Artificial Intelligence
Analyze customer churn probability using call transcription and customer profiles with Amazon SageMaker
Regardless of the industry or product, customers are the most important component in a business’s success and growth. Businesses go to great lengths to acquire and more importantly retain their existing customers. Customer satisfaction links directly to revenue growth, business credibility, and reputation. These are all key factors in a sustainable and long-term business growth strategy.
Given the marketing and operational costs of customer acquisition and satisfaction, and how costly losing a customer to a competitor can be, generally it’s less costly to retain new customers. Therefore, it’s crucial for businesses to understand why and when a customer might stop using their services or switch to a competitor, so they can take proactive measures by providing incentives or offering upgrades for new packages that could encourage the customer to stay with the business.
Customer service interactions provide invaluable insight into the customer’s opinion about the business and its services, and can be used, in addition to other quantitative factors, to enable the business to better understand the sentiment and trends of customer conversations and to identify crucial company and product feedback. Customer churn prediction using machine learning (ML) techniques can be a powerful tool for customer service and care.
In this post, we walk you through the process of training and deploying a churn prediction model on Amazon SageMaker that uses Hugging Face Transformers to find useful signals in customer-agent call transcriptions. In addition to textual inputs, we show you how to incorporate other types of data, such as numerical and categorical features in order to predict customer churn.
| Interested in learning more about customer churn models? These posts might interest you: |
Prerequisites
To try out the solution in your own account, make sure that you have the following in place:
- An AWS account. If you don’t have an account, you can sign up for one.
- The solution outlined in the post is part of Amazon SageMaker JumpStart. To run this JumpStart 1P solution and have the infrastructure deploy to your AWS account, you must create an active Amazon SageMaker Studio instance (see Onboard to Amazon SageMaker Studio). When your Studio instance is ready, use the instructions in JumpStart to launch the solution.
 The JumpStart solution launch creates the resources properly set up and configured to successfully run the solution.
The JumpStart solution launch creates the resources properly set up and configured to successfully run the solution.
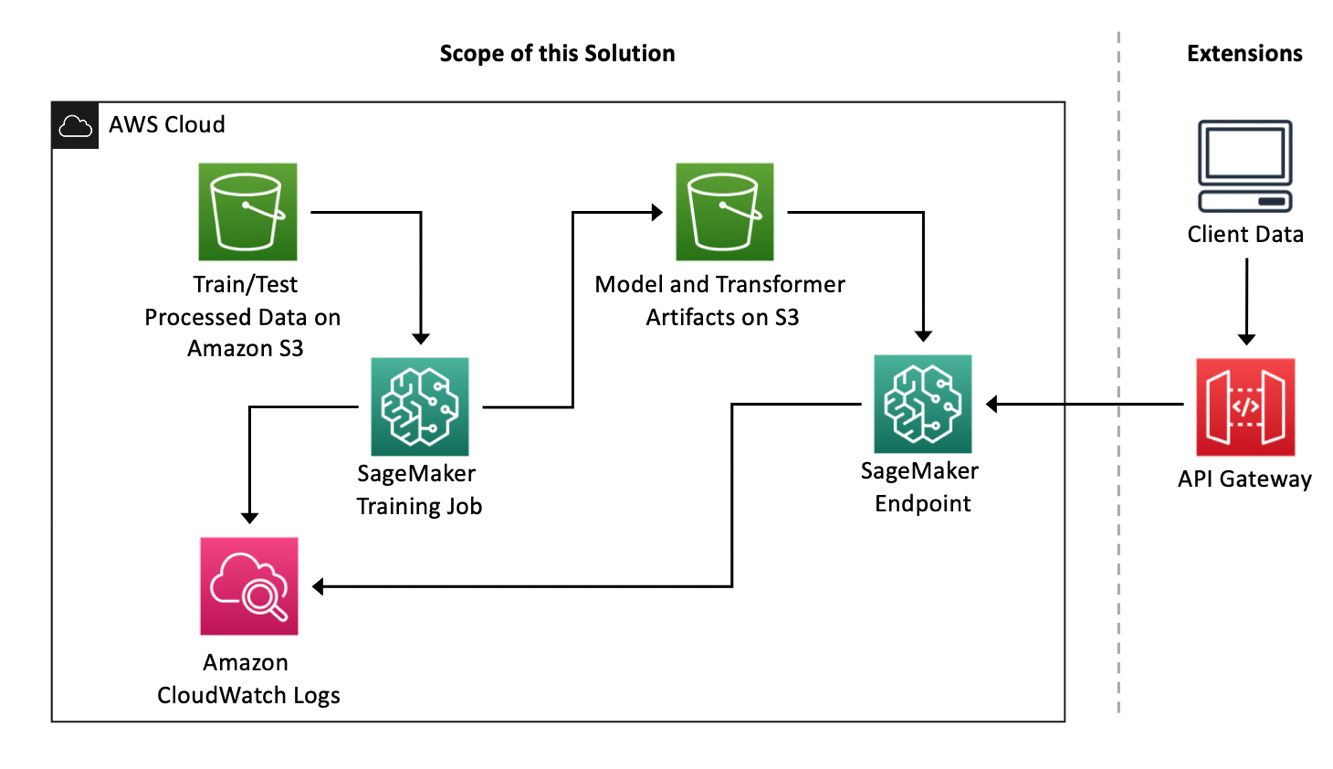
Architecture overview
In this solution, we focus on SageMaker components. We use SageMaker training jobs to train the churn prediction model and a SageMaker endpoint to deploy the model. We use Amazon Simple Storage Service (Amazon S3) to store the training data and model artifacts, and Amazon CloudWatch to log training and endpoint outputs. The following figure illustrates the architecture for the solution.
Exploring the data
In this post, we use a mobile operator’s historical records of which customers ended up churning and which continued using the service. The data also includes transcriptions of the latest phone call conversations between the customer and the agent (which could also be the streaming transcription as the call is happening). We can use this historical information to train an ML classifier model, which we can then use to predict the probability of customer churn based on the customer’s profile information and the content of the phone call transcription. We create a SageMaker endpoint to make real-time predictions using the model and provide more insight to customer service agents as they handle customer phone calls.
The dataset we use is synthetically generated and available under the CC BY 4.0 license. The data used to generate the numerical and categorical features is based on the public dataset KDD Cup 2009: Customer relationship prediction. We have generated over 50,000 samples and randomly split the data into 45,000 samples for training and 5,000 samples for testing. In addition, the phone conversation transcripts were synthetically generated using the GPT2 (Generative Pre-trained Transformer 2) algorithm. The data is hosted on Amazon S3.
More details on customer churn classification models using similar data, and also step-by-step instructions on how to build a binary classifier model using similar data, can be found in the blog post Predicting Customer Churn with Amazon Machine Learning. That post is focused more on binary classification using the tabular data. This blog post approaches this problem from a different perspective, and brings in natural language processing (NLP) by processing the context of agent-customer phone conversations.
The following are the attributes (features) of the customer profiles dataset:
- CustServ Calls – The number of calls placed to customer service
- State: The US state in which the customer resides, indicated by a two-letter abbreviation; for example, OH or NJ
- VMail Message – The average number of voice mail messages per month
- Account Length – The number of days that this account has been active
- Day Mins, Day Calls, Day Charge – The billed cost for calls placed during the day
- Eve Mins, Eve Calls, Eve Charge – The billed cost for calls placed during the evening
- Night Mins, Night Calls, Night Charge – The billed cost for calls placed during nighttime
- Intl Mins, Intl Calls, Intl Charge – The billed cost for international calls
- Location – Whether the customer is located in urban, suburban, rural, or other areas
- State – The state location of the customer
- Plan – The plan category
- Limit – Limited or unlimited plan type
- Text – The synthetic GPT-2 generated transcription of the customer-agent phone conversation
- Y: Whether the customer left the service (true/false)
The last attribute, Y, is known as the target feature, or the feature we want the ML model to predict. Because the target feature is binary (true/false), the type of modeling is a binary classification model. The model we train later in this post predicts the likelihood of churn as well.
We don’t go over exploratory data analysis in this post. For more details, see Predicting Customer Churn with Amazon Machine Learning and the Customer Churn Prediction with XGBoost sample notebook.
The training script is developed to allow the ML practitioner to pick and choose the features used in training. For example, we don’t use all the features in training. We focus more on the maturity of the customer’s account, number of times the customer has contacted customer service, type of plan they have, and transcription of the latest phone call. You can use additional features in training by including the list in the hyperparameters, as we show in the next section.
The transcription of customer-agent phone call in the text column is synthetic text generated by ML models using the GPT2 algorithm. Its purpose is to show how you can apply this solution to real-world customer service phone conversations. GPT2 is an unsupervised transformer language model developed by OpenAI. It’s a powerful generative NLP model that excels in processing long-range dependencies, and is pre-trained on a diverse corpus of text. For more details on how to generate text using GPT2, see Experimenting with GPT-2 XL machine learning model package on Amazon SageMaker and the Creative Writing using GPT2 Text Generation example notebook.
Train the model
For this post, we use the SageMaker PyTorch Estimator to build a SageMaker estimator using an Amazon-built Docker container that runs functions defined in the supplied entry_point Python script within a SageMaker training job. The training job is started by calling .fit() on this estimator. Later, we deploy the model by calling the .deploy() method on the estimator. Visit Amazon SageMaker Python SDK technical documentation for more details on preparing PyTorch scripts for SageMaker training and using the PyTorch Estimator.
Also, visit Available Deep Learning Containers Images on GitHub to get a list of supported PyTorch versions. At the time of this writing, the latest version available is PyTorch 1.8.1 with Python version 3.6. You can update the framework version to the latest supported version by changing the framework_version parameter in the PyTorch Estimator. You can also use SageMaker utility API image URIs to get the latest list of supported versions.
The hyperparameters dictionary defines which features we want to use for training and also the number of trees in the forest (n-estimators) for the model. You can add any other hyperparameters for the RandomForestClassifier; however, you also need revise your custom training script to receive these parameters in the form of arguments (using the argparse library) and add them to your model. See the following code:
If you launched the SageMaker JumpStart solution in your account, the custom scripts are available in your Studio files. We use the entry_point.py script. This script receives a list of numerical features, categorical features, textual features, and the target label, and trains a SKLearn RandomForestClassifier on the data. However, the key here is processing the features before using them in the classifier, especially the call transcription. The following figure shows this process, which applies imputing to numerical features and replaces missing values with mean, one-hot encoding to categorical features, and embeds transformers to textual features.
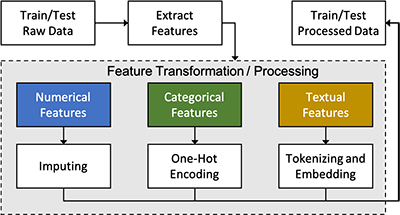
The purpose of the script presented in this post is to provide an example of how you can develop your own custom feature transformation pipeline. You can apply other transformations to the data based on your specific use case and the nature of your dataset, and make it as complex or as simple as you want. For example, depending on the nature of your dataset and the results of the exploratory data analysis, you may want to consider normalization, log transformation, or dropping records with null values. For a more complete list of feature transformation techniques, visit SKLearn Dataset Transformations.
The following code snippet shows you how to instantiate these transformers for numerical and categorical features, and how to apply them to your dataset. More details on how these are done in the training script is available in the entry_point.py script that is launched in your files by the JumpStart solution.
Now let’s focus on the textual data. We use Hugging Face sentence transformers, which you can use for sentence embedding generation. They come with pre-trained models that you can use out of the box based on your use case. In this post, we use the bert-base-nli-cls-token model, which is described in Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks.
Recently, SageMaker introduced new Hugging Face Deep Learning Containers (DLCs) that enable you to train, fine-tune, and run inference using Hugging Face models for NLP on SageMaker. In this post, we use the PyTorch container and a custom training script. For this purpose, in our training script, we define a BertEncoder class based on Hugging Face SentenceTransformer and define the pre-trained model as bert-base-nli-cls-token, as shown in the following code. The reason for this is to be able to apply the transformer to the dataset in the same way as the other dataset transformers, with the applying .transform() method. The benefit of using Hugging Face pre-trained models is that you don’t need to do additional training to be able to use the model. However, you can still fine-tune the models with custom data, as described in Fine-tuning a pretrained model.
Now that the dataset is processed and ready to be consumed by an ML model, we can train any classifier model to predict if a customer will churn or not. In addition to predicting the class (0/1 or true/false) for customer churn, these models also generate the probability of each class, meaning the probability of a customer churning. This is particularly useful for customer service teams for strategizing the incentives or upgrades they can offer to the customer based on how likely the customer is to cancel the service or subscription. In this post, we use the SKLearn RandomForestClassifier model. You can choose from many hyperparameters for this model and also optimize the hyperparameters for a more accurate model prediction by using strategies like grid search, random search, and Bayesian search. SageMaker automatic hyperparameter tuning can be a powerful tool for this purpose.
Training the model in entry_point.py is handled by the train_fn() function in the custom script. This function is called when the .fit() method is applied to the estimator. This function also stores the trained model and trained data transformers on Amazon S3. These files are used later by model_fn() to load the model for inference purposes.
train_fn() also includes evaluation of the trained model, and provides accuracy scores for the model for both train and test datasets. This helps you better evaluate model performance. Because this is a classification problem, we recommend including other metrics in your evaluation script, for example F1 score, ROC AUC score, and recall score, the same way we added accuracy scores. These are printed as the training progresses. Because we’re using synthetic data for training the model in this example notebook, especially for the agent-customer call transcription, we’re not expecting to see high-performing models with regards to classification metrics, and therefore we’re not focusing on these metrics in this example. However, when you use your own data, you should consider how each classification metric could impact the applicability of the model to your use case. Training this model on 45,000 samples on an ml.p3.2xlarge instance takes about 30 minutes.
When you’re comfortable with the performance of your model, you can move to the next step, which is deploying your model for real-time inference.
Deploy the model
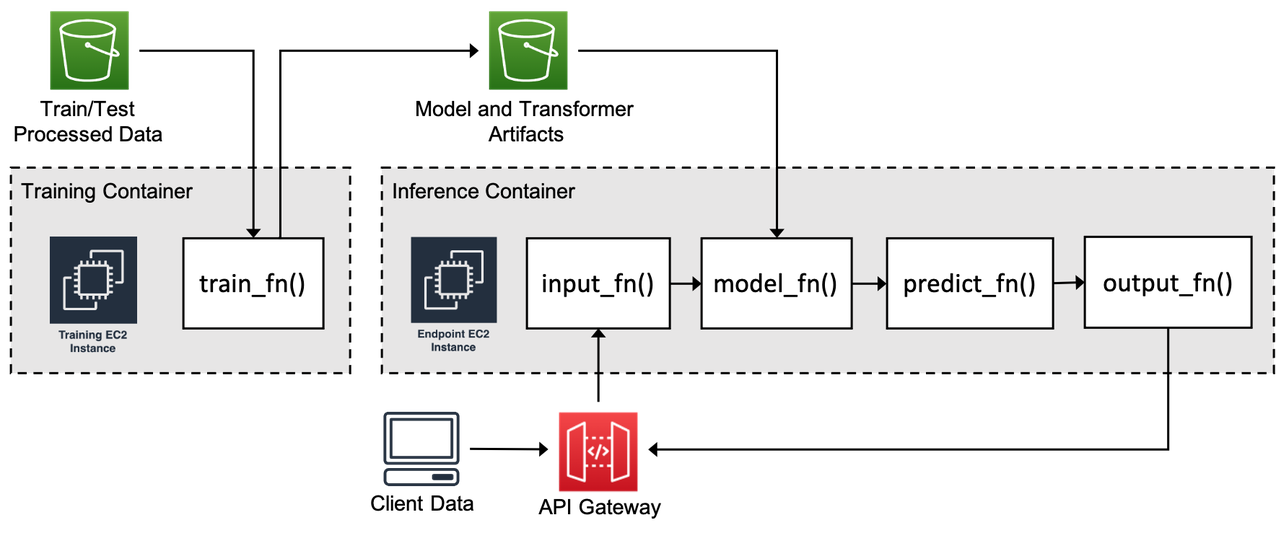
When the training is complete, you can deploy the model as a SageMaker hosted endpoint for real-time inference, or use the model for offline batch inference, using SageMaker batch transform. The task of performing inference (either real time or batch) is handled by four main functions in the custom script:
input_fn()processes the input datamodel_fn()loads the trained model artifacts from Amazon S3predict_fn()makes predictionsoutput_fn()prepares the model output
The following diagram illustrates this process.
The following script is a snippet of the entry_point.py script, and shows how the four functions work together to perform inference:
To deploy the model, when the training is complete, we use the .deploy() method on the estimator and define the number and type of instances we want to attach to the endpoint, and SageMaker manages the infrastructure on your behalf. When calling the endpoint from the notebook, we use a SageMaker SDK predictor. The predictor sends data to an endpoint (as part of a request), and interprets the response. See the following code:
This deploys the model as an endpoint predictor. After deployment is complete, we can use that to make predictions on sample data. Let’s determine the probability of churn for a hypothetical customer:
In this case, the probability of churn is about 31%. For the same customer, we change the transcript to “I have been using your service for 6 months and I am disappointed in your customer service.” The probability of churn increases to over 46%. This demonstrates that a change in the customer’s sentiment affects the probability of churn.
Clean up
To clean up the resources and stop incurring charges in your account, you can delete the endpoint:
Extensions
As we explained earlier, you can use additional features in training and also incorporate more feature transformers in the feature engineering pipeline, which can help improve model performance.
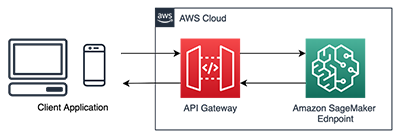
In addition, now that you have a working endpoint that is performing real-time inference, you can use it for your applications or website. However, your SageMaker endpoint is still not public facing, so you need to build an API Gateway to allow external traffic to your SageMaker endpoint. Amazon API Gateway is a fully managed service that makes it easy for developers to create, publish, maintain, monitor, and secure APIs at any scale. You can use API Gateway to present an external-facing, single point of entry for SageMaker endpoints, and provide security, throttling, authentication, firewall as provided by AWS WAF, and more. With API Gateway mapping templates, you can invoke your SageMaker endpoint with a REST API request and receive an API response back without needing any intermediate AWS Lambda functions, thereby improving the performance and cost-effectiveness of your applications.
To create an API Gateway and use it to perform real-time inference with your SageMaker endpoint (see the following architecture), you can follow the instructions outlined in Creating a machine learning-powered REST API with Amazon API Gateway mapping templates and Amazon SageMaker.
In addition, you can use Amazon Transcribe to generate transcriptions of recorded customer-agent conversations and use them for training purposes, and also use Amazon Transcribe streaming to send the conversation audio stream and receive a stream of text in real time. You can use this text stream to add a real-time speech-to-text capability to your applications and also send that text to the endpoint and provide customer churn insights to your customer service agents in real time.
Conclusions
In this post, we explained an end-to-end solution for creating a customer churn prediction model based on customer profiles and customer-agent call transcriptions. The solution included training a PyTorch model with a custom script and creating an endpoint for real-time model hosting. We also explained how you can create a public-facing API Gateway that can be securely used in your mobile applications or website. In addition, we explained how you can use Amazon Transcribe for batch or real-time transcription of customer-agent conversations, which you can use for training of your model or real-time inference.
For more SageMaker examples, visit the Amazon SageMaker Examples GitHub repo. For more PyTorch BYO script examples, visit the following GitHub repository. For more SageMaker Python examples for MXNet, TensorFlow, and PyTorch, visit the Amazon SageMaker Pre-Built Framework Containers and the Python SDK GitHub repo. Additional information about SageMaker is available in the technical documentation.
About the Author
 Nick Minaie is an Sr AI/ML Specialist Solutions Architect with AWS, helping customers on their journey to well-architected machine learning solutions at scale. In his spare time, Nick enjoys family time, abstract painting, and exploring nature.
Nick Minaie is an Sr AI/ML Specialist Solutions Architect with AWS, helping customers on their journey to well-architected machine learning solutions at scale. In his spare time, Nick enjoys family time, abstract painting, and exploring nature.
 Ehsan M. Kermani is a Machine Learning Engineer in the AWS ML Automation Services group. He helps customers through their MLOps journey by providing his expertise in Software Engineering best practices to solve customers’ end-to-end Machine Learning tasks from infrastructure to deployment.
Ehsan M. Kermani is a Machine Learning Engineer in the AWS ML Automation Services group. He helps customers through their MLOps journey by providing his expertise in Software Engineering best practices to solve customers’ end-to-end Machine Learning tasks from infrastructure to deployment.
 Dr. Li Zhang is a Principal Product Manager-Technical for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms, a service that helps data scientists and machine learning practitioners get started with training and deploying their models, and uses reinforcement learning with Amazon SageMaker. His past work as a principal research staff member and master inventor at IBM Research has won the test of time paper award at IEEE INFOCOM.
Dr. Li Zhang is a Principal Product Manager-Technical for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms, a service that helps data scientists and machine learning practitioners get started with training and deploying their models, and uses reinforcement learning with Amazon SageMaker. His past work as a principal research staff member and master inventor at IBM Research has won the test of time paper award at IEEE INFOCOM.