AWS for Industries
Calculating growing degree days using AWS Registry of Open Data
The selection of specific crops (corn, soybeans, wheat etc.) is dictated by the heat units and length of the growing season. This is commonly calculated as Growing Degree Units. The AWS Registry of Open Data contains global weather datasets dating back over 200 years enabling agricultural crop breeders in the seed/chemical/fertilizer business to optimize their breeding stock. Additionally this could assist farmers as climate change varies to landscape of crops that are suitable for their geography. This blog addresses how to leverage public data that is hosted on AWS Open Data to simplify their architectural stack in acquiring the data need for calculating Growing Degree Days.
The selection of specific crops, varieties, and traits is often driven by the heat units and length of the growing season, calculated as Growing Degree Days. This calculation is frequently only a component of the solution, and obtaining the weather data required to perform the calculation is undifferentiated heavy lifting. Customers have described the problems they are trying to solve including:
- Hybrid development: Robust, long-term historical data at a granularity required to inform hybrid development enriches agricultural field trial data lakes to understand the conditions in the field that correspond with the geographical location of the plot. This information, particularly prior to the calculation of more hyper specific weather stations being applied on field plots enriches the ability to create similar features over a longer historical duration such as Growing Degree Units and Cumulative Growing Degree Units.
- Agronomic seed variety selection/agronomic recommendations: As weather patterns continue to change and seed varieties change, a knowledge of Growing Degree Units within a geography can help seed/chemical/fertilizer companies to recommend the right product to plant by enriching their own data lake with historical weather and Growing Degree Unit features.
- Contextual enrichment of a personalization engine: Historical datasets can inform the development of seeds and agronomic recommendations, but Cumulative Growing Degree Days, in combination with information that may be available in an existing data lake, such as planting date and variety, can help to provide context to a personalization engine helping producers and agronomists with timing of in season applications.
Growing Degree Units can be calculated in the field from IoT enabled weather stations, or from public weather stations. The benefit of public stations is often the history of the data collection period, as well as the consistency of reporting. The AWS Registry of Open Data hosts datasets, often for entities who have a mandated reporting requirement or a need to make data available publicly. Of note, unless specifically stated in the applicable dataset documentation, datasets available through the Registry of Open Data on AWS are not provided and maintained by AWS. Datasets are provided and maintained by a variety of third parties under a variety of licenses. Please check dataset licenses and related documentation to determine if a dataset may be used for your application.
For this tutorial, the dataset featured is NOAA Global Historical Climatology Network Daily (GHCN-D) due to its global coverage and normalization of multiple reporting sources and 200 year history. However, as of the time of this publication, there are 28 weather datasets available for evaluation in best suiting the use case and geographies of interest.
The workflow
- Accessing public S3 bucket
- Crawling dataset using AWS Glue
- Querying the dataset with Amazon Athena
- Visualizing the insights with Amazon QuickSight
This blog extends upon the data access methods and architectural patterns discussed in the blog titled ‘Visualize over 200 years of global climate data using Amazon Athena and Amazon QuickSight’. The directions for accessing the GHCN-D dataset using AWS Glue and Amazon Athena are covered in the tools and workflow of that blog and so we will only discuss them in summary here.
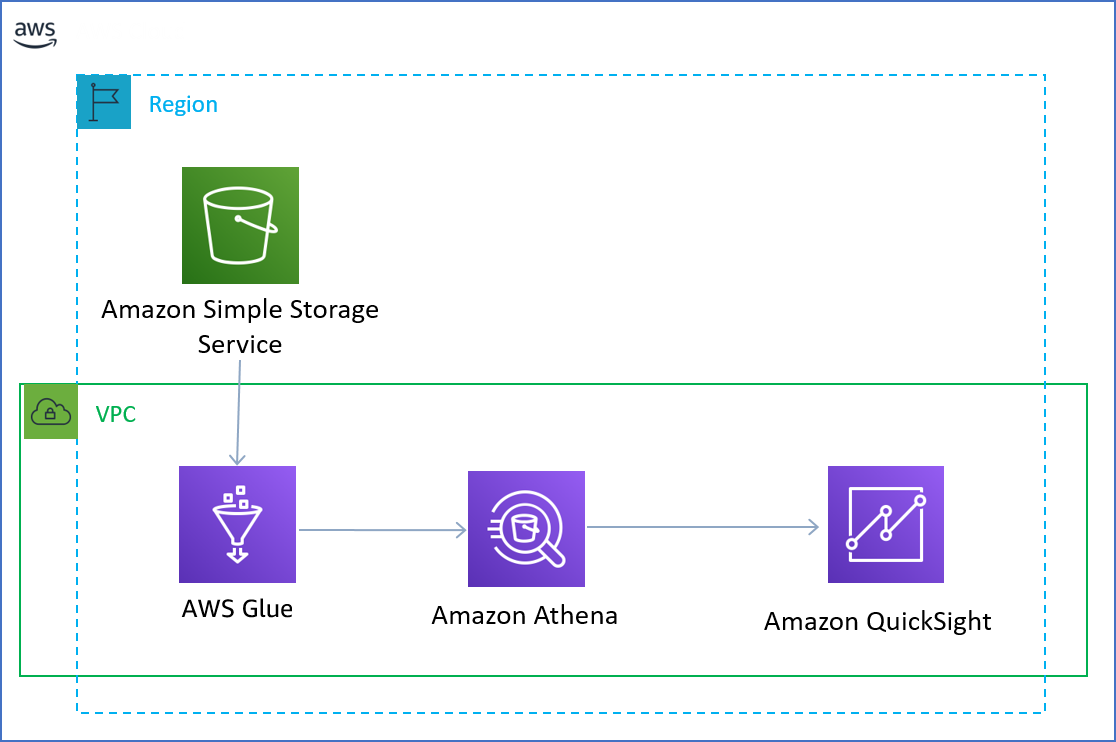
Figure 1: Services used in tutorial
Accessing public S3 bucket
The GHCN-D dataset is stored in a publicly accessible S3 bucket. Prior to selecting a dataset to use, consider the resource type and AWS Region as well as the documentation of the dataset. In the case of weather datasets, pay particular attention to the frequency to ensure it meets the needs of your application.
Crawling dataset using AWS Glue
Once you have identified the dataset you want to ingest from the AWS Registry of Open Data sign into the AWS Management Console. In AWS Glue, choose the Tables section on the left hand navigation. On the Add table menu choose Add table manually. Let’s progress through the forms, and to ensure consistency in the tutorial we will use the same steps as outlined in the blog mentioned previously.
- Set up the properties
- Give your table a name, for example, tblallyears
- Create a database and name it ghcndag
- Add a data store
- Choose the specified path in another account option and enter the following path in the text bos: s3://noaa-ghcn-pds/csv/
- Choose a data format
- Select CSV, then select Comma as the delimiter
- Define a schema
- Add the following columns as string variables as found in the read me file of the documentation
- Id
- Year_date
- Element
- Data_value
- M_flag
- Q_flag
- S_flag
- Obs_time
- Add the following columns as string variables as found in the read me file of the documentation
- Choose OK, then Finish
Querying the dataset with Amazon Athena
For the purpose of this tutorial, I am going to focus on a single weather station closest to where I could ground truth the information and feel confident it was accurate. Therefore the queries below will reference a weather station ‘CA005021220’. The station ID could be parameterized, or be contextually relevant depending on the application, considerations that a full build would require. The GHCND-D dataset includes hundreds of weather stations globally, to determine the inventory of weather stations and the reporting period, NOAA has helpfully provided an inventory file, which can be accessed here. Let’s get started on calculating and visually displaying important weather information in the context of agriculture.
- In accessing Amazon Athena from the AWS Management Console, select the ghcndag database in the drop down on the left hand navigation. Clicking on the blue arrow beside the tblallyears dataset expands the field list to display the schema you defined in Glue. Now it is time to start querying the data to structure meaningful insights.
- Creating a series of queries helps to gain confidence that the data is of high enough quality for use in an end user application, and should be a consideration. Below are the queries used to create datasets for later use in Amazon QuickSight.
- Precipitation
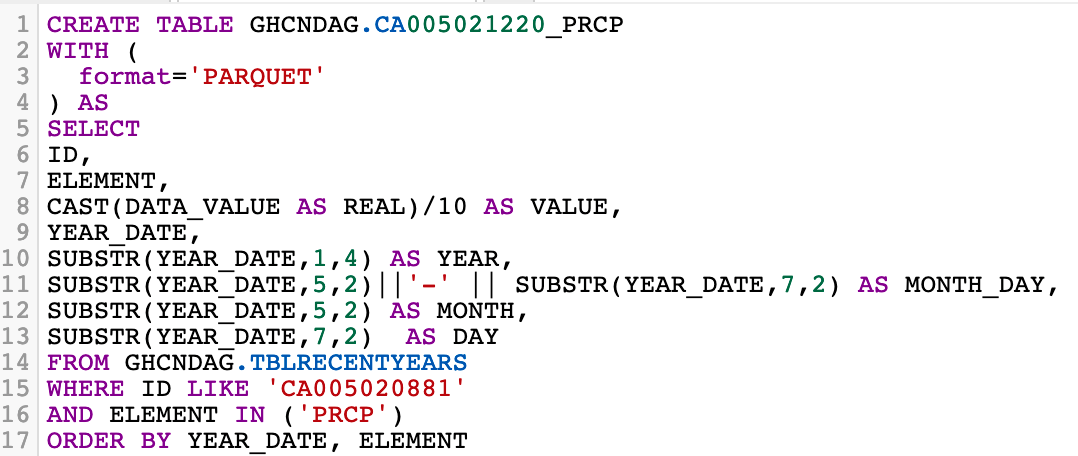
- Temperature (Minimum)
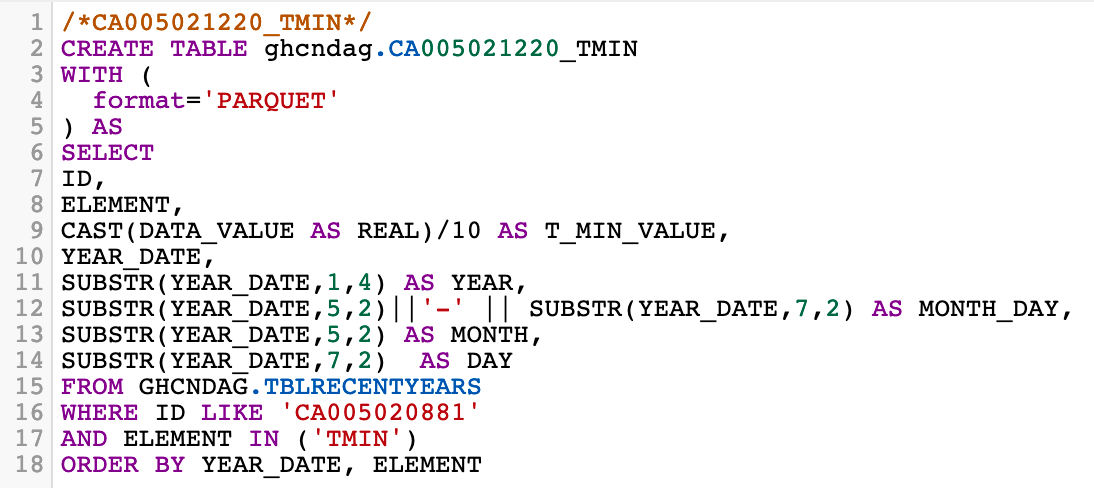
Of note, the GHCN-D dataset reports temperature in tenths of a degree Celsius. For ease of visualization, and sense making for users, it is converted to degrees Celsius in the above query.
- Growing Degree Days

Of note, Growing Degree Days are specific to the crop type. All temperatures referenced in this calculation are in Celsius, and the crop type is assumed to be wheat.
Visualizing the insights with Amazon QuickSight
After familiarizing with the datasets using Amazon Athena, and determining the queries that best reflected the end user desired visualizations for the weather station of interest the Athena datasets can be used by Amazon QuickSight.
- Access the Amazon QuickSight console
- In the upper right hand corner, select Manage Data
- In the upper left hand corner, select New Dataset and begin navigating the series of forms
- Select Amazon Athena as your source
- Give your data source a name and validate your connection
- From the drop down choose the ghcndag database and the tables you created will populate.
- Select the table of interest and move to the next screen
- In the prototyping phase of a dashboard, it may be easiest to query your data directly. In production utilize SPICE which will improve your dashboard performance
- Select Visualize
Amazon QuickSight allows you to quickly build dashboards and stories visually to bring context to Key Performance Indicators. Let’s take a look at 3 examples below (Figures 2-4)
The daily minimum and maximum temperatures can be plotted against each other, giving insight as to soil temperature warming and potential dates of frost risk.
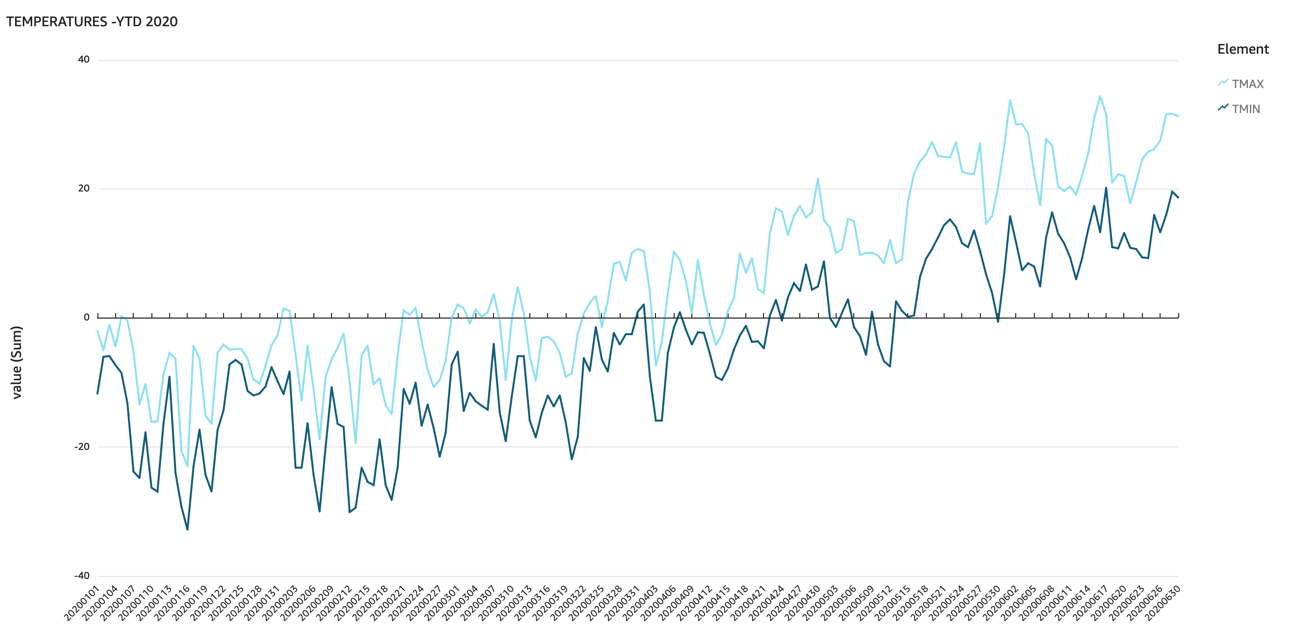
Figure 2: Temperature Minimum and Maximum YTD 2020
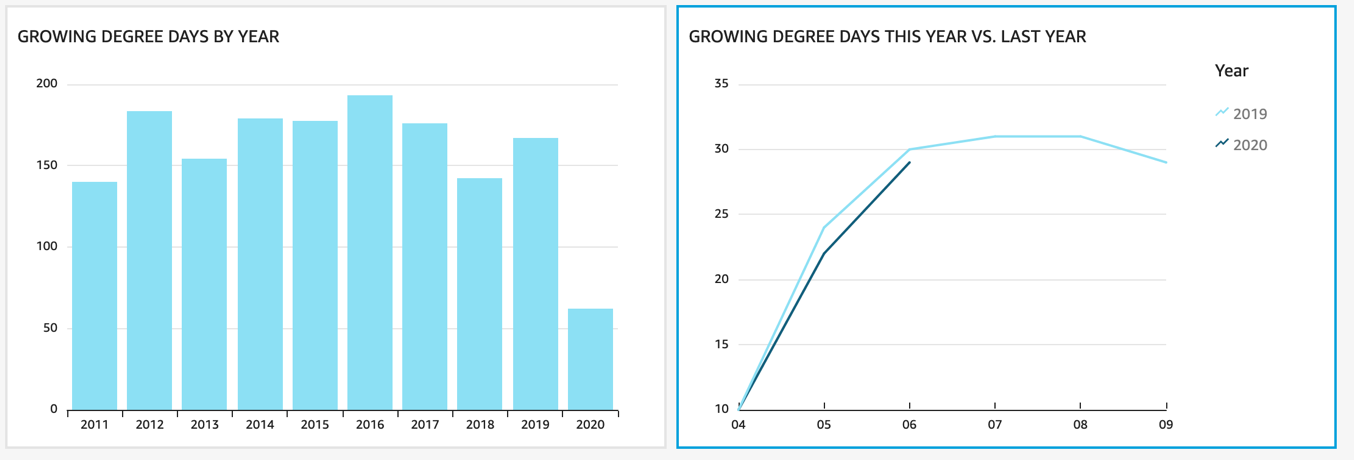
Figure 3: Growing Degree Days by Year and Comparison
Amazon QuickSight allows users to look at data quickly to understand YoY comparisons, and potential shifts that may impact variety selection. The first graph shows 10 years of historical cumulative Growing Degree Days by year, but GHCN-D stores data for over 200 years on some weather stations. This analysis could be extended based on the application. At the same time as looking at historical trends, understanding Growing Degree Days this year (2020) as compared to last year (2019) can give insights, particularly when combined with other agronomic data such as planting dates.
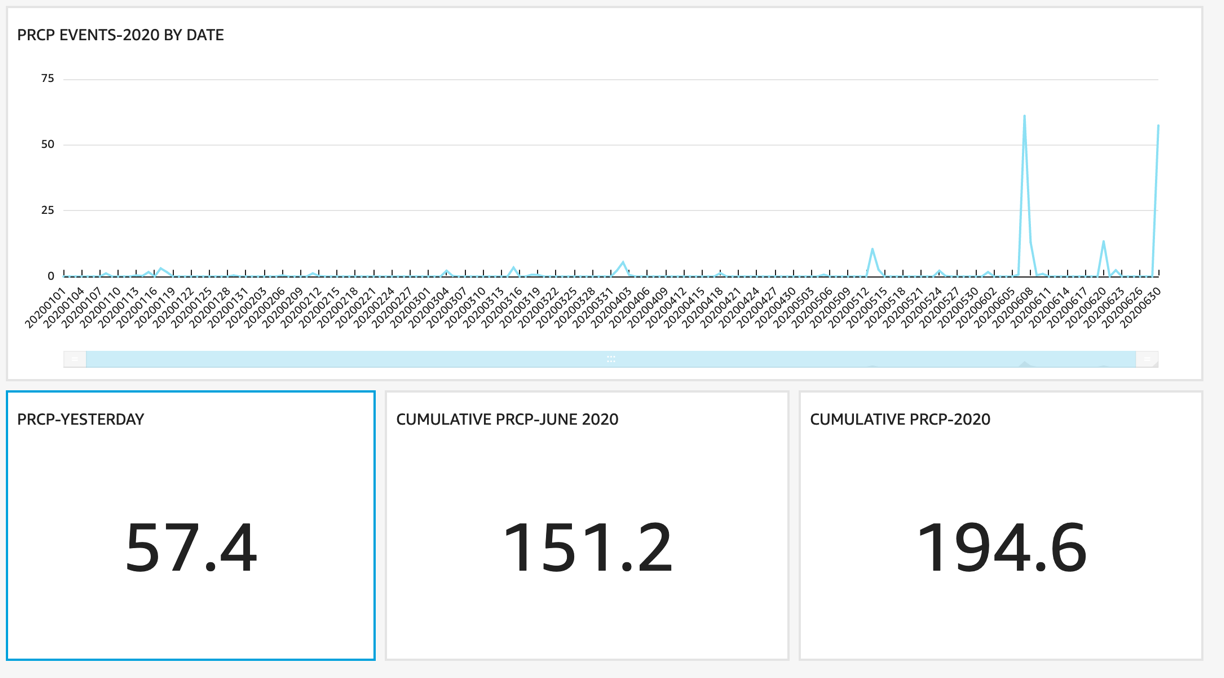
Figure 4: Precipitation Events by Date
The visualization in Figure 4 focuses on 4 key metrics, the precipitation by date, as well as by 3 different time spans, yesterday, current month and the year to date. These metrics give context to moisture availability, as well as the likely soil conditions. After a significant rainfall event like yesterday a recommendation to perform an in-field application or tillage may result in a piece of equipment being unable to successfully complete the operation, breakdown or result in operator time lost. Having this contextual information would not only assist in a Field Management Information System, but also in an Agronomic Recommendations Engine.
This tutorial has focused on the ease at which you can access data on the AWS Registry of Open Data to enrich and enable precision agriculture through publicly available datasets already hosted in the AWS Cloud. Your differentiated actions in applying these datasets through machine learning generates new ideas and research into the application of precision agriculture in the field.
To access the GHCN-D weather dataset on the AWS Registry of Open Data for hands-on practice of this tutorial it can be referenced here. A cloud formation template to enable this tutorial has been made available for learning purposes. Additional weather datasets that may be more specific and granular to your geography can be found at the full listing of the AWS Registry of Open Data. Accessing weather data is likely only a small component of your overall architecture, so in Figure 5 below you will see a reference architecture of the the services that help to build a comprehensive user engagement platform.
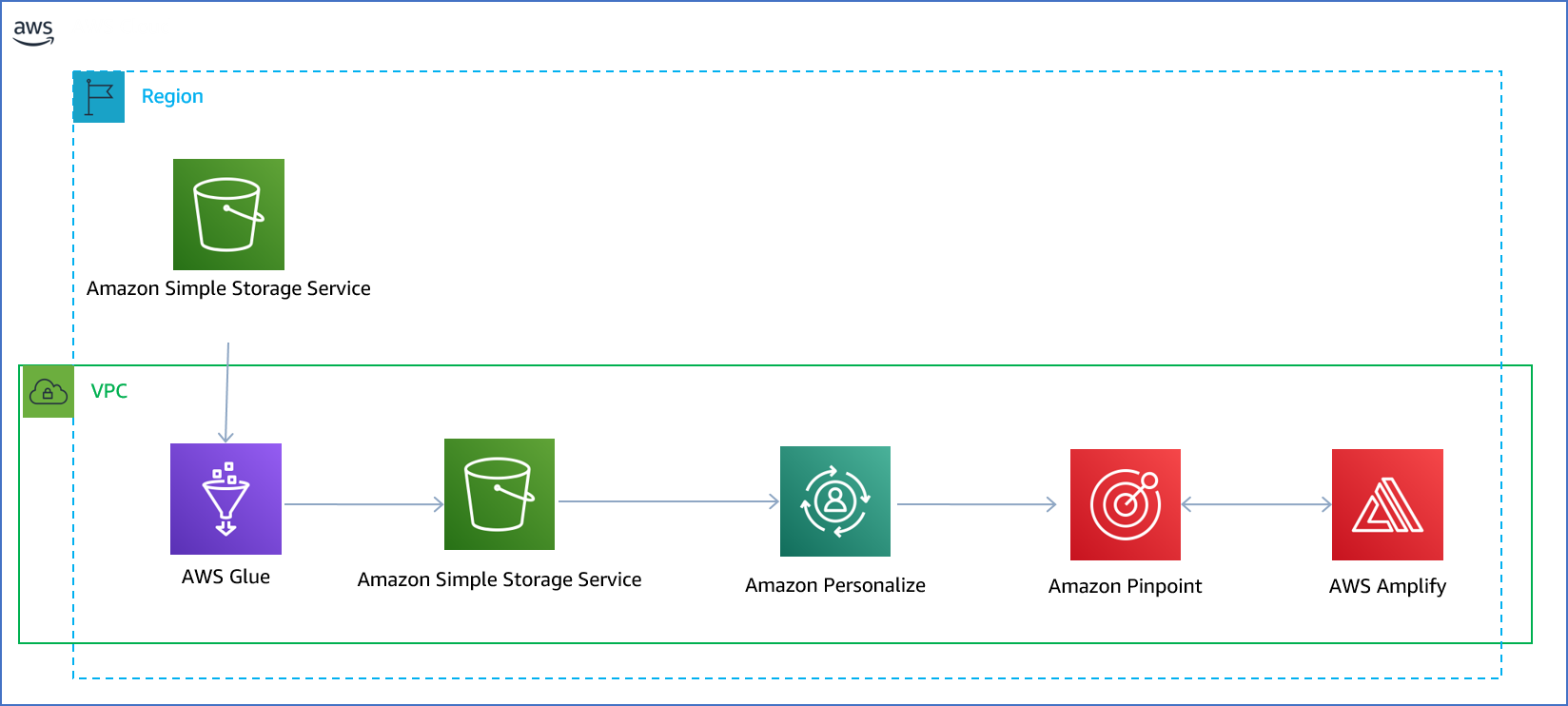
Figure 5: User engagement using AWS Registry of Open Data datasets
User engagement often starts with a personalization engine in this architecture Amazon Personalize, which is a fully managed service providing recommendations based on the same platform as leveraged on Amazon.com. Customers are often focused on multi-channel engagement of their users, and this can be enabled with Amazon Pinpoint, which can provide contextual relevance. For example, a farmer may have acres across several townships or municipalities, and Amazon Pinpoint can provide contextually relevant information based on the current geolocation, such as the weather station and GDD calculation based on the current user location during field scouting. A field scouting app could be deployed via AWS Amplify, which is a set of tools and services that enables mobile and front-end web developers to build secure, scalable full stack applications, powered by AWS. With Amplify, it’s easy to create custom onboarding flows, develop voice-enabled experiences, build AI-powered real-time feeds, launch targeted campaigns, and more.
To learn more about each of these three services, please check out the product information pages for Amazon Personalize, Amazon Pinpoint and AWS Amplify. If you are looking for further training on each, virtual classes are available by visiting the AWS Training & Certification portal or by going directly to introductory courses on Amazon Personalize, Amazon Pinpoint or the resources to get started with AWS Amplify.