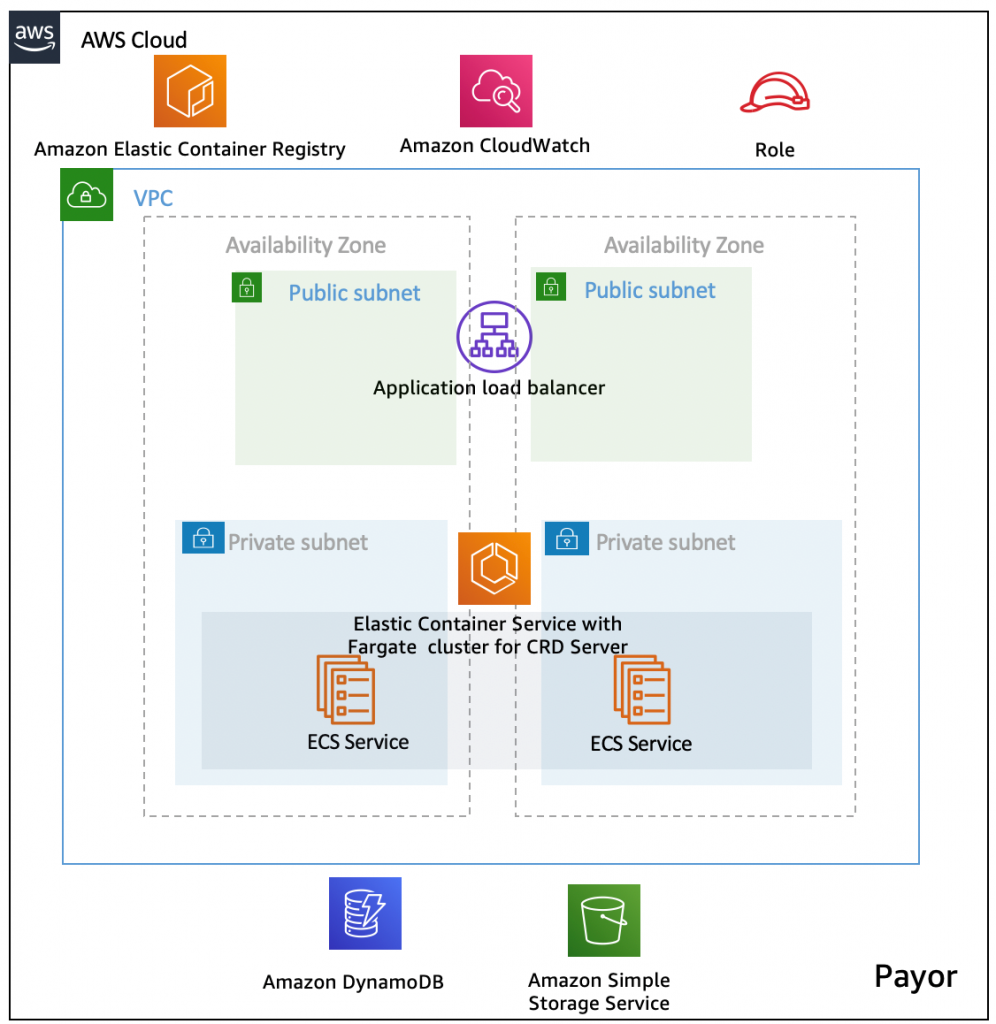 Figure 2 – Architecture diagram
Figure 2 – Architecture diagram
The architecture diagram showcases the various components of the solution:
- The container image for CRD is stored in Amazon ECR.
- Amazon ECS with AWS Fargate is used as a serverless compute for CRD container.
- Required IAM Roles with access permission are created to write to Amazon DynamoDB table and Amazon S3 from the server.
- Container logs are streamed to Amazon CloudWatch for logging and monitoring.
- The CRD server is front ended with an Application Load Balancer for secure distribution of load, and offers a scalable, secure way to communicate with the prior-auth service.
- (Optionally) Amazon API Gateway can be leveraged to serve the API requests.
Instructions to build the solution
We are building Docker container images from the Da Vinci for CRD Reference Implementation, which includes the code changes required to write to Amazon S3 and an Amazon DynamoDB table.
To integrate with the AWS environment, we have modified the build.gradle to add the required dependencies for AWS SDK. AWS offers support for AWS SDK for various different languages, and we are leveraging Java SDK for our requirement.
As per our requirement to write FHIR resources to the DynamoDB table, we modified the code with the below code sample. You can use a Software Development Kit (SDK) to integrate with other AWS services as per your requirements. For more information, see AWS SDK for Java Documentation.
- Add code changes to store data on Amazon DynamoDB
Sample code changes:
 Figure 3 – Task definition
Figure 3 – Task definition Figure 4 – Container definition
Figure 4 – Container definition Figure 5 – CloudWatch log
Figure 5 – CloudWatch log Figure 6 – CRD page
Figure 6 – CRD page