AWS for Industries
Tag: genomics

Machine Learning Leukemia diagnosis at Munich Leukemia Lab with Amazon SageMaker
Munich Leukemia Lab (MLL) is a leading global institution for leukemia diagnostics and research, operating within a highly innovative environment. MLL aims to shape the future of hematological diagnostics and therapy through state-of-the-art molecular and computational methodologies. To this end, MLL partnered with the Amazon Machine Learning Solutions Lab (MLSL) and Mission Solutions Team (MST) […]
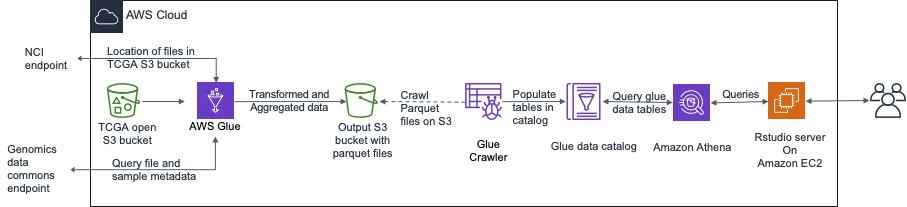
Enabling the aggregation and analysis of The Cancer Genome Atlas using AWS Glue and Amazon Athena
The Cancer Genome Atlas (TCGA) is a landmark cancer genomics program, producing molecular data for nearly 20,000 primary tumors and matched normal tissues from 11,328 patients across 33 cancer types. The TCGA includes germline and somatic variants, copy number variants, mRNA expression, miRNA expression, DNA methylation, and protein expression for most patients. In addition to […]

Standardizing quantification of expression data at Corteva Agriscience with Nextflow and AWS Batch
Authored by Anand Venkatraman, Bioinformatics Associate Research Scientist at Corteva Agriscience, and Srinivasarao Annapareddi, Cloud DevOps Engineer at Corteva Agriscience. The content and opinions in this post are those of the third-party author and AWS is not responsible for the content or accuracy of this post. — Data analysis in biological research today presents some […]

NIH’s Sequence Read Archive, the world’s largest genome sequence repository: Openly accessible on AWS
AWS and the National Library of Medicine’s (NLM) National Center for Biotechnology Information (NCBI) are happy to announce that the Sequence Read Archive (SRA) – one of the world’s largest repositories of raw next generation sequencing data, will be freely accessible from Amazon S3 via the Open Data Sponsorship Program (ODP). The SRA is currently […]

Executive Conversations: Building Resiliency with Bob Reiter, Head of R&D, Bayer Crop Science
Bob Reiter, Head of R&D of Bayer Crop Science, joins Elizabeth Fastiggi, Worldwide Lead of Agriculture Business at AWS for a discussion on recent disruptions in the global food supply chain, examples of farmers building resiliency through data and analytics, and future trends for sustainability. Crop Science, a division of Bayer, provides a range of […]

Whitepaper: Genomics Data Transfer, Analytics, and Machine Learning using AWS Services
AWS Genomics has released a new whitepaper, Genomics Data Transfer, Analytics, and Machine Learning using AWS Services, that provides essential information and guidance on how to build a Next Generation Sequencing (NGS) platform using AWS services, from instrument to interpretation. Accompanying the new whitepaper are three solutions, developed based on feedback from AWS life science […]

Make the most of AWS re:Invent 2020 – Life Sciences Attendee Guide
AWS re:Invent routinely fills several Las Vegas venues with standing-room only crowds, but we are bringing it to you with an all-virtual and free event this year. This year’s conference is gearing up to be our biggest yet and we have an exciting program planned with five keynotes, 18 leadership sessions, and over 500 breakout […]

DRAGEN reanalysis of the 1000 Genomes Dataset now available on the Registry of Open Data
Guest authored by Bryan Lajoie, Staff Bioinformatics Scientist at Illumina Inc. — We are pleased to announce the release of a comprehensive reanalysis of 3,202 deeply-sequenced samples from the 1000 Genomes Project(1kGP) using the Illumina DRAGEN (Dynamic Read Analysis for GENomics) Bio-IT platform. This seminal dataset will be freely available for researchers across the world to use […]

Cromwell on AWS: A simpler and improved AWS Batch backend
The latest release of Cromwell (v52) includes a number of major changes and improvements to the AWS Batch backend for Cromwell. Among the numerous changes, we have enabled Cromwell’s Call Caching feature when using AWS Batch with files in Amazon Simple Storage Service (Amazon S3). This allows genomics researchers to efficiently develop and run workflows […]

Broad Institute gnomAD data now accessible on the Registry of Open Data on AWS
Co-authored by Grace Tiao, Associate Director of Computational Genomics at the Broad Institute and Erin Chu, DVM, Ph.D., Life Sciences Lead, AWS Open Data Program Today we announce that data from the Genome Aggregation Consortium (gnomAD) is available for the first time on Amazon Web Services (AWS) as part of the Registry of Open Data […]