Artificial Intelligence
Category: Management Tools

Accelerate agentic application development with a full-stack starter template for Amazon Bedrock AgentCore
In this post, you will learn how to deploy Fullstack AgentCore Solution Template (FAST) to your Amazon Web Services (AWS) account, understand its architecture, and see how to extend it for your requirements. You will learn how to build your own agent while FAST handles authentication, infrastructure as code (IaC), deployment pipelines, and service integration.

Build a serverless AI Gateway architecture with AWS AppSync Events
In this post, we discuss how to use AppSync Events as the foundation of a capable, serverless, AI gateway architecture. We explore how it integrates with AWS services for comprehensive coverage of the capabilities offered in AI gateway architectures. Finally, we get you started on your journey with sample code you can launch in your account and begin building.

Build AI agents with Amazon Bedrock AgentCore using AWS CloudFormation
Amazon Bedrock AgentCore services are now being supported by various IaC frameworks such as AWS Cloud Development Kit (AWS CDK), Terraform and AWS CloudFormation Templates. This integration brings the power of IaC directly to AgentCore so developers can provision, configure, and manage their AI agent infrastructure. In this post, we use CloudFormation templates to build an end-to-end application for a weather activity planner.

Build a multimodal generative AI assistant for root cause diagnosis in predictive maintenance using Amazon Bedrock
In this post, we demonstrate how to implement a predictive maintenance solution using Foundation Models (FMs) on Amazon Bedrock, with a case study of Amazon’s manufacturing equipment within their fulfillment centers. The solution is highly adaptable and can be customized for other industries, including oil and gas, logistics, manufacturing, and healthcare.
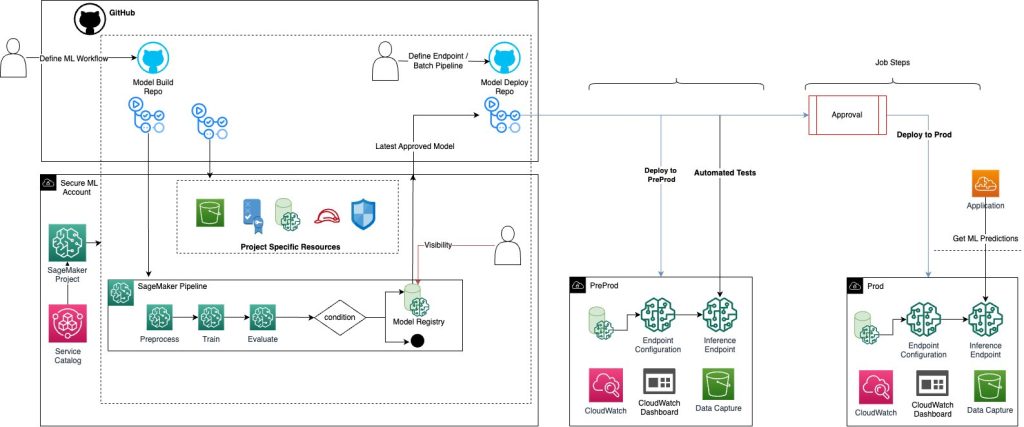
Implement a secure MLOps platform based on Terraform and GitHub
Machine learning operations (MLOps) is the combination of people, processes, and technology to productionize ML use cases efficiently. To achieve this, enterprise customers must develop MLOps platforms to support reproducibility, robustness, and end-to-end observability of the ML use case’s lifecycle. Those platforms are based on a multi-account setup by adopting strict security constraints, development best […]
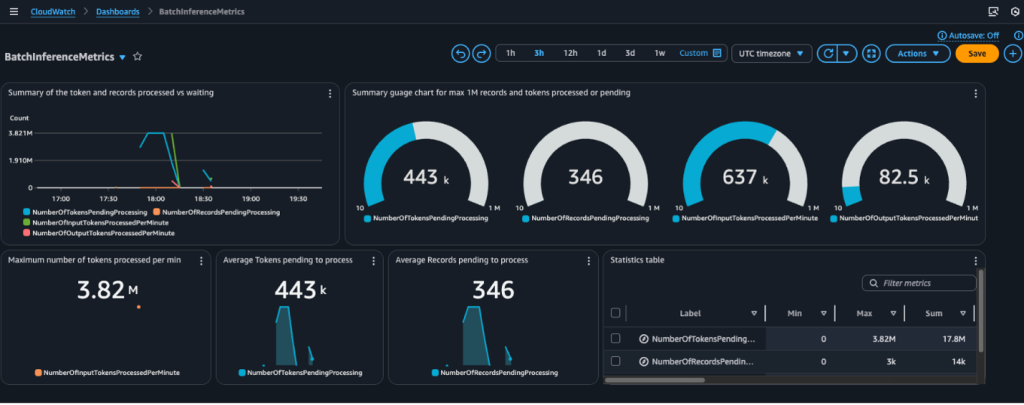
Monitor Amazon Bedrock batch inference using Amazon CloudWatch metrics
In this post, we explore how to monitor and manage Amazon Bedrock batch inference jobs using Amazon CloudWatch metrics, alarms, and dashboards to optimize performance, cost, and operational efficiency.
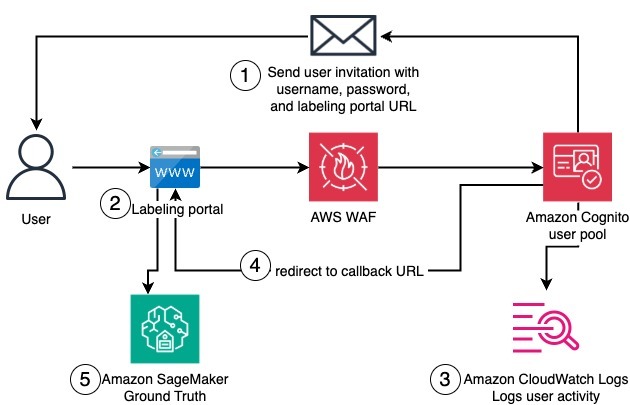
Create a private workforce on Amazon SageMaker Ground Truth with the AWS CDK
In this post, we present a complete solution for programmatically creating private workforces on Amazon SageMaker AI using the AWS Cloud Development Kit (AWS CDK), including the setup of a dedicated, fully configured Amazon Cognito user pool.

Accelerate foundation model development with one-click observability in Amazon SageMaker HyperPod
With a one-click installation of the Amazon Elastic Kubernetes Service (Amazon EKS) add-on for SageMaker HyperPod observability, you can consolidate health and performance data from NVIDIA DCGM, instance-level Kubernetes node exporters, Elastic Fabric Adapter (EFA), integrated file systems, Kubernetes APIs, Kueue, and SageMaker HyperPod task operators. In this post, we walk you through installing and using the unified dashboards of the out-of-the-box observability feature in SageMaker HyperPod. We cover the one-click installation from the Amazon SageMaker AI console, navigating the dashboard and metrics it consolidates, and advanced topics such as setting up custom alerts.

Advancing AI agent governance with Boomi and AWS: A unified approach to observability and compliance
In this post, we share how Boomi partnered with AWS to help enterprises accelerate and scale AI adoption with confidence using Agent Control Tower.

Get faster and actionable AWS Trusted Advisor insights to make data-driven decisions using Amazon Q Business
In this post, we show how to create an application using Amazon Q Business with Jira integration that used a dataset containing a Trusted Advisor detailed report. This solution demonstrates how to use new generative AI services like Amazon Q Business to get data insights faster and make them actionable.