AWS Open Source Blog
How to use InfluxDB and Grafana to visualize ML output with AWS IoT Greengrass
Machine learning (ML) algorithms are widely used for computer vision (CV) applications, such as image classification, object detection, and semantic segmentation. With the latest development of the Industrial Internet of Things (IIoT), ML algorithms can be directly implemented at the edge device to process image data and perform anomaly detection, such as for product quality assurance tasks at shop floors with low latency. The recently released AWS IoT Greengrass version 2 (Greengrass v2) helps developers deploy CV ML applications at the edge with the necessary customer data pipeline components, including data ingestion and data preprocessing logics.
In this blog post, we’ll show an end-to-end workflow for using open source tools with AWS IoT Greengrass version 2 to visualize ML inference results in near real-time on an edge device.
Introduction
In many anomaly detection and object classification applications, users want to visualize the ML inference output at a local edge machine with a real-time dashboard tool so they can review, approve, or intervene in the ML inference outcomes. With a near real-time business intelligence (BI) tool at the edge, the operational technology team can consume the ML outputs in a timely manner and make appropriate business decisions.
In this article, we present a workflow showing how to implement a CV ML application with visualization at the edge with two open source tools: InfluxDB and Grafana. For demonstration purposes, this setup uses a previously trained Resnet-18 classification model published on PyTorch to classify objects of 1000 categories. This pretrained model is further compiled with Amazon SageMaker Neo and is deployed as an edge inference component with Greengrass.
A second component is developed to visualize ML inference results at the edge using InfluxDB and Grafana. These open source tools are able to achieve high-speed ingestion and visualization of time-stamped image data in near real time.
The data transfer and communication between these two customer components is accomplished via interprocess communication (IPC) with AWS IoT Greengrass v2. In this setup, the CV ML component first publishes the inferencing result to the Greengrass IPC broker. A subscriber is listening on the same topic to which the ML inferencing script publishes, and the received inference result is then written to InfluxDB, and finally displayed on the predictive dashboard with image plugin by Grafana.
The following walkthrough contains detailed steps to develop this image visualization workflow with open source tools at the edge. No specialized ML experience is needed to follow this example and build the described workflow.
| Time to read | 20 minutes |
| Time to complete | 120 minutes |
| Cost to complete (estimated) | less than 1 dollar (at publication time) |
| Learning level | Advanced (300) |
| Services used | Amazon EC2 instance, AWS IoT Greengrass v2, Amazon SageMaker Neo, Amazon SageMaker notebook, InfluxDB, and Grafana |
Solution overview
The following image shows the solution architecture for this edge workflow. Two user-defined components, ML inference and IPC message subscriber with data entry to InfluxDB, are deployed with AWS IoT Greengrass v2 at the edge. Once the time-stamped ML inference data is written to InfluxDB, a table type Grafana dashboard is built to filter and display ML inference results.
In this example, we used an Ubuntu 18.04 LTS EC2 instance with the Greengrass v2 runtime to simulate an edge device with the AWS IoT platform.
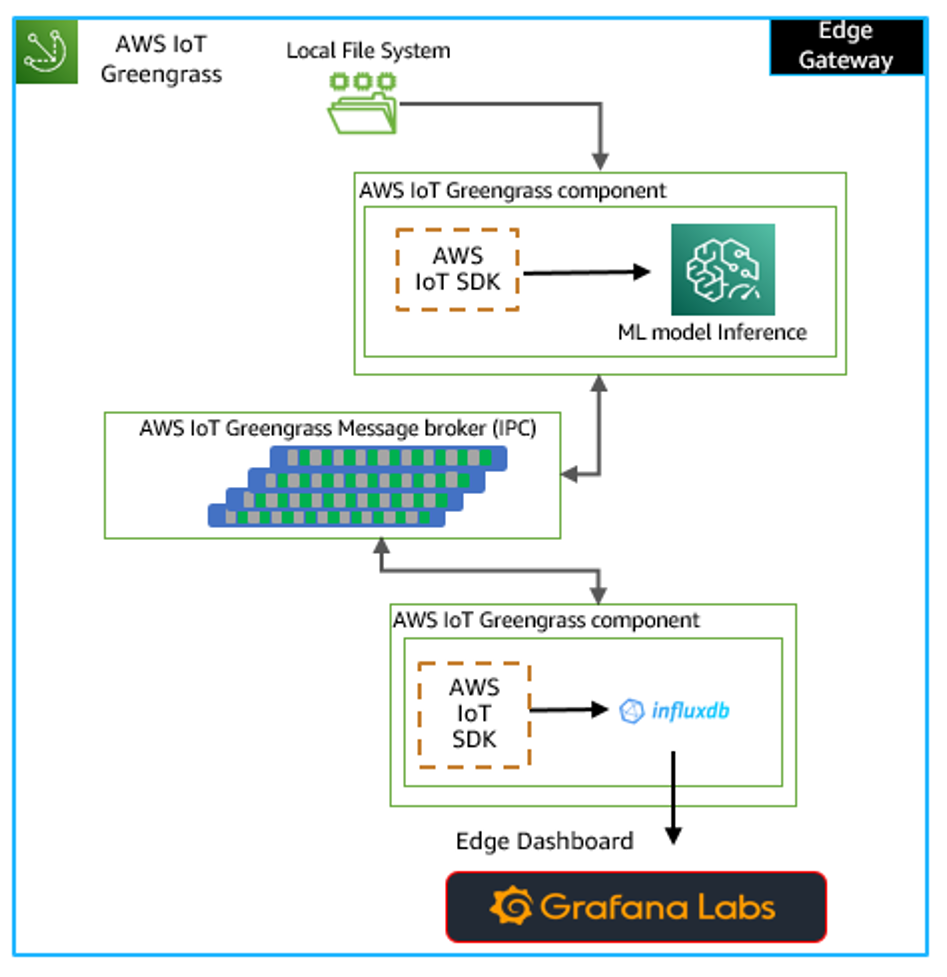
Figure 1: Solution architecture for this edge workflow.
Walkthrough
In the following sections, we will cover four steps:
- Set up InfluxDB, Grafana, and Greengrass v2 on Amazon Elastic Compute Cloud (Amazon EC2) instance.
- Create and deploy the ML component.
- Create the subscriber and ingest data to InfluxDB component.
- Create a Grafana dashboard to visualize ML inference results.
The source code for each component is hosted in a GitHub repository.
Prerequisites
The following prerequisites are necessary to complete the setup as described:
- An AWS account. If you don’t have an AWS account, follow the instructions to create one, unless you have been provided Event Engine details.
- A user role with administrator access. The service access associated with this role can be constrained further when the workflow goes to production.
- Recent modern browser (for example, latest Firefox or Chrome).
- No specialized knowledge is required to build this solution, but basic Linux and Python knowledge will help.
Step 1. Set up InfluxDB, Grafana, and Greengrass on Amazon EC2 instance
EC2 instance preparation work
To start, you must set up an Amazon EC2 instance of type c5.xlarge with Ubuntu 18.04 base image in the AWS account with the following user data:
After the EC2 instance’s status changes to running, follow the instructions to set up AWS Systems Manager Session Manager Access role to access this EC2 instance without SSH.
Finally, you must install the AWS Command Line Interface (CLI) v2 on the Amazon EC2 instance:
Connect with the EC2 instance via AWS Systems Manager Session Manager (SSM)
To connect with the Amazon EC2 instance via the AWS Systems Manager Session Manager, complete the following steps:
- Open the Amazon EC2 console.
- In the navigation pane, choose Instances (running).
- Select the Ubuntu instance you set up previously and choose Connect.
- For Connection method, select Session Manager.
- Choose Connect.
If the Connect option under Session Manager is not available, you’ll need to refer to the tutorial and update the policies to allow you to start sessions from the Amazon EC2 console.
Install Greengrass on EC2 instance
Next, copy the greengrass_install.sh script provided by the GitHub repo to the home directory on your EC2 instance.
- Modify the script with your own AWS Region.
- Run the following commands:
Greengrass should show active status similar to the following example:

Figure 2: Greengrass should show active status similar to this output.
You also can check the Greengrass Core device status from the AWS IoT Greengrass console in your specified AWS Region as shown in the following image:

Figure 3: Greengrass Core device status from the AWS IoT Greengrass console in your specified AWS Region.
Set up InfluxDB credential and bucket
To start, install InfluxDB 2.0 and Grafana v8.0.4 on this Amazon EC2 instance by following the GitHub instructions.
Before writing data to InfluxDB, you must configure a user credential and a bucket. InfluxDB v2.0 stores time series data in the bucket for a given retention period, and it will drop all points with timestamps older than the bucket’s retention period. Because of limited disk space of the edge device, we recommend you do not use the infinite retention period.
InfluxDB also needs user authentication for single unified access control. You can configure InfluxDB with InfluxDB CLI with this command in SSM as:
Next, configure InfluxDB with the following prompted hints:
- Enter a primary user name (for example, influxblog).
- Enter a password for your user.
- Confirm your password by entering it again.
- Enter a name for your primary organization (for example, ggv2demo).
- Enter a name for your primary bucket (for example, mloutput).
- Enter a retention period for your primary bucket. For this value, you should enter the number of hours the time series data should be kept at the edge device (for example, 24).
- Confirm the details for your primary user, organization.
- Before starting, note the token string for InfluxDB authentication with the following command:
The token string will be shown under
Tokenas follows:
Figure 4: The token string will be shown under Token, as shown in this output.

After the initial setup is finished, the user profile and database configuration will be used in step 3 for the Greengrass subscriber component to write data points to InfluxDB.
Finally, you must set up a connection configuration profile and set it to active to use the Influx CLI to query data securely:
Set up Grafana dashboard with port forwarding for Session Manager
In a production environment, it is recommended that the operational technology team directly access the Grafana dashboard at the edge with the enhanced authentication method. With the enhanced authentication mechanism, such as OAuth with Amazon Cognito, users can easily access the dashboard with a URL or IP address of the edge device.
Because of the limited length of this blog post, only the port forwarding function for AWS SSM is configured here to prevent anonymous access to the Grafana application at the edge. As noted in New – Port Forwarding Using AWS System Manager Session Manager, port forwarding allows you to create tunnels securely between your instances deployed in private subnets, without the need to start the SSH service on the server, to open the SSH port in the security group, or the need to use a bastion host.
To start, check the Grafana application status in SSM with the following command, then do the following steps:
- Configure the Grafana server to start at boot:
- Follow the documentation to configure AWS CLI with AWS account user profile credential on a laptop. Ensure that the AWS CLI version is 1.16.220 or more recent.
- Install the Session Manager plugin for AWS CLI on your laptop.
- Start a port forwarding session with SSM for the Amazon EC2 instance on your laptop:
The successful connection will produce the following response:
- Open a web browser on your laptop and log in to Grafana with the following address:
The following Grafana login page should be shown:

Figure 5: Grafana login page.
- Follow the prompts to set up new password for Grafana and note the password information for Grafana dashboard access next time.
Step 2: Create and deploy the ML component
In this example, the pretrained PyTorch Resnet-18 is compiled with Amazon SageMaker Neo for inference. SageMaker Neo automatically optimizes machine learning models for inference on cloud instances and edge devices to run faster with no loss in accuracy.
To do this, start with a machine learning model already built with DarkNet, Keras, MXNet, PyTorch, TensorFlow, TensorFlow-Lite, ONNX, or XGBoost and trained in Amazon SageMaker or anywhere else. Then, choose your target hardware platform, which can be a SageMaker hosting instance or an edge device based on processors from Ambarella, Apple, Arm, Intel, MediaTek, Nvidia, NXP, Qualcomm, RockChip, Texas Instruments, or Xilinx.
With a single click, SageMaker Neo optimizes the trained model and compiles it into an executable. The compiler uses an ML model to apply the performance optimizations that extract the best available performance for your model on the cloud instance or edge device. We use SageMaker Neo with AWS IoT Greengrass for the following reasons:
- Installing PyTorch framework needed on edge device is no longer required.
- Amazon SageMaker Neo uses TensorRT + TVM technology to optimize performance. (We are able to achieve a 3x performance increase by switching from the PyTorch model to a SageMaker Neo compiled model.)
Download sample model and compile with Amazon SageMaker Neo
In this step, we will launch a lightweight SageMaker notebook instance to go through the procedure of compiling a PyTorch Resnet-18 model with SageMaker Neo service.
- Launch a small SageMaker notebook instance (t2 or t3).
- Create a new Jupyter notebook with the
conda_pytorch_latest_p36kernel. - Upload the notebook we have prepared in GitHub, then change the SageMaker client region parameter to the same region as the EC2 instance:
- Run all the steps in order to generate the SageMaker Neo compiled model.
- Check the Amazon Simple Storage Service (Amazon S3) bucket and make sure that the following artifacts exist in the Amazon S3 path you defined in your notebook. In our demo, we have stored them in the following:

Figure 6: Amazon S3 bucket showing artifacts in the S3 path defined in the notebook.
Prepare edge inferencing Greengrass component
Components are building blocks that allow easy creation of complex workflows, such as ML inference, local processing, messaging, and data management. Components running on your core device can use the AWS IoT Greengrass Core IPC library in the AWS IoT Device SDK to communicate with other Greengrass components and processes.
The following steps show how to deploy the previous packaged ML model as an edge inference component on Greengrass v2.
- Change directory to
modules/edge-inference/aws-gg-deployin the directory where the Git repository was cloned to the EC2 instance. - Modify the deployment script
deploy-edge.shby replacing the following placeholders with your customized values in the_setEnv()section:- YOUR_AWS_ACCOUNT_NUMBER
- YOUR_AWS_REGION
- S3_BUCKET for model artifacts
- COMPILATION_NAME (this is obtained as the first folder of the model artifact in S3, following the pattern as
TorchVision-ResNet18-Neo-YYYY-MM-DD-hh-mm-ss-xxx.
Then do Ctrl-X and select Y to save the modified
deploy.shfile with the same name. - Run the following script to deploy this component:
This Bash script takes approximately 10 seconds to finish. When it finishes, confirm that you have the component created in your AWS IoT Greengrass v2 console as shown in the following image:

Step 3: Create the subscriber and data entry to InfluxDB component
Prepare InfluxDB subscriber Greengrass component
- Change directory to
modules/influxdb-subscriber/aws-gg-deployto the directory where the GIT repository was cloned to the Amazon EC2 instance. - Modify the
deploy-edge.shscript by replacing the following placeholders with your customized values:- YOUR_AWS_ACCOUNT_NUMBER
- YOUR_AWS_REGION
- S3_BUCKET for component artifacts (in this example, the S3 bucket used to store edge-inference component artifacts is also used in this influxdb-subscriber component)
Save the
deploy.shfile with Ctrl-X, then select Y to save the modified file with the same name before exit. - Modify the
recipe-file-template.yamlfile in the same directory by adding arguments of your InfluxDB configuration in theRuncommand in theManifestssection as shown in the following snippet:Replace the default
token_string,bucket_name,org, andmeasurement_namefor InfluxDB inmain.pywith your own InfluxDB parameters. Save this recipe template file with Ctrl-X, then select Y to save the modified recipe file with the same name. - Run the following script to deploy this component:
This Bash script takes approximately 10 seconds to finish.
- Once the component is running, you can check the outputs of the Python script checkpoints (for example,
***Write Points Finished ***) within the log to check the component status, as shown in the following figure:

For the base64 string containing the image output from ML inference component, a prefix is added to the data before writing it to InfluxDB as:
Step 4: Create a Grafana dashboard to visualize ML inference results
To configure the InfluxDB bucket as a Grafana data source, complete the following steps:
- Choose Data sources, as shown in the following image:

- Choose Add data source and select InfluxDB:

- Set up the InfluxDB data source with the documentation reference, as shown. In this example, we chose
Fluxas the query language, which has broader functionality with InfluxDB v2.0.

- Fill in the authentication information related with InfluxDB (user name, password, org, token, and bucket):

- Choose Save and Test. If successful, the result should show how many buckets were found under this org.



To build a table type dashboard for ML inference outputs, do the following:
- Move your cursor to the + icon on the side menu and choose Create dashboard. Then, select Add an empty panel.

- Under Query, enter the following Flux query:
- Next, change the visualization on the right panel to Table. The data points in InfluxDB should be shown in the panel as shown in the following figure:

In this dashboard, the statistics for each ML model inference are visualized, including InferenceStartTime, InferenceEndTime, InferenceTotalTime in ms, Probability, and Prediction. Thus, the operational technology team can review the ML inference results with this dashboard in real time. - In this step, you can configure the Picture field that contains base64 string data as an image display. To do so, select the Overrides tab, then choose the add field override tab. Select the Fields with name option from the drop-down menu and choose the Picture field. Next, click on Add override property tab, choose Cell display mode type as Image for column Picture field, as shown in the following figure.

- Once this information has been configured, select the Apply tab, and the original Base64 string data Picture column will display images of dogs, as shown in the following figure.

After 10 seconds, you can refresh the Grafana dashboard, and the latest inference results will be available to view. With these steps, a simple table type Grafana dashboard is built to show time-stamped ML inference output at the edge, so users can remotely examine image outputs and approve/reject outputs.




This Grafana dashboard also helps users monitor ML model performance of each inference by clearly showing model type, inference duration, probability of the inference, and final prediction result. This workflow can be further enhanced as human-in-the-loop workflow, so the inference results can be used as future training data to improve the ML model accuracy.
Clean up
You also must perform these clean up steps in the following areas.
AWS IoT
Open the AWS IoT Core console. Under AWS IoT, do the following:
- Under the Greengrass Core Device tab, select the DemoJetson core device and select Delete on top right.
- Under Manage, Thing Group, delete DemoJetsonGroup from the Thing Group.
- Delete things under Manage, Things: DemoJetson .
- Under Policies, delete GreengrassV2IoTThingPolicy and GreengrassTESCertificatePolicyGreengrassV2TokenExchangeRoleAlias2.
- Under Secure, Role Aliases delete GreengrassV2TokenExchangeRoleAlias.
Amazon S3
- Navigate to the S3 console and locate the component bucket you used previously.
- Empty the component bucket.
- Delete the component bucket.
Amazon EC2
- Navigate to the Amazon EC2 console.
- Stop the EC2 instance by selecting Stop Instance under Instance State.
- After the instance stops, select Terminate Instance under Instance State to shut down this EC2 instance.
Amazon SageMaker
- Navigate to the SageMaker notebook instance console.
- Stop the SageMaker notebook instance by selecting the instance you started for model preparation, and select Actions, Stop.
- After the instance has been stopped, select Terminate under Actions to shut down this EC2 instance.
IAM roles
- Navigate to the IAM console.
- Delete the IAM role created from Ubuntu EC2 instance.
- Delete the Amazon EC2 SSM access policy.
- Delete the IAM user created for Greengrass v2.
- Delete the policy that was attached to the Greengrass user.
- Delete the IAM role named in the format of AmazonSageMaker-ExecutionRole-xxxxxxxxxx.
These steps complete the deletion of the resource created for this example.
Conclusion
This article shows an end-to-end workflow for using open source tools (InfluxDB and Grafana) to visualize ML inference results in near real time on an edge device. The latest AWS IoT Greengrass v2 reduced complexity of this IoT edge workflow by providing an IPC library to allow communications between different edge modules, so open source tools can be integrated easily with other ML components in an edge workflow.
With InfluxDB’s time series database, image files can be written to it as time-stamped base64 string data, queried with the Flux tool, and visualized by Grafana in near real time. This workflow can significantly improve the user experience of IoT edge ML applications and help the operational technology team achieve remote monitoring of ML at the edge.
Call to action
This ML edge workflow can also be extended for different database and BI tool combinations (for example, InfluxDB and Prometheus, MySQL and Grafana, RedisTimeSeries, and Grafana, etc.). Users can also adapt the subscriber component and utilize different tools for their specific use cases.
In this article, we mainly focused on the improved modularity function of AWS IoT Greengrass v2; however, other features for Greengrass can benefit edge workflow development. For example, Amazon SageMaker Edge Manager is now integrated with Greengrass to simplify ML fleet deployments. For more details, please refer to this document.
In the future, other customer components, such as camera data ingestion, and image preprocessing and enhancement, also can be developed as individual modules and be integrated with this existing edge workflow to build more robust CV ML edge applications.