AWS for M&E Blog
Introducing Media2Cloud: A serverless framework for media archive ingest to the cloud
The launch of our new Media2Cloud solution is an example of how serverless can reinvent ingest workflows and simplify the process of placing video content under management in AWS, and more importantly, back in the control of the content owner. The following document outlines the issues with managing large scale video content on-premise and how Media2Cloud can help customers and partners establish an elastic ingest model.
THE PROBLEM WITH CURRENT MEDIA ARCHIVES
Video archives contain a treasure trove of history and opportunity for content owners. The rise of new content producers and distributers has created new use cases for video archives. For example, a documentarian looking for all local news footage around a notable story or politician or a sports broadcaster looking to create highlight reels of a recently retired player.

However, video archives are only as valuable as the content within them is discoverable and accessible by the owner. When archives are in physical tape or offline formats, the friction for discovery increases dramatically: owners must manage video assets from different generations of physical storage, codecs, and varying metadata standards.
In over twenty years working with video archives, I’ve had the pleasure of working with amazing people. By and large, all charged with a similar mission: preserving, curating and providing access to their company or institution’s video assets, often managing several generations of video formats, proprietary systems, varying metadata standards, evolving technologies, and a growing number of use-cases to leverage the content (if you can find it). In many of these situations, the organizations frequently feel like they are treading water, working to meet the immediate content requirements in front of them. The disorganization of content often results in duplicate processes, duplicate content, and lots of stored content that may have no value. Many archive owners have large stores of video content that is maintained in case it has value. Unfortunately, the known cost to review the content frequently delays any review process from ever being scheduled.
INTRODUCING CLOUD-BASED CONTENT AND DATA LAKES
The AWS cloud provides an environment that can help address these challenges. Content Lakes help customers evolve from legacy environments where content is stored in multiple locations like NAS, SAN, HSMs, LTO Robots, desktops, and offline physical media. The Amazon Simple Storage Service (S3) integrated with Glacier creates an environment where all content can be stored centrally and leveraged by multiple services, organizations and third-party service providers. This creates an environment where content access can truly be controlled with multiple security mechanisms including encryption at rest and in transit. Content owners don’t need to be worried about the disappearance of critical creative content on a LTO or portable hard drive. The 11 nines of durability, high performance capabilities of S3, combined with the economical tiering with Glacier, provide a safe storage environment free of technology refresh issues. The recent introduction of Intelligent Tiering in storage removes the need to guess at life cycle policies; content owners can store their content in S3 and let it move automatically to the most economical storage tier based on usage. The centralized storage structure helps customers designate a logical storage structure that reduces complexity and redundant processes.
MEDIA2CLOUD
In order to help customers process and place video content under management, we created a service ingest framework, Media2Cloud, that makes it easy to set up an elastic ingest service that covers the standard essentials for ingesting video content like assigning a UUID, running a MD5 checksum, technical metadata extraction (leveraging Mediainfo), and the creation of proxies of thumbnails. In addition to this process, the framework includes a trigger to augment the baseline metadata of the video assets with AWS Machine Learning. The video asset will have object and face recognition performed with Amazon Rekognition, speech to text is created via Amazon Transcribe, and contextual metadata is created using Amazon Comprehend.
It should also be noted that since the service is elastic, the ingest service can be used to support day to day production and archive migration ingest as long as the requirements are the same. There’s no need to create separate workflows.
In order to enable the customer to over the on-premise challenges, companies like Cloudfirst.io bridge the gap. Cloudfirst.io is an AWS Partner that specializes in large-scale, unstructured, archive and content storage management solutions for Media and Entertainment. They actively assist customers with complex, legacy archive migrations helping them establish a migration-to-cloud strategy that does not interfere with day-to-day production activity.
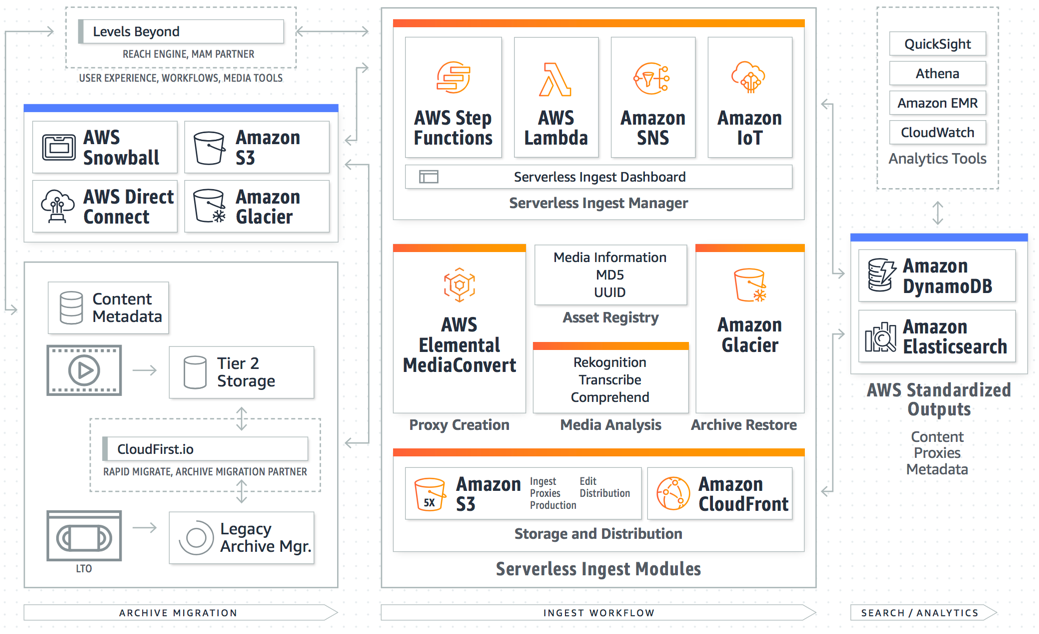
Cloudfirst offers a SaaS based tool called Rapid Migrate which helps clients with the heavy-lifting of legacy on-premise, proprietary tape archive systems (i.e. Masstech, Oracle DIVA, SGL, Quantum and IBM) to the cloud. The system essentially provides a means to take advantage of unused resources without interfering with the complexities of existing content workflows. This service enables the mass-migration of assets to AWS Snowball or AWS S3 cloud storage in a non-proprietary video format and sidecar metadata file.
It’s key to note that customers will still want a MAM to import and manage this content and metadata. The Content Lake architecture affords the customer the option to interface multiple systems to the content to power their business. For the initial launch, we reached out to Levels Beyond to work with us to develop the first version of standardized metadata and proxies. Levels Beyond is an AWS Partner that provides a MAM service platform called Reach Engine. Levels Beyond is able to manage Media2Cloud or interface with the output to consume the JSON formatted metadata to provide customers with a rich search, discovery and management service that can manage the content archive.
The basic interface provided for the content provides a strong baseline for a business to build out their MAM strategy in the cloud. Reach Engine can provide a number of visualizations to your content inventory, including Timeline Views that support unlimited ML/AI analysis, captioning and most any timeline-based search metaphor. Levels Beyond can support customers further by configuring the services to add additional metadata faceting as well as automating the processing of content for production, OTT, digital publishing and other content related services.
CONCLUSION
This is a game changer! It provides a single ingest strategy that can support both production and archive migrations within the same workflow; the infrastructure will expand and contract to match the processing needs required to create standardized assets and descriptive metadata. Most content owners will tell you that due to the varying state of metadata assets on-premise, they struggle to find what they are looking for in a timely manner. This is also true for content stored in LTO Robots and MAM systems. As employees turn over, often times the understanding of where to find valuable assets in the archive is lost. By adding machine learning metadata to each video asset, the minimum bar for search and discovery is raised substantially. This provides a means for customers to finally address metadata atrophy in their process and provides a sustainable means to improve management of content. The result of a serverless ingest framework like Media2Cloud provides customers with standardized proxies and metadata and a storage policy that protects masters in cost effective glacier storage. Customers and AWS technology partners can leverage this framework as a baseline setup and modify it to support several other ingest requirements; the framework is designed to speed up time to ingest.
Another important point: the content owner truly has control of their content! The assets and metadata are published in a manner that removes proprietary formatting. The point here is that this process can be managed within the customer’s AWS storage. The structure of the content lake creates an ideal environment for maintaining structured metadata, storage and access policies, and automated maintenance; all these factors result in reduced complexity and manual intervention. Customers can focus on higher business challenges such as greater content utility by improving the user experience and media tools that access the content. Customers can provide access to one or more MAM technology providers to empower different use-cases. This enables customers to choose to their MAM partners based on their ability to enable their content driven strategy.