AWS Open Source Blog
How Falco uses Prow on AWS for open source testing
This post was co-written with Leo Di Donato, an open source software engineer at Sysdig in the Office of the CTO.
Kubernetes has seen massive growth in the past few years. However, with all growth comes growing pains, and CI/CD has brought a few interesting problems to the space, especially for the open source community. Many traditional CI/CD solutions worked on top of Kubernetes but lacked the tie-in to GitHub. What the community needed was a solution with the following attributes:
- Kubernetes-native
- Comprehensive GitHub automation
- Concurrency at scale
Kubernetes ended up solving this problem for themselves because other tools weren’t getting the job done. So, the Kubernetes Testing Special Interest Group (sig-testing) created their own tools and services, including Prow and other tools located at Kubernetes test-infra. Prow is not only Kubernetes-native with the ability to gather kubernetes-specific metadata, but it is also massively scalable, performing roughly 10,000 jobs a day for Kubernetes-related repositories.
What is Prow?
The Testing SIG defines Prow as:
“A Kubernetes based CI/CD system. Jobs can be triggered by various types of events and report their status to many different services. In addition to job execution, Prow provides GitHub automation in the form of policy enforcement, chat-ops via /foo style commands, and automatic PR merging.”
That description just touches the surface of how powerful Prow really is. It is a container-based microservice architecture that consists of several single-purpose components—many integrating with one another, whereas others are more or less standalone. Prow is a CI/CD tool that starts, runs, and finishes all within GitHub code commits.
What is Falco?
The Falco Project, originally created by Sysdig, is an incubating Cloud Native Computing Foundation (CNCF), open source, cloud native runtime security tool. Falco makes it easy to consume kernel events and enrich those events with information from Kubernetes and the rest of the cloud native stack. Falco has a rich set of security rules specifically built for Kubernetes, Linux, and cloud native. If a rule is violated in a system, Falco will send an alert notifying the user of the violation and its severity.
Getting started
Falco is the first open source Prow project running exclusively on AWS infrastructure. Prow runs on Amazon Elastic Kubernetes Service (Amazon EKS) because it’s a fully managed Kubernetes experience that allows it to be compatible with APIs used by the Prow system.
In this tutorial, we will cover how Falco set up Prow on Amazon EKS clusters, followed by configuration to utilize the Prow Hook component to invoke GitHub webhooks (events) and Spyglass to utilize testing inspection of pods and jobs.
The following figure is an architecture diagram of Prow on Amazon EKS. We’ll also provide a quick breakdown of the main components of Prow and what each microservice is responsible for.

Main components of Prow
- ghProxy is a reverse proxy HTTP cache optimized for use with the GitHub API. It is essentially a reverse proxy wrapper around ghCache with Prometheus instrumentation to monitor disk usage. ghProxy is designed to reduce API token usage by allowing many components to share a single ghCache.
- Hook is a stateless server that listens for GitHub webhooks and dispatches them to the appropriate plugins. Hook’s plugins are used to trigger jobs, implement “slash” commands, post to Slack, and more. See the
prow/pluginsdirectory for more information. - Deck presents a nice view of recent jobs, command and plugin help information, current status and history of merge automation, and a dashboard for pull request (PR) authors.
- Sinker cleans up old jobs and pods.
- Prow Controller Manager, formally known as Plank, is the controller that manages the job execution and lifecycle for jobs that run in Kubernetes pods.
- Pod utilities are small, focused Go programs used by
plankto decorate user-providedPodSpecsto perform tasks such as cloning source code, preparing the test environment, and uploading job metadata, logs, and artifacts. In practice, this is done by addingInitContainersand sidecarContainersto the prowjob specs. - Spyglass is a pluggable artifact viewer framework for Prow. It collects artifacts (usually files in a storage bucket, such as Amazon Simple Storage Service [Amazon S3]) from various sources and distributes them to deck, which is responsible for consuming them and rendering a view.
- Horologium triggers periodic jobs when necessary.
- Crier reports on status changes of prowjobs. Crier can update sources such as Github and Slack on status changes of job executions.
- Status-reconciler ensures that changes to blocking presubmits that are in Prow configuration while PRs are in flight do not cause those PRs to get stuck.
- Tide is a component that manages a pool of GitHub PRs that match a given set of criteria. It will automatically retest PRs that meet given criteria and automatically merge them when they have up-to-date passing test results.
How Falco installs Prow on AWS
This guide assumes we have an Amazon EKS cluster already launched and ready. Check out the official getting started guide for details on how to launch a cluster.
Set up GitHub repos
In the first step of this process, we will set up and configure our GitHub repositories. Falco uses two GitHub accounts for Prow setup. The Falco Security organization belongs to Account 1, and Account 2 is the bot that will have repository access and will interface with Hook to manage all GitHub automation.
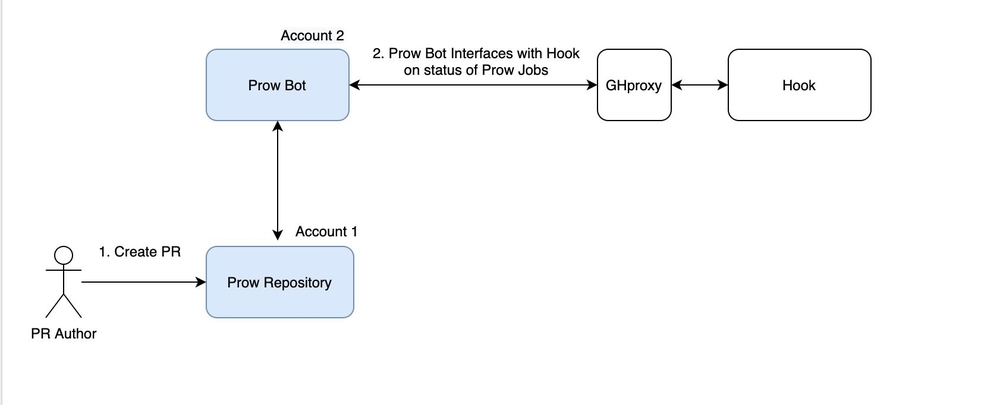
The Falco bot for Account 2 is called poiana, which is the Italian word for hawk as most of the core maintainers are from Italy.
Give bot access to main organization/repository
In GitHub, navigate to Repository Settings, Manage Access, Invite a collaborator and add the name of our bot account as a collaborator.
Then, create a personal access token on the GitHub main account and save it for later. Add the following scopes:
repoadmin:orgadmin:repo_hookadmin:org_hook
Save the token to a local file oauth-token and create the Kubernetes secret for the token.
Set up AWS ALB Ingress controller
For the Prow setup, we will need to publicly expose hook and deck. We will create an application load balancer (ALB), which will route traffic to the appropriate Kubernetes service.
Here, you can follow the guide for installing the AWS Load Balancer Controller, which includes setting up proper identity and access management (IAM) and cert manager.
Install the ingress and configure the webhook setup in GitHub
In this ingress, we create an internet-facing load balancer and listen on ports 80 and 8888. We direct all requests on port 80 to deck and those on 8888 to hook. This will be the dedicated ingress to handle external requests to the cluster from permitted external services such as GitHub.
Now we find our load balancer URL:
We need to create a token for GitHub that will be used for validating webhooks. We use OpenSSL to create that token.
Now we can configure a webhook in GitHub by going to our repo Settings, WebHooks and using this load balancer URL. This is on our bot account poiana, because that account will be interfacing with Prow.
The payload URL is our http://LB_URL:8888:hook.
The webhook needs to be in application/json format, and we set the payload URL to point to Hook.
The secret here is the hmac-token, 8c98db68f22e3ec089114fea110e9d95d2019c5d, which we just added to Kubernetes.
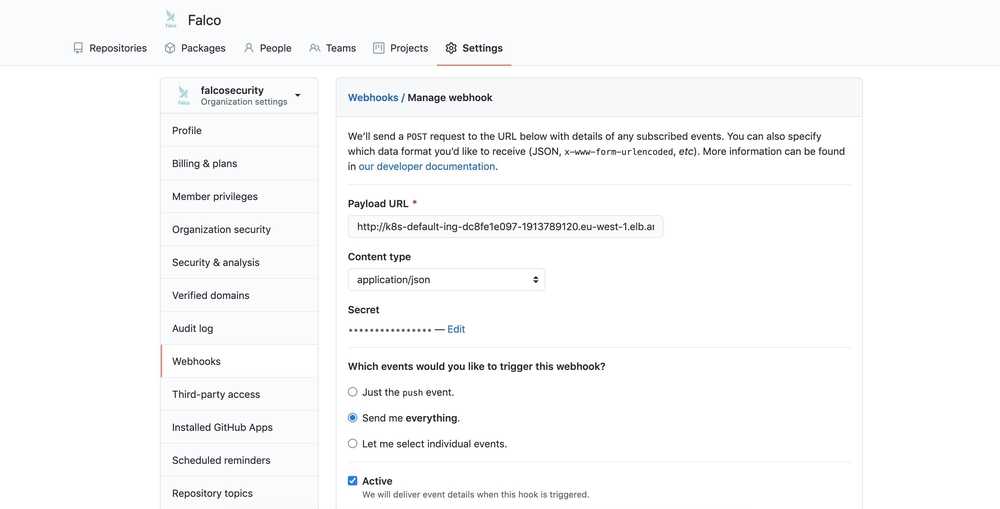
If we configured everything correctly, at this point we should see webhooks coming back successfully:

Create an S3 bucket for Prow data
Prow uses a storage bucket to store information, such as:
- (SpyGlass) build logs and pod data
- (Tide) status
- (Status reconiler) status
aws s3 mb s3://falco-prow-logs
This is what the bucket’s content will look like after it’s been running for a bit. The storage so far has been about 100 jobs = 10MB of data if storage costs are a concern. This value can vary with the length of job logs.

Create an AWS IAM user and S3-credentials secret
We created the S3 bucket for our Prow storage, and now we need to create an AWS Identity and Access Management (IAM) user with S3 permissions for our cluster. Because of the way the Prow code is written, the pod utilities sidecar pod is responsible for uploading build logs and podinfo to S3 before, during, and after the execution, and requires IAM access key format.
Once we have created our Prow IAM user, we create the file s3-secret.yaml and kubectl apply -f s3-secret.yaml:
Install config and plugins configmaps
There are different config files that we supply to components that don’t include AWS, GitHub, or oAuth access.
The first is the config.yaml used to declare configuration for all of our components. This is the configuration of all the Prow microservices and the job configurations.
The second is the plugins.yaml used to declare which plugins to use in our GitHub and Deck setup. This controls all the GitHub label, branch protection, and triggers automation as well.
Here is a basic example of our config.yaml:
And our plugins.yaml:
If installing this on your own setup, change:
prow.falco.orgto your Deck URLs3://falco-prow-logsto your S3 bucketfalco/test-infrato your organization/repository.- username/repository also works if not part of an organization
Install ghProxy with Amazon EBS storage retention
ghProxy is a proxy and cache for GitHub, which helps us handle requests and retries that go above the GitHub API rate limit and will retain data in Amazon Elastic Block Store (Amazon EBS) for long-term retention of calls and data.
First, we install the Amazon EBS CSI driver into our cluster, then the ghProxy and PersistentVolumeClaim (PVC) for our cluster:
We can check that it’s up and running and that the PVC worked correctly by running kubectl get PersistentVolume:
![]()
Install Prow components on the cluster
The next step is deploying the rest of the microservices for Prow on our Amazon EKS cluster. This cluster is going be where we run the base testing infrastructure and will be the client-facing cluster in the test setup, as Falco security is a public project.
To get our cluster up and running, we need to launch the following microservices in addition to all the pieces we’ve launched so far. Take a look at the Falco microservices on GitHub for a good example of how they are configured and used. You can also check out the recommended starting AWS deployment on K8s, which is a more minimal setup.
The main microservices launched are:
Exploring the Deck UI
Let’s take a look at Deck and explore all the capabilities it offers to users. Grab the external IP address once it’s launched, then navigate to the external IP and see the Deck webpage. Our external IP address will be an ELB classic URL because it’s using the Kubernetes LoadBalancer type.
kubectl get svc deck

Head to the Deck UI for the cluster. This is where you can see jobs and information about our jobs. You can check out Falco’s Prow setup on the Falco website.
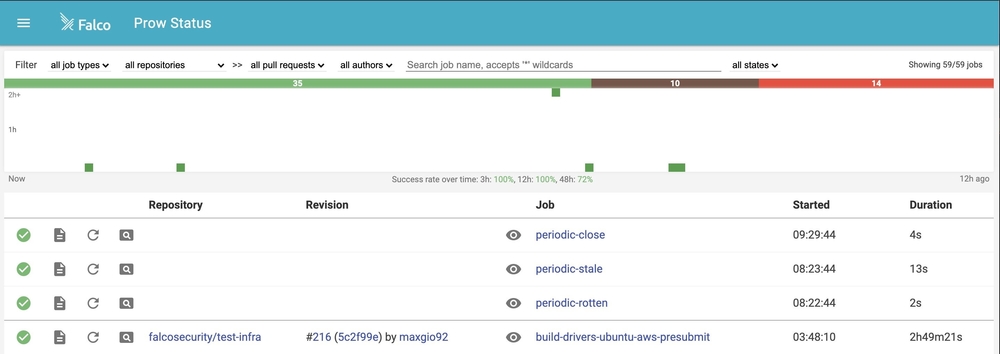
From here, we can see jobs from pull requests and from periodic jobs. We can also navigate to Spyglass by clicking on the eye icon. We set up the Spyglass service to see more information about the individual jobs.
![]()
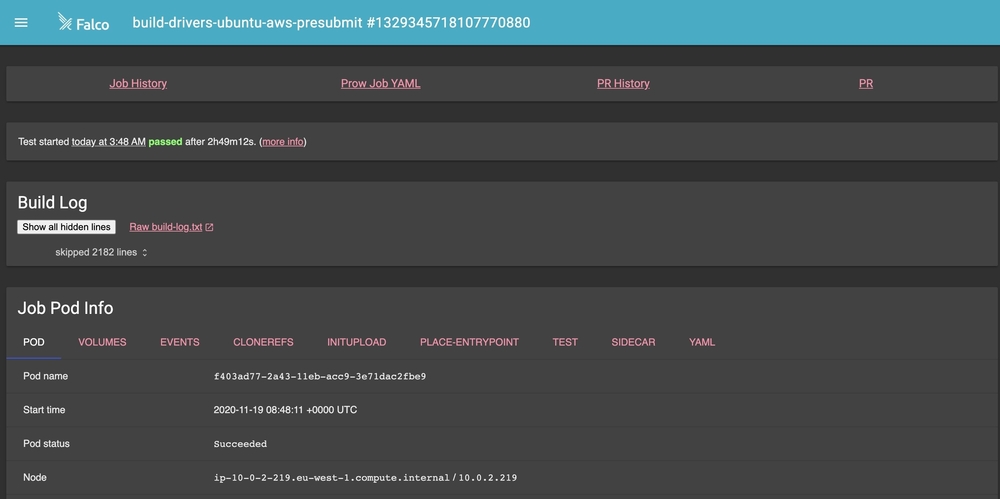
This will give us information such as logs, Kubernetes events, pod information, job history, and deep links back to our original pull request in GitHub.
Note: Spyglass is an extremely powerful but also dangerous service. Be careful when turning this on. Showing pod info to the world can be dangerous if using cleartext secrets or secrets exposed via logs.
Adding our first job
We are going to add our first job to config.yaml and update the configmap. This will be a simple job that will just exit with an error. This job will fail and show red in our Deck console. The failure allows us to use the GitHub PR retesting commands to fix our error with a new commit and to use the self-service retest.
Now we can update our configmap to add the new job, which will get picked up by Prow.
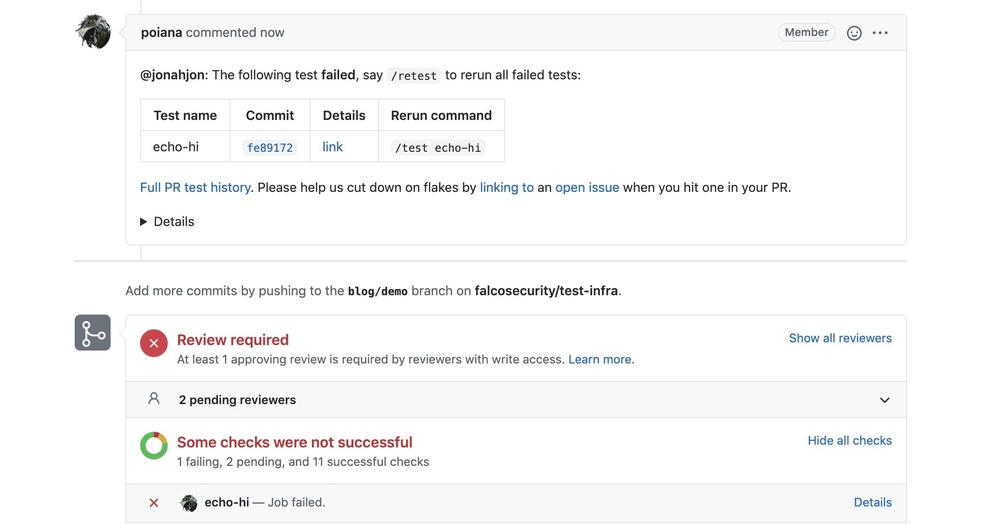
We get another code reviewer to add the /lgtm label to our PR, which will allow it to kick off the testing for Prow.

The PR has been approved and will kick off the prowjob, which we can see in the GitHub check on the pull request. Here we see that our job failed, which means the job emitted an exit code of 0. We can now fix the issue in the same pull request.
This time, we changed our prowjob to run:
echo "Prow Rocks"
This returns an exit code of 1 and moves our failing test to a success.
Next, we can use our retest command to retest the job with our new update.
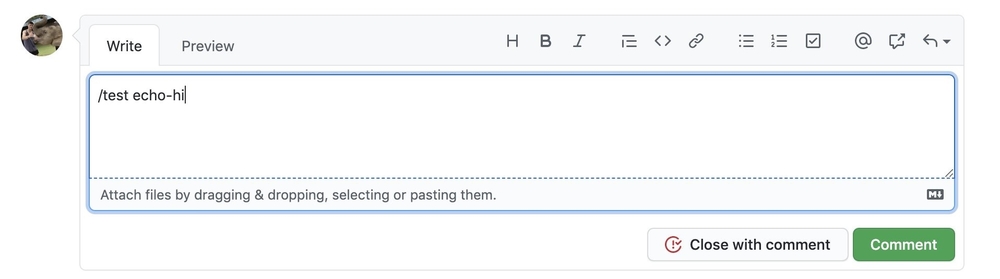
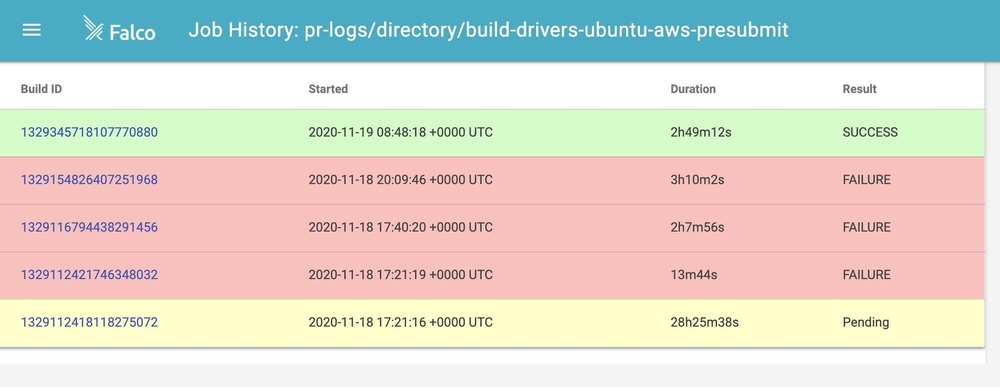
After a minute here, our new echo-hi checks on prowjob in GitHub. This one looks like it passed, so we can go inspect the logs in Deck. We can also look at our PR history and see which jobs failed on each commit that was pushed.
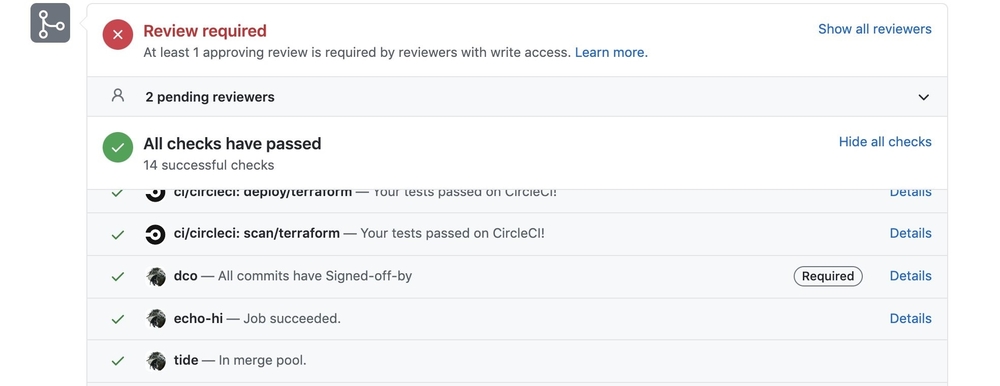

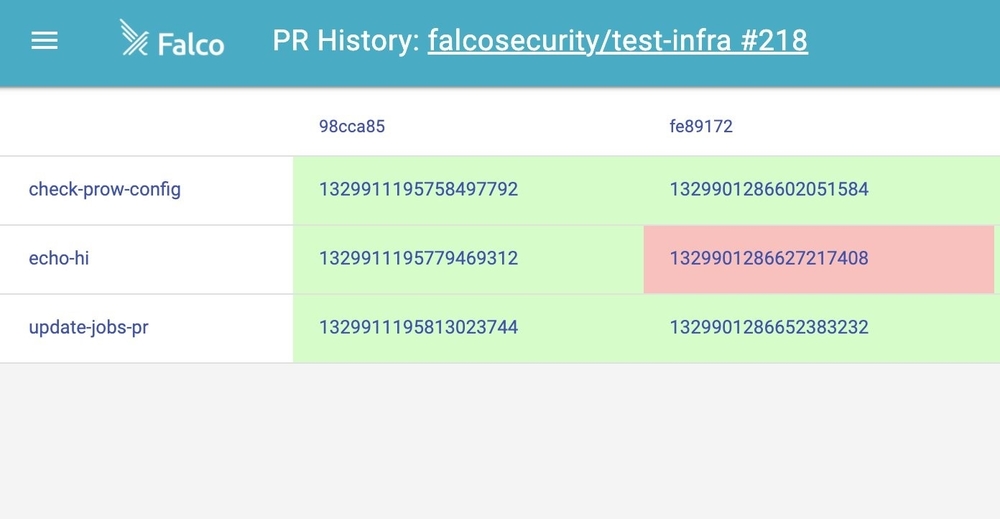
These examples show the power of Prow and the ability to test. We get the ability to use /foo style chat commands in our pull requests to rerun tests. This functionality gives developers the ability to write, debug, and fix tests all in a self-service manner, which is important for an open source project like Falco.
Once our tests have run, we can use Deck and Spyglass to check build logs, PR job history, and other job execution data to give us quick feedback on test results, which helps maintain that quick feedback loop for contributors.
Conclusions
Today, the Falco project spans more than 35 repos across the org. The project is in the process of securely moving over tests from across all the repos to Prow. Feel free to contribute at GitHub and check out the talk about advanced Prow usage given by Falco maintainer Leonardo Di Donato at KubeCon + CloudNativeCon: Going Beyond CI/CD with Prow.
Happy Prowing!

Leonardo Di Donato
Leo is an open source software engineer at Sysdig in the Office of the CTO, where he’s in charge of the open source methodologies and projects. His main duty is to make Falco, a cloud native tool for runtime security incubated by the CNCF. Leo is also involved in the Linux Foundation’s eBPF project (IO Visor) as a maintainer of the kubectl-trace project. As a long-standing OSS lover, he’s also the author of go-syslog, a blazingly fast Go parser for syslog messages and transports, and of kubectl-dig, a tool about deep visibility into Kubernetes directly from the kubectl, etc. Follow him on Twitter @leodido
The content and opinions in this post are those of the third-party author and AWS is not responsible for the content or accuracy of this post.