The ability to predict that a particular customer is at a high risk of churning, while there is still time to do something about it, represents a huge potential revenue source for every online business. Depending on the industry and business objective, the problem statement can be multi-layered. The following are some business objectives based on this strategy:
This post discusses how you can orchestrate an end-to-end churn prediction model across each step: data preparation, experimenting with a baseline model and hyperparameter optimization (HPO), training and tuning, and registering the best model. You can manage your Amazon SageMaker training and inference workflows using Amazon SageMaker Studio and the SageMaker Python SDK. SageMaker offers all the tools you need to create high-quality data science solutions.
SageMaker helps data scientists and developers prepare, build, train, and deploy high-quality machine learning (ML) models quickly by bringing together a broad set of capabilities purpose-built for ML.
Studio provides a single, web-based visual interface where you can perform all ML development steps, improving data science team productivity by up to 10 times.
By the end of this post, you should have enough information to successfully use this end-to-end template using Pipelines to train, tune, and deploy your own predictive analytics use case. The full instructions are available on the GitHub repo.
In this solution, your entry point is the Studio integrated development environment (IDE) for rapid experimentation. Studio offers an environment to manage the end-to-end Pipelines experience. With Studio, you can bypass the AWS Management Console for your entire workflow management. For more information on managing Pipelines from Studio, see View, Track, and Execute SageMaker Pipelines in SageMaker Studio.
The following diagram illustrates the high-level architecture of the data science workflow.
Pipelines is integrated directly with SageMaker, so you don’t need to interact with any other AWS services. You also don’t need to manage any resources because Pipelines is a fully managed service, which means that it creates and manages resources for you. For more information the various SageMaker components that are both standalone Python APIs along with integrated components of Studio, see the SageMaker service page.
For this use case, you use the following components for the fully automated model development process:
A SageMaker pipeline is a series of interconnected steps that is defined by a JSON pipeline definition. This pipeline definition encodes a pipeline using a directed acyclic graph (DAG). This DAG gives information on the requirements for and relationships between each step of your pipeline. The structure of a pipeline’s DAG is determined by the data dependencies between steps. These data dependencies are created when the properties of a step’s output are passed as the input to another step.
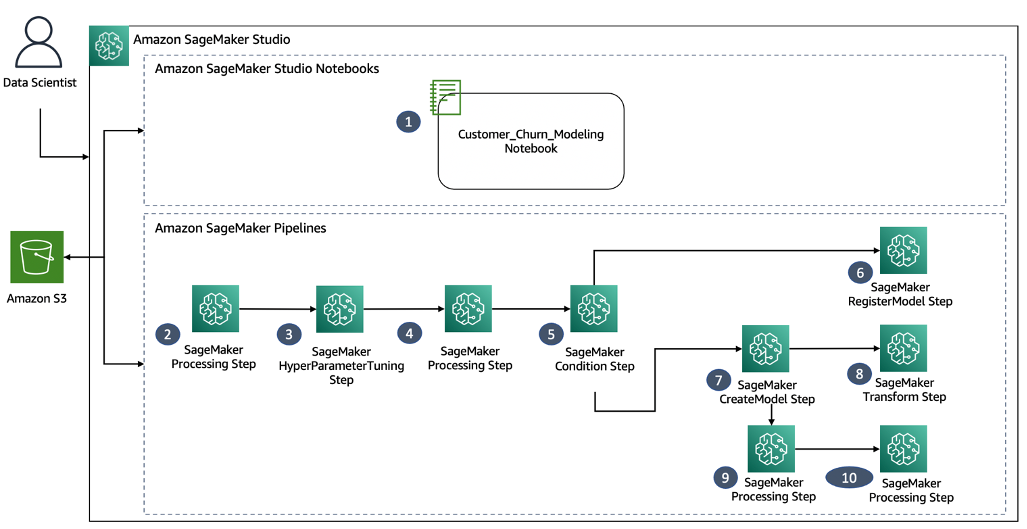
For this post, our use case is a classic ML problem that aims to understand what various marketing strategies based on consumer behavior we can adopt to increase customer retention for a given retail store. The following diagram illustrates the complete ML workflow for the churn prediction use case.
Let’s go through the accelerated ML workflow development process in detail.
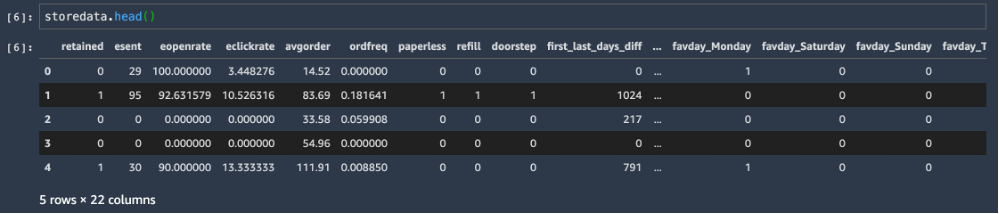
The following screenshot shows the sample set with the target variable as retained 1, if customer is assumed to be active, or 0 otherwise.
Run the following code in a Studio notebook to preprocess the dataset and upload it to your own S3 bucket:
With Studio notebooks with elastic compute, you can now easily run multiple training and tuning jobs. For this use case, you use the SageMaker built-in XGBoost algorithm and SageMaker HPO with objective function as "binary:logistic" and "eval_metric":"auc".
def split_datasets(df):
y=df.pop("retained")
X_pre = df
y_pre = y.to_numpy().reshape(len(y),1)
feature_names = list(X_pre.columns)
X= np.concatenate((y_pre,X_pre),axis=1)
np.random.shuffle(X)
train,validation,test=np.split(X,[int(.7*len(X)),int(.85*len(X))])
return feature_names,train,validation,test
# Split dataset
feature_names,train,validation,test = split_datasets(storedata)
# Save datasets in Amazon S3
pd.DataFrame(train).to_csv(f"s3://{default_bucket}/data/train/train.csv",header=False,index=False)
pd.DataFrame(validation).to_csv(f"s3://{default_bucket}/data/validation/validation.csv",header=False,index=False)
pd.DataFrame(test).to_csv(f"s3://{default_bucket}/data/test/test.csv",header=False,index=False)
Train, tune, and find the best candidate model with the following code:
# Training and Validation Input for SageMaker Training job
s3_input_train = TrainingInput(
s3_data=f"s3://{default_bucket}/data/train/",content_type="csv")
s3_input_validation = TrainingInput(
s3_data=f"s3://{default_bucket}/data/validation/",content_type="csv")
# Hyperparameter used
fixed_hyperparameters = {
"eval_metric":"auc",
"objective":"binary:logistic",
"num_round":"100",
"rate_drop":"0.3",
"tweedie_variance_power":"1.4"
}
# Use the built-in SageMaker algorithm
sess = sagemaker.Session()
container = sagemaker.image_uris.retrieve("xgboost",region,"0.90-2")
estimator = sagemaker.estimator.Estimator(
container,
role,
instance_count=1,
hyperparameters=fixed_hyperparameters,
instance_type="ml.m4.xlarge",
output_path="s3://{}/output".format(default_bucket),
sagemaker_session=sagemaker_session
)
hyperparameter_ranges = {
"eta": ContinuousParameter(0, 1),
"min_child_weight": ContinuousParameter(1, 10),
"alpha": ContinuousParameter(0, 2),
"max_depth": IntegerParameter(1, 10),
}
objective_metric_name = "validation:auc"
tuner = HyperparameterTuner(
estimator, objective_metric_name,
hyperparameter_ranges,max_jobs=10,max_parallel_jobs=2)
# Tune
tuner.fit({
"train":s3_input_train,
"validation":s3_input_validation
},include_cls_metadata=False)
## Explore the best model generated
tuning_job_result = boto3.client("sagemaker").describe_hyper_parameter_tuning_job(
HyperParameterTuningJobName=tuner.latest_tuning_job.job_name
)
job_count = tuning_job_result["TrainingJobStatusCounters"]["Completed"]
print("%d training jobs have completed" %job_count)
## 10 training jobs have completed
## Get the best training job
from pprint import pprint
if tuning_job_result.get("BestTrainingJob",None):
print("Best Model found so far:")
pprint(tuning_job_result["BestTrainingJob"])
else:
print("No training jobs have reported results yet.")

After you establish a baseline, you can use Amazon SageMaker Debugger for offline model analysis. Debugger is a capability within SageMaker that automatically provides visibility into the model training process for real-time and offline analysis. Debugger saves the internal model state at periodic intervals, which you can analyze in real time during training and offline after the training is complete. For this use case, you use the explainability tool SHAP (SHapley Additive exPlanation) and the native integration of SHAP with Debugger. Refer to the following notebook for detailed analysis.
The following summary plot explains the positive and negative relationships of the predictors with the target variable. For example, the top variable here, esent, is defined as number of emails sent. This plot is made of all data points in the training set. Blue indicates dragging the final output to class 0, and pink represents class 1. Key influencing features are ranked in descending order.

Now you can proceed with the deploy and manage step of the ML workflow.
Develop and automate the workflow
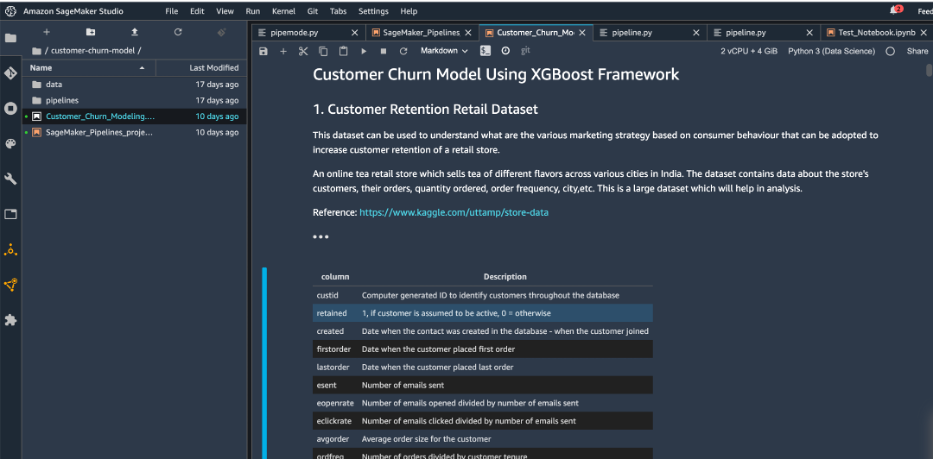
Let’s start with the project structure:
- /customer-churn-model – Project name
- /data – Dataset
- /pipelines – Code for SageMaker pipeline components
- SageMaker_Pipelines_project.ipynb – Allows you to create and run the ML workflow
- Customer_Churn_Modeling.ipynb – Baseline model development notebook

Under <project-name>/pipelines/customerchurn, you can see the following Python scripts:
- Preprocess.py – Integrates with SageMaker Processing for feature engineering
- Evaluate.py – Allows model metrics calculation, in this case auc_score
- Generate_config.py – Allows dynamic configuration needed for the downstream Clarify job for model explainability
- Pipeline.py – Templatized code for the Pipelines ML workflow

Let’s walk through every step in the DAG and how they run. The steps are similar to when we first prepared the data.
Perform data readiness with the following code:
# processing step for feature engineering
sklearn_processor = SKLearnProcessor(
framework_version="0.23-1",
instance_type=processing_instance_type,
instance_count=processing_instance_count,
sagemaker_session=sagemaker_session,
role=role,
)
step_process = ProcessingStep(
name="ChurnModelProcess",
processor=sklearn_processor,
inputs=[
ProcessingInput(source=input_data, destination="/opt/ml/processing/input"),
],
outputs=[
ProcessingOutput(output_name="train", source="/opt/ml/processing/train",\
destination=f"s3://{default_bucket}/output/train" ),
ProcessingOutput(output_name="validation", source="/opt/ml/processing/validation",\
destination=f"s3://{default_bucket}/output/validation"),
ProcessingOutput(output_name="test", source="/opt/ml/processing/test",\
destination=f"s3://{default_bucket}/output/test")
],
code=f"s3://{default_bucket}/input/code/preprocess.py",
)
Train, tune, and find the best candidate model:
# training step for generating model artifacts
model_path = f"s3://{default_bucket}/output"
image_uri = sagemaker.image_uris.retrieve(
framework="xgboost",
region=region,
version="1.0-1",
py_version="py3",
instance_type=training_instance_type,
)
fixed_hyperparameters = {
"eval_metric":"auc",
"objective":"binary:logistic",
"num_round":"100",
"rate_drop":"0.3",
"tweedie_variance_power":"1.4"
}
xgb_train = Estimator(
image_uri=image_uri,
instance_type=training_instance_type,
instance_count=1,
hyperparameters=fixed_hyperparameters,
output_path=model_path,
base_job_name=f"churn-train",
sagemaker_session=sagemaker_session,
role=role,
)
hyperparameter_ranges = {
"eta": ContinuousParameter(0, 1),
"min_child_weight": ContinuousParameter(1, 10),
"alpha": ContinuousParameter(0, 2),
"max_depth": IntegerParameter(1, 10),
}
objective_metric_name = "validation:auc"
You can add a model tuning step (TuningStep) in the pipeline, which automatically invokes a hyperparameter tuning job (see the following code). The hyperparameter tuning finds the best version of a model by running many training jobs on the dataset using the algorithm and the ranges of hyperparameters that you specified. You can then register the best version of the model into the model registry using the RegisterModel step.
## Direct Integration for HPO
step_tuning = TuningStep(
name = "ChurnHyperParameterTuning",
tuner = HyperparameterTuner(xgb_train, objective_metric_name, hyperparameter_ranges, max_jobs=2, max_parallel_jobs=2),
inputs={
"train": TrainingInput(
s3_data=step_process.properties.ProcessingOutputConfig.Outputs[
"train"
].S3Output.S3Uri,
content_type="text/csv",
),
"validation": TrainingInput(
s3_data=step_process.properties.ProcessingOutputConfig.Outputs[
"validation"
].S3Output.S3Uri,
content_type="text/csv",
),
},
)

After you tune the model, depending on the tuning job objective metrics, you can use branching logic when orchestrating the workflow. For this post, the conditional step for model quality check is as follows:
# condition step for evaluating model quality and branching execution
cond_lte = ConditionGreaterThan(
left=JsonGet(
step=step_eval,
property_file=evaluation_report,
json_path="classification_metrics.auc_score.value"
),
right=0.75,
)
The best candidate model is registered for batch scoring using the RegisterModel step:
step_register = RegisterModel(
name="RegisterChurnModel",
estimator=xgb_train,
model_data=step_tuning.get_top_model_s3_uri(top_k=0,s3_bucket=default_bucket,prefix="output"),
content_types=["text/csv"],
response_types=["text/csv"],
inference_instances=["ml.t2.medium", "ml.m5.large"],
transform_instances=["ml.m5.large"],
model_package_group_name=model_package_group_name,
model_metrics=model_metrics,
)
Now that the model is trained, let’s see how Clarify helps us understand what features the models base their predictions on. You can create an analysis_config.json file dynamically per workflow run using the generate_config.py utility. You can version and track the config file per pipeline runId and store it in Amazon S3 for further references. Initialize the dataconfig and modelconfig files as follows:
data_config = sagemaker.clarify.DataConfig(
s3_data_input_path=f's3://{args.default_bucket}/output/train/train.csv',
s3_output_path=args.bias_report_output_path,
label=0,
headers= ['target','esent','eopenrate','eclickrate','avgorder','ordfreq','paperless','refill','doorstep','first_last_days_diff','created_first_days_diff','favday_Friday','favday_Monday','favday_Saturday','favday_Sunday','favday_Thursday','favday_Tuesday','favday_Wednesday','city_BLR','city_BOM','city_DEL','city_MAA'],
dataset_type="text/csv",
)
model_config = sagemaker.clarify.ModelConfig(
model_name=args.modelname,
instance_type=args.clarify_instance_type,
instance_count=1,
accept_type="text/csv",
)
model_predicted_label_config = sagemaker.clarify.ModelPredictedLabelConfig(probability_threshold=0.5)
bias_config = sagemaker.clarify.BiasConfig(
label_values_or_threshold=[1],
facet_name="doorstep",
facet_values_or_threshold=[0],
)
After you add the Clarify step as a postprocessing job using sagemaker.clarify.SageMakerClarifyProcessor in the pipeline, you can see a detailed feature and bias analysis report per pipeline run.



As the final step of the pipeline workflow, you can use the TransformStep step for offline scoring. Pass in the transformer instance and the TransformInput with the batch_data pipeline parameter defined earlier:
# step to perform batch transformation
transformer = Transformer(
model_name=step_create_model.properties.ModelName,
instance_type="ml.m5.xlarge",
instance_count=1,
output_path=f"s3://{default_bucket}/ChurnTransform"
)
step_transform = TransformStep(
name="ChurnTransform",
transformer=transformer,
inputs=TransformInput(data=batch_data,content_type="text/csv")
)
Finally, you can trigger a new pipeline run by choosing Start an execution on the Studio IDE interface.

You can also describe a pipeline run or start the pipeline using the following notebook. The following screenshot shows our output.

You can schedule your SageMaker model building pipeline runs using Amazon EventBridge. SageMaker model building pipelines are supported as a target in Amazon EventBridge. This allows you to trigger your pipeline to run based on any event in your event bus. EventBridge enables you to automate your pipeline runs and respond automatically to events such as training job or endpoint status changes. Events include a new file being uploaded to your S3 bucket, a change in status of your SageMaker endpoint due to drift, and Amazon Simple Notification Service (Amazon SNS) topics.
Conclusion
This post explained how to use SageMaker Pipelines with other built-in SageMaker features and the XGBoost algorithm to develop, iterate, and deploy the best candidate model for churn prediction. For instructions on implementing this solution, see the GitHub repo. You can also clone and extend this solution with additional data sources for model retraining. We encourage you to reach out and discuss your ML use cases with your AWS account manager.
Additional references
For additional information, see the following resources:
About the Authors
 Gayatri Ghanakota is a Machine Learning Engineer with AWS Professional Services. She is passionate about developing, deploying, and explaining AI/ ML solutions across various domains. Prior to this role, she led multiple initiatives as a data scientist and ML engineer with top global firms in the financial and retail space. She holds a master’s degree in Computer Science specialized in Data Science from the University of Colorado, Boulder.
Gayatri Ghanakota is a Machine Learning Engineer with AWS Professional Services. She is passionate about developing, deploying, and explaining AI/ ML solutions across various domains. Prior to this role, she led multiple initiatives as a data scientist and ML engineer with top global firms in the financial and retail space. She holds a master’s degree in Computer Science specialized in Data Science from the University of Colorado, Boulder.
 Sarita Joshi is a Senior Data Scientist with AWS Professional Services focused on supporting customers across industries including retail, insurance, manufacturing, travel, life sciences, media and entertainment, and financial services. She has several years of experience as a consultant advising clients across many industries and technical domains, including AI, ML, analytics, and SAP. Today, she is passionately working with customers to develop and implement machine learning and AI solutions at scale.
Sarita Joshi is a Senior Data Scientist with AWS Professional Services focused on supporting customers across industries including retail, insurance, manufacturing, travel, life sciences, media and entertainment, and financial services. She has several years of experience as a consultant advising clients across many industries and technical domains, including AI, ML, analytics, and SAP. Today, she is passionately working with customers to develop and implement machine learning and AI solutions at scale.