Front-End Web & Mobile
Building Offline first applications with AWS Amplify DataStore – Part 1
Developers have been looking for ways to improve how applications are built and the Offline first approach is one example of this quest. In this series of two posts, I will show how AWS Amplify DataStore addresses the main challenges of building Offline first applications.
Introduction
The development of cloud native applications requires an environment to provide a full set of features and services that those applications can consume. On AWS, this means that you need an AWS account that you can use to set up the services and features needed by your applications. However, when building solutions that require an Offline first approach – a way of building applications that can provide core functionalities completely offline – how it can be achieved?
In 2019, AWS introduced AWS Amplify DataStore to simplify the development of offline applications with GraphQL. AWS Amplify DataStore helps customers to build Offline first applications without the need for an AWS account and simplifies control of their offline state.
This post aims to revisit the concept of Offline first applications and show customers how Amplify DataStore can solve problems like delta sync and conflict detection and resolution when data transitions from offline to online and vice-versa.
In the second part of this post, I will show you how Offline first application development can be achieved with an example in Flutter.
What is Offline first?
The concept of Offline first refers to the practice of planning, designing, and developing web and mobile applications and focusing on the user’s experience in a resource-constrained environment. For example, when there’s no network, GPS, or Bluetooth connectivity. In other words, it’s a way of building applications that can work and provide functionalities completely offline.
When we look back to better understand where this concept came from, we see that in 2008 the World Wide Web Consortium (W3C) working group published a note entitled Offline Web Applications. This note described some of the HTML 5 features that addressed the challenge of building web applications that worked while offline: the client-side SQL database, the offline application caching APIs, and other related attributes. The note also mentions that, at that time, when web applications went offline, users could no longer check their e-mails, calendar appointments, or use other online tools, while native applications provided those features through caching and local data storage.
In 2010, the W3C published the Mobile Web Application Best Practices recommendation to aid the development of rich and dynamic mobile web applications. This recommendation mentions the usage of offline technology considering that the user experience is influenced by latency, interaction method, and data consistency.
With the technology evolution of both mobile web and native applications, more possibilities were presented and made available to the developers. They started looking for ways to improve the user’s experience when designing and implementing applications that could still work without connectivity. If you’re interested in looking for more resources about Offline first, then check this repository.
What are the main characteristics and challenges of the Offline first approach?
To plan and design the development of applications following the Offline first approach, it’s important to understand their main characteristics and challenges that you may face when the application returns to an online state. This understanding will help you decide which tools and frameworks can support the implementation of your application.
Consider the following challenges when adopting the Offline first approach:
- Local storage
- Data synchronization and conflict management
- Features not available offline
Local storage
When your application is in an offline state, it should be able to store data on the device. This data could be messages, comments, to-do items, notes, photos, reactions (likes, +1, etc.), anything that your users can input. The local storage can be used in (but not limited to) two ways:
- To store data that your users provide. In this case, when the application is back to an online state, the data may be synchronized with a database or object storage in the cloud.
- To store data that your application caches when the connection is stable. This improves the performance of the application as the local data is retrieved faster than when retrieved from the network.
Data synchronization and conflict management
When your application is in an offline state, users can still keep using it and adding content to the device’s local storage. If your application stores this data in a remote database, for example, or must get data from it, then you must consider how to synchronize this data. While your application is in an offline state, the content in the back-end may have been updated. Assuming that changes happened at the same piece of data on both sides, how would you decide which change to keep? What if you have data changing at the same time? How would you manage these problems with concurrency while still maintaining the consistency of your data?
Those questions identified when following the Offline first approach lead developers to the next challenge to consider in having to manage those conflicts detections and resolutions.
Conflict management requires a lot of undifferentiated code to correctly handle all edge cases, and there are different strategies to address this challenge. For example, when looking to synchronization protocols, you can leverage different techniques of tagging objects with metadata (Vector Clocks, conflict-free replicated data types, or CRDTs). From a conflict resolution perspective, you must decide which strategy to follow, such as merging the changes, keeping the latest one, or implementing a customized strategy that you define according to your needs and based on your data structure.
Features not available offline
Your application may have features that require some form of connectivity to provide a positive user experience. Location services are an example of this scenario, and it’s important to have messaging mechanisms that inform users that specific features don’t work without a connection.
This last challenge will be independent of the set of technologies that you choose to develop your Offline first application.
Amplify DataStore to the rescue!
Customers told us that the task of synchronizing data across devices, handling offline operations, and managing data conflict is both time-consuming and difficult to implement. And this is even more so the case when developing several web and mobile applications.
Amplify DataStore is an on-device storage engine that automatically synchronizes data between your mobile and web applications and your database in the AWS cloud to help you build offline and real-time applications faster. Since its launch, Amplify DataStore has been evolving and providing front-end web and mobile developers with a persistent on-device storage repository to read, write, and observe changes to data even if you are offline, seamlessly synchronizing data to the cloud.
Amplify DataStore relies on GraphQL to facilitate the data modeling process, providing ways to add authorization rules or business logic into your application when needed. Once you have your GraphQL schema file, you can use the Amplify CLI to generate the code for a programming platform (JavaScript, Java, and Swift classes). With that, by configuring and initializing Amplify DataStore, the application is ready to start defining persistence operations using the model and the DataStore API. The combination of these three points (GraphQL, code generation, and DataStore API) covers the first challenge of Offline first applications: the local storage.
To solve the challenge of data synchronization and conflict management, Amplify DataStore uses AWS AppSync, a server-side managed component to provide simplified access, querying, real-time updates, offline synchronization, caching, security, and fine-grained access control of the application data. It also uses Amazon DynamoDB to create tables representing the schema defined at the application level.
Let’s dive deeper on this topic to discover how this is done with Amplify DataStore.
Local storage with Amplify DataStore
All Amplify DataStore operations are local first, which means that when you need to run a query to fetch data, it returns results from the local system that can after be sorted and filtered.
The operations that a developer can perform with DataStore in their client application are exposed through the DataStore API. This API, at runtime, will pass models into a Storage Engine that manages a repository of models defined by the developer’s GraphQL schema. The Storage Engine has a Storage Adapter, which in Amplify comes with default implementations such as SQLite and IndexedDB, and will perform the operations in the local storage applying the necessary conversion from GraphQL specific types to the appropriate data types in the database engine. This pattern allows contributions from the community and it isn’t limited to just one technology (e.g., SQL vs NoSQL).
The following figure shows an example of these components when a developer’s client application calls the DataStore API.
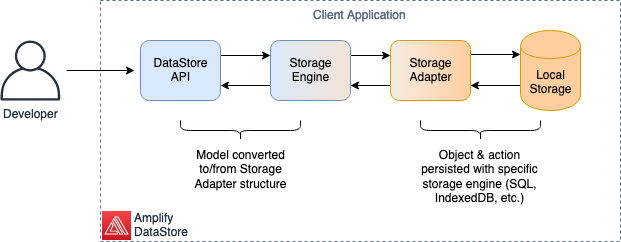
Figure 1: Local Storage Model Persistence
To implement the flow from this figure, you must focus on the data modeling in your application with GraphQL, and then build the code that will allow the DataStore API to operate on those instances.
GraphQL
GraphQL is a query language for your API that allows developers to describe their data and make requests containing only the information that they need to retrieve to get predictable results. This also includes a server-side runtime for executing queries using a type system that you define for your data which isn’t tied to any specific database or storage engine.
When developing applications following the Offline first approach with Amplify DataStore, you must start with the design of the GraphQL schema. A schema is a structured representation of the developer’s models, containing their data types and relationships. The GraphQL Schema provides syntax to define types, queries, and mutations.
- Type: this is the most basic component of a GraphQL schema and represents a kind of object that you can fetch from your service.
- Query: a specialized object type within a schema that defines the entry point of every GraphQL query. It represents an operation of read-only fetch.
- Mutation: another specialized object type within a schema that defines the changes that can be made to the types (create, update, and delete data). It represents an operation of a write followed by a fetch.
GraphQL also provides another type of operation called Subscription that is a long-lived request that fetches data in response to source events.
Amplify DataStore will use your GraphQL schema file as the definition of the application’s data model.
Code Generation
The code generation process generates native code that represent the GraphQL API’s data models and the GraphQL statements (queries, mutations, and subscriptions) for Swift (iOS), Java (Android), and JavaScript. Also called modelgen, this process can be triggered using the Amplify CLI or manually.
Data synchronization and conflict management with Amplify DataStore
At some point, you might want your application to store the client’s data in the cloud. When you choose to synchronize the data with the cloud, you must have the cloud resources available for the data to be synchronized. The Amplify CLI will use the GraphQL schema to deploy the AWS AppSync and the DynamoDB tables needed to represent your model defined by the schema at the application level. It will also deploy other AWS services, such as Amazon Cognito or AWS Lambda, if they were added to the project.
By default, DataStore uses DynamoDB as the database. However, developers can choose another database to store the data by creating custom AWS AppSync Resolver and data sources. This post shows an example of how to connect Amplify DataStore with existing SQL data sources, adding offline and synchronization features to the application.
Once the creation of the cloud resources are finished, the local configuration (aws-exports.js or amplifyconfiguration.json) will be generated (or updated, if it already exists) with the settings and information about the GraphQL endpoint in AWS AppSync. With the client application started, DataStore identifies the API information to synchronize with the AWS AppSync endpoint, and it will start an instance of its Sync Engine. The Sync Engine is responsible for interfacing with the Storage Engine to identify updates from the model repository.
The Sync Engine and the Storage Engine use the Observer pattern, defining a dependency between objects so that when one object changes its state, the observers are notified of this change and updated accordingly. In this scenario, both the Sync Engine and the DataStore API subscribe to the publication stream. The Sync Engine publishes events whenever updates happen in it (such as data being added, updated, or deleted).
The following figure shows this interaction.
This mechanism solves the Data Synchronization challenge and it’s how developers using DataStore API can identify data changes that happened on the cloud (generated by other users or applications that are manipulating the same data in the back-end). This is also how the client application converts the information from the Model Repository into GraphQL statements at runtime to submit queries or mutations to the cloud.
For further details, check the Sync data to cloud section in the Amplify documentation.
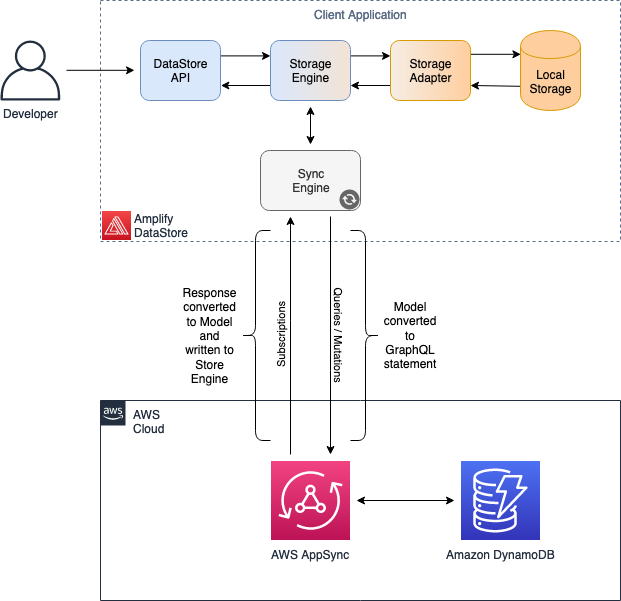
Figure 2: Cloud synchronization process
In the data synchronization process, all of the items are versioned and multiple versions of the same item can exist on the client and the server. With the conflict resolution configuration enabled, when concurrent updates are sent from multiple clients using the same version for a specific item, a strategy for conflict detection and resolution is applied.
The conflict detection determines if the mutation is in conflict with the actual item written in the data source, and it’s enabled when the Amplify CLI is used to create the resources in the cloud.
The conflict resolution represents the action taken when a conflict is detected. There are three conflict resolution strategies that you can choose:
- Automerge: this is the default strategy and provides an easy conflict resolution method without writing client-side logic to manually merge conflicts.
- Optimistic Concurrency: the latest item written to the database will be used with a version check against the incoming record.
- Custom code via Lambda Functions: lets you apply any custom business logic when merging or rejecting updates.
For more details on how Amplify DataStore manages the conflict resolution, check the documentation.
Conclusion
This post revisited the concept of Offline first applications and some of the main challenges, such as delta sync, conflict detection, and resolution when developing following this approach. I also presented how Amplify DataStore can solve these challenges when data transitions from offline to online and vice-versa. In the second part of this post, I show an example of how to develop a simple application following the Offline first approach and using Amplify DataStore and Flutter.
Amplify DataStore provides a programming model that allows application developers to focus on features that add business value rather than undifferentiated code to handle caching, reconnection, data synchronization, and conflict resolution. With Amplify DataStore, you can start with the Offline first approach to design your model and develop the operations directly in your local storage before connecting it to cloud services, thereby saving in costs and resources.
I invite you to dive deep into the Amplify Datastore Use Cases and Implementation, as well as the Amplify DataStore documentation, and learn more about how it works and see other use case examples.
About the author: