AWS Public Sector Blog
AWS helps researchers study “messages” from the universe
Researchers at the IceCube Experiment and University of California, San Diego just completed the largest cloud simulation in history using 51,500 cloud GPUs including Amazon Elastic Compute Cloud (Amazon EC2) On-Demand and Spot Instances to understand messages from the universe.

The IceCube experiment searches for ghost-like massless particles called neutrinos deep within the ice at the South Pole using a unique buried cubic kilometer-size telescope consisting of 5,160 optical sensors. Exploding stars, black holes, and gamma-ray bursts send messages in the form of electromagnetic and gravitational waves as well as neutrino particles providing insights into the nature of the universe.
At highest energies and furthest distances, the universe is opaque to light and can only be observed by these gravitational waves and neutrinos. IceCube looks down, into, and through the Earth, rather than up into the sky. The “light” seen by this telescope, composed of neutrinos, is expected to help open a new window to the universe.
“Humanity has built these extraordinary instruments by pooling human and financial resources globally,” said Frank Würthwein, physics professor at the University of California, San Diego and Executive Director of the Open Science Grid. “Analyzing these messages will require exascale-level distributed computing that can be provided by cloud resources.”
The experiment was completed before the International Conference for High Performance Computing, Networking, Storage, and Analysis (SC19) in Denver, Colorado and was coordinated by Frank Würthwein and Benedikt Riedel, Computing Manager for the IceCube Neutrino Observatory and Global Computing Coordinator at WIPAC.
The experiment used simulations from the IceCube Neutrino Observatory funded under a National Science Foundation (NSF) EAGER grant. During the approximately two-hour experiment, 51,500 globally available NVIDIA GPUs in multi-cloud mode were used across Amazon Web Services (AWS), Google Cloud Platform, and Microsoft Azure. Eight generations of NVIDIA GPUs were used including the V100, the P100, the P40, the P4, the T4, the M60, the K80, and the K520 in 28 cloud regions across three continents (North America, Europe and Asia). A total of 3TB of input data for the workflow was pre-staged across all regions among the participating cloud providers. HTCondor was used to integrate all GPUs into a single resource pool, which IceCube submitted their workflows from their home base in Wisconsin.
“NSF’s support for multi-messenger astrophysics research like that conducted at the IceCube experiment, coupled with innovative approaches for aggregating accelerated computing services as part of its cyberinfrastructure ecosystem can foster scientific discoveries and innovations, as demonstrated by this project,” said Manish Parashar, Director Office of Advanced Cyberinfrastructure (OAC) at NSF. Multi-messenger astrophysics is one of NSF’s 10 Big Ideas to focus on during the next few years.
The image below shows the time evolution of the burst over the course of ~200 minutes. The black line is the number of GPUs used for science, peaking at 51,500 GPUs. Each color shows the number of GPUs purchased in a region of a cloud provider. The steep rise indicates the burst capability of the infrastructure to support short but intense computation for science.
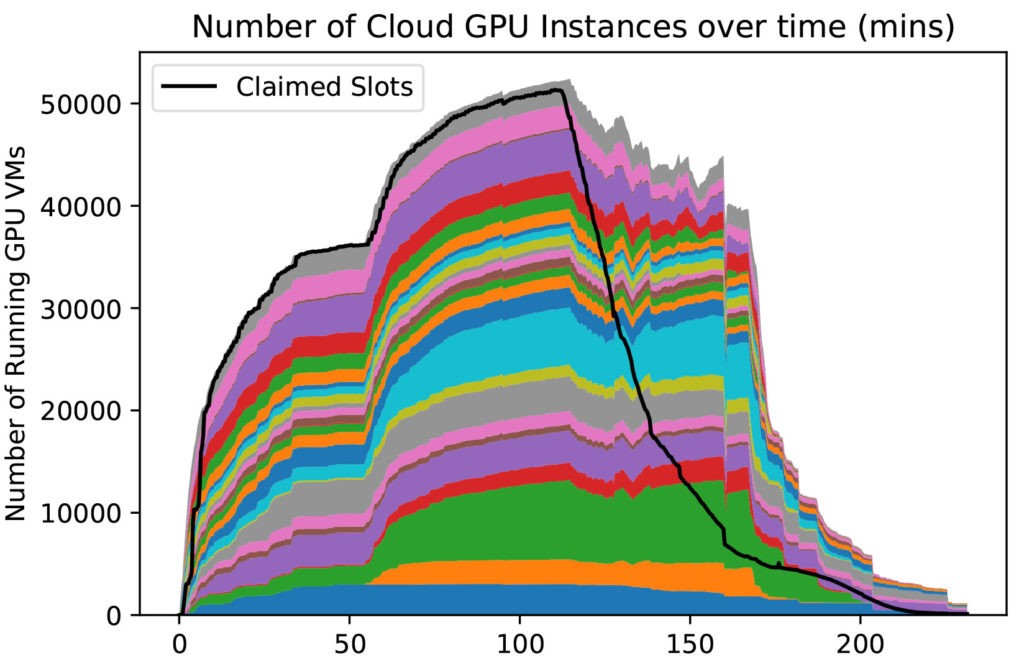
The result was a peak of about 51.5k GPUs of various kinds, with an aggregate peak of about 380 PFLOP32s (based on NVIDIA specifications), according to Igor Sfiligoi, SDSC’s lead scientific software developer for high-throughput computing.
“For comparison, the Number 1 TOP100 HPC system, Summit, (based at Oak Ridge National Laboratory) has a nominal performance of about 400 PFLOP32s. So, at peak, our cloud-based cluster provided almost 95% of the performance of Summit, at least for the purpose of IceCube simulations,” said Sfiligoi.
This experiment illustrates how globally distributed cloud resources can be harnessed (using HTCondor) by researchers to accelerate time to science. HTCondor Annex is available for researchers to repeat similar experiments and use AWS for additional studies.