AWS Open Source Blog
What is Trapheus?
This article is a guest post from Namita Devadas and Rohit Kumar, Senior Software Engineers at Intuit.
Trapheus is an open source Python serverless utility for automated restoration of Relational Database Service (RDS) instances from snapshots into any development, staging, or production environments. It supports snapshot-based restoration for individual RDS instances (for example, Oracle, MySQL, MariaDB) in addition to Amazon Aurora cluster instances with read replica support. It focuses on a solution that is automated, self-reliant, scalable, cost effective, developed in a cloud-native manner, and reusable across several data stores. In this article, we provide a quick overview and step-by-step instructions to get started with Trapheus.
Managing snapshots
Many databases implement snapshots as a technique to provide a transactionally consistent, point-in-time backup of data. A database can be restored to a point in time with the snapshot, which typically serves a variety of use cases, including:
- Maintaining data consistency in performance runs
- Supporting disaster recovery
- Making data available from production databases for reporting and analytical purposes
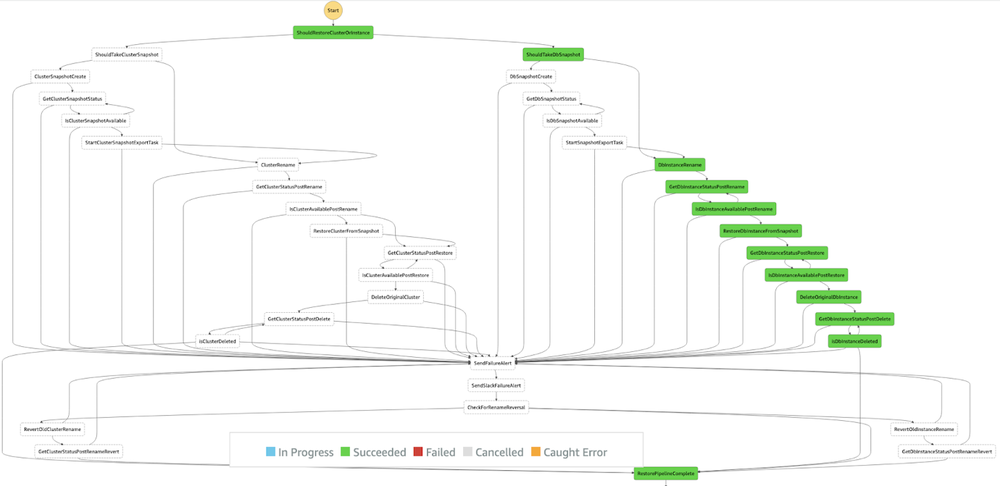
Managing snapshots involves many different steps and components, resulting in a complex workflow for both individual and cluster-based RDS instances. Trapheus automates these tasks with AWS serverless technology. Using AWS Step Functions, Trapheus is able to model the entire process of restoring an RDS instance from a snapshot as a distributed state machine. Designing various steps in the workflow as a state machine enables modularization, parallel execution of multiple steps, and makes the workflow easy to understand and debug.
AWS Step Functions then run multiple steps to restore an existing database from a snapshot. Modeling the process as a state machine using step functions allows for simplified error handling, retry logic, and core restoration logic, all within AWS Lambda. Different tasks in the restoration pipeline are run using individual AWS Lambda functions for database instances and database clusters respectively. AWS Lambda layers are used across the various Lambda functions for tasks, to enable abstraction of common utility methods, and to provide custom exception handling logic.
Trapheus also uses AWS SDK for Python (Boto3) to run operations on Amazon RDS through multiple AWS Lambda functions. Boto3 custom waiters are used with configurable delays and maximum retry attempts to track the status of each operation. Last, but not least, AWS Serverless Application Model (AWS SAM) models the needed application in YAML and AWS CloudFormation enables creation and deployment of Trapheus as an AWS CloudFormation template.
Trapheus was originally built by Intuit’s QuickBooks Online Advanced team, and it was quickly picked up by other teams working on QuickBooks Online to solve problems in their internal performance environments. This led Intuit to open source Trapheus, so that the larger IT community could benefit from this solution.
Getting started with Trapheus
To get started with Trapheus, make sure you have the necessary prerequisites installed and AWS services configured, as described on GitHub.
You also need to define some parameters in order to create the AWS CloudFormation template. A list of these parameters can also be found on GitHub. These parameters are used during this demonstration, so keep them handy.
Now, you should be ready to set up Trapheus.
1. Clone the Trapheus git repo.
2. From the Trapheus repo run:
3. Deploy the stack using:
This provides the standard Trapheus configuration; however, several different customizations are available to minimize cost or integrate with Slack as explained on the GitHub page.
For execution, do the following:
1. Navigate to the DBRestoreStateMachine definition from the Resources tab in the AWS CloudFormation section of the AWS Management Console.
2. Choose Start execution.
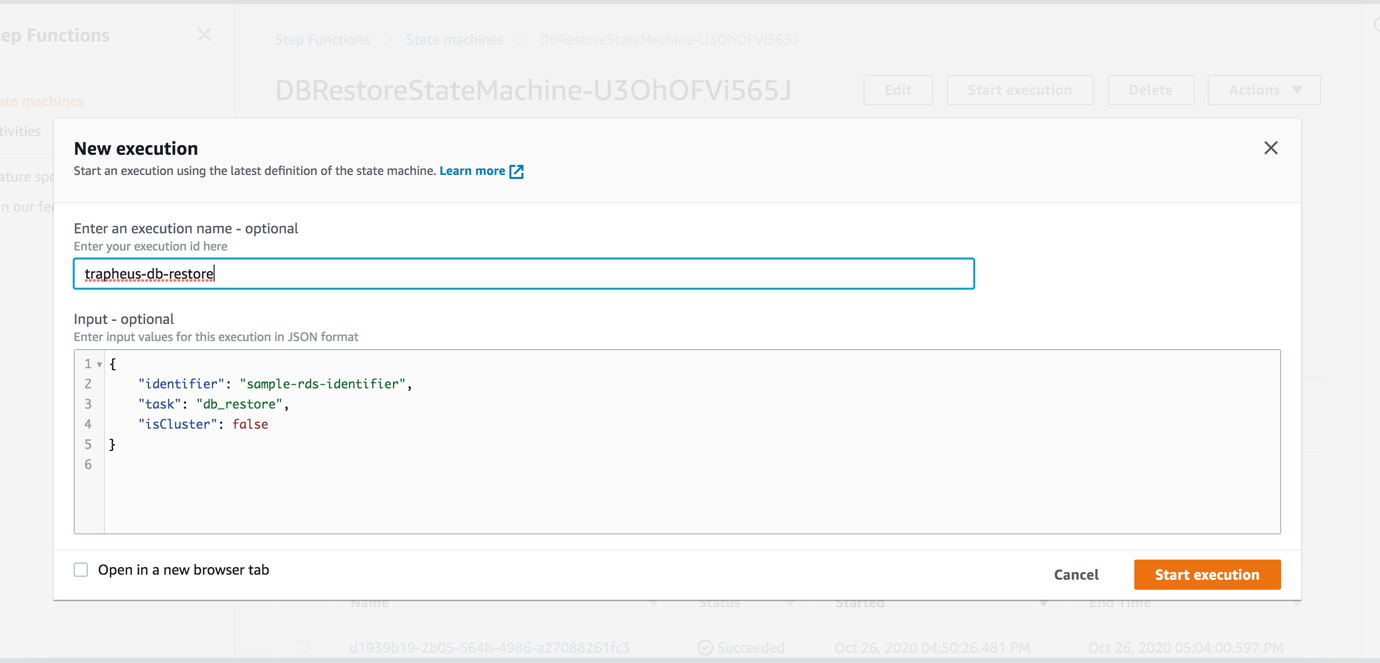
3. For Input, provide one of the following JSON sections as a parameter.
- To run the pipeline for database restoration, assuming that a snapshot already exists for the database instance, use:
- To run the pipeline to create/refresh the snapshot and then do the restoration, use:

More details on the execution can be found on the Trapheus GitHub page.
Roadmap
In the future, we plan to add support to Trapheus for creating data lakes, which builds on the present functionality of exporting a snapshot to Amazon S3 in Apache Parquet format. Our goal is to enable Trapheus to take multiple snapshots from Amazon S3 and create data lakes with queryable interfaces using Amazon Athena.
Summary
We hope this post gives everyone an introduction to Trapheus. The project is available under the open source MIT License, and you can learn more from the GitHub repository. Feel free to submit issues or pull requests. We are actively seeking new contributions, so if you are interested, review Contributing to Trapheus and check out our contributing guidelines. Thanks, and happy coding!
 width=”150″ height=”150″ />
width=”150″ height=”150″ />
Namita Devadas
Namita Devadas is a Senior Software Engineer at Intuit working as a full stack engineer. At Intuit she works for QBO Advanced, a product developed to solve complex accounting issues in the mid market space. In her spare time, she loves reading solving puzzles and cooking. Reach out to Namita at devadas.namita@gmail.com.
 width=”150″ height=”150″ />
width=”150″ height=”150″ />
Rohit Kumar
Rohit Kumar is a Senior Software Engineer in Intuit for Quick Books Online (QBO) Advanced. His primary focus is in cloud, distributed systems and web development. At Intuit, he works for QBO Advanced, a product developed to solve complex accounting issues in the mid-market space. Prior to joining Intuit, he worked at Amazon and Akamai, among other companies, where his focus was on building large scale distributed systems. In his spare time, he loves reading literature, psychology, and economics. You can contact Rohit Kumar directly by emailing him at rite2rohit88@gmail.com.
The content and opinions in this post are those of the third-party author and AWS is not responsible for the content or accuracy of this post.