AWS Cloud Operations Blog
Software patching with AWS Systems Manager
Cloud computing adoption has been rapidly increasing with enterprises around the globe, opting for various migration patterns during their cloud journey. Taking monolithic legacy applications as-is and moving them to the cloud, is an approach also known as “lift-and-shift,” and is one of the main drivers for cloud migration. As customers become more knowledgeable about migration patterns, the lift-and-shift method should be optimized to take full advantage of cloud native tools.
If proper deployment processes and release planning are not in place, code migrations can be challenging and expensive. Most organizations are adopting agile methods for application development and are actively pursuing automation and DevOps practices. CI/CD (continuous integration and continuous delivery) has become a key component of the software development life-cycle and is the backbone of DevOps.
The need for application patching and deployments in monolith and legacy environments are still a reality for multiple enterprises. Releasing new features into production is challenging due to application complexity, external dependencies, and the coordination of multiple teams in a chain of procedures. This blog post aims to help application and operations teams set up a software patch management pipeline using various AWS services.
Overview
Applications require continuous updates to address security vulnerabilities and fix software bugs. A poorly designed patching strategy can lead to SLA compliance and business continuity policies failures. Additionally, software updates can introduce bugs, performance issues, and deficiencies.
Patch management life-cycle is integral to an organization’s service management strategy, as it provides prescriptive guidance around how patches are applied and when. One way to prevent production outages is to test patches regularly, in lower environments, and only promote approved patches to the higher stack. This post walks you through setting up a software patch management pipeline, following the described methodology.
The solution described in this blog was created based on previous field experience from customers that are leveraging Terraform as Infrastructure as Code. It introduces a different perspective into Software patching and demonstrates how DevOps processes and methodology can be impactful to an organization.
Prerequisites
You need an AWS account with permissions to create new resources. For more information, see How do I create and activate a new Amazon Web Services account?
This blog post assumes you already have some familiarity with Terraform. We recommend that you review the HashiCorp documentation for getting started to understand the basics of the platform.
A sample version of the code used for this Blog Post is available on Github for you to learn, modify and apply your own customizations.
You can follow the Readme file available in the git repository for detailed instructions on how to deploy and use the sample code on your AWS environment.
What you build
The following AWS services are used to build this solution:
AWS CodePipeline is the solution orchestrator, it is continuously listening for code changes and once that occurs it creates the artifacts and make it available for the next stages of the pipeline.
AWS CodeBuild is a continuous integration service that has the information about which systems and environments the patch needs to be applied. It also connects with System Manager to execute remote scripts on the desired instances.
AWS Systems Manager enables the automation of operational tasks, it receives from Codebuild the list of instances to be patched and remotely executes the commands in all target instances.
In addition, an S3 Bucket, IAM Roles and an SNS topic to notify the status of the pipeline are also created as part of the solution.
Architecture
The patch deployment is a multi-step process and that requires interaction with several AWS services.
The following diagram explains the high level architecture where Terraform provisions a Multi Stage Pipeline that can be used to easily managed application and operating systems patches in a fleet of EC2 Instances.
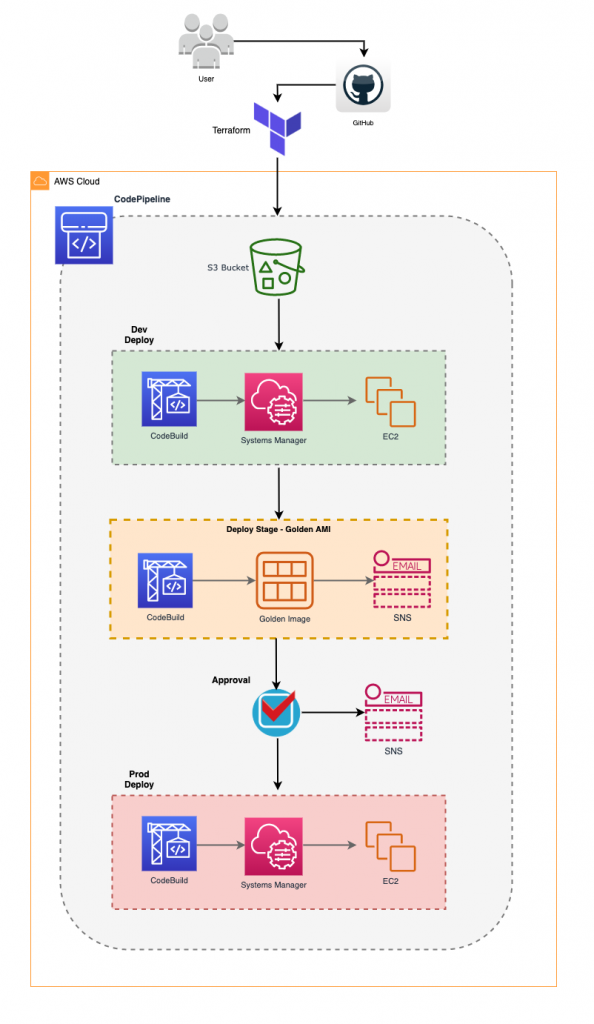
After the CodePipeline is provisioned it is ready to receive user inputs. Initially the user uploads the patch file to a patch source repository. The solution uses an S3 bucket but it accepts other source control such as AWS CodeCommit or Github.
AWS CodePipeline polls the S3 bucket periodically and as soon as a patch is uploaded, the Pipeline is triggered. Firstly, it deploys to the Development environment and then if the deployment is successful, it proceeds to the Golden AMI creation.
Before the production deployment, there is manual approval stage that sends an email notification so the changes in the pipeline can be reviewed and approved before going to production.
The next diagram is snapshot of what happens during the Golden AMI and Deployment Stage.

After the user uploaded a patch that triggered the Pipeline, AWS CodeBuild runs a code using the Python SDK that identifies the targets based on tag parameters passed through environment variables of AWS CodeBuild.
Once targets are identified using tags, a command document is sent to AWS Systems Manager to run remote commands on the target instances. The patch commands run sequentially and waits for a result before processing next command.
Once the patch is deployed and all commands are executed with success, AWS CodeBuild issues an API call to create an image from a running EC2 instance and tags it as a Golden image.
After the image is created, AWS Systems manager parameter store is updated with the new AMI ID for future reference.
A notification is sent via SNS topic once a new Golden Image becomes available and it can be immediately used in new builds using Terraform.
Conclusion
This solution provides a pathway to implement DevOps practices on monolith and legacy applications. There are several benefits observed by using this solution:
- Rapid and Continuous Delivery: the solution presented in this blog post can enable organizations to rapidly improve their patching strategy. When we compare it with previous approaches, the effective usage of this solution has in average reduced customers deployments from days to hours.
- Infrastructure as a Code: this architecture is built using a reusable template and follows standard software delivery life-cycle process. IaaC such as CloudFormation and Terraform allow resources to be quickly provisioned and replicated in different locations while having a single source of truth for the infrastructure code.
- Disaster Recovery: it provides an effective disaster recovery mechanism by copying the golden images to a different AWS region. In case of outages it takes minimal time to bring up the DR site.
To learn more about the possibilities of AWS Systems Manager, check the product documentation.
About the authors

Franco Bontorin is a senior consultant in the US southeast region. He is a DevOps and microservices enthusiast and has assisted multiple customers to migrate and create cutting edge AWS solutions.

Prajjaval Gupta is a DevOps consultant and has over 5 years of experience working in the DevOps field. Prajjaval has been assisting Enterprise customers to adopt DevOps culture during their migration to the AWS Cloud.