AWS Security Blog
How to protect sensitive data for its entire lifecycle in AWS
April 25, 2023: We’ve updated this blog post to include more security learning resources.
Many Amazon Web Services (AWS) customer workflows require ingesting sensitive and regulated data such as Payments Card Industry (PCI) data, personally identifiable information (PII), and protected health information (PHI). In this post, I’ll show you a method designed to protect sensitive data for its entire lifecycle in AWS. This method can help enhance your data security posture and be useful for fulfilling the data privacy regulatory requirements applicable to your organization for data protection at-rest, in-transit, and in-use.
An existing method for sensitive data protection in AWS is to use the field-level encryption feature offered by Amazon CloudFront. This CloudFront feature protects sensitive data fields in requests at the AWS network edge. The chosen fields are protected upon ingestion and remain protected throughout the entire application stack. The notion of protecting sensitive data early in its lifecycle in AWS is a highly desirable security architecture. However, CloudFront can protect a maximum of 10 fields and only within HTTP(S) POST requests that carry HTML form encoded payloads.
If your requirements exceed CloudFront’s native field-level encryption feature, such as a need to handle diverse application payload formats, different HTTP methods, and more than 10 sensitive fields, you can implement field-level encryption yourself using the Lambda@Edge feature in CloudFront. In terms of choosing an appropriate encryption scheme, this problem calls for an asymmetric cryptographic system that will allow public keys to be openly distributed to the CloudFront network edges while keeping the corresponding private keys stored securely within the network core. One such popular asymmetric cryptographic system is RSA. Accordingly, we’ll implement a Lambda@Edge function that uses asymmetric encryption using the RSA cryptosystem to protect an arbitrary number of fields in any HTTP(S) request. We will discuss the solution using an example JSON payload, although this approach can be applied to any payload format.
A complex part of any encryption solution is key management. To address that, I use AWS Key Management Service (AWS KMS). AWS KMS simplifies the solution and offers improved security posture and operational benefits, detailed later.
Solution overview
You can protect data in-transit over individual communications channels using transport layer security (TLS), and at-rest in individual storage silos using volume encryption, object encryption or database table encryption. However, if you have sensitive workloads, you might need additional protection that can follow the data as it moves through the application stack. Fine-grained data protection techniques such as field-level encryption allow for the protection of sensitive data fields in larger application payloads while leaving non-sensitive fields in plaintext. This approach lets an application perform business functions on non-sensitive fields without the overhead of encryption, and allows fine-grained control over what fields can be accessed by what parts of the application.
A best practice for protecting sensitive data is to reduce its exposure in the clear throughout its lifecycle. This means protecting data as early as possible on ingestion and ensuring that only authorized users and applications can access the data only when and as needed. CloudFront, when combined with the flexibility provided by Lambda@Edge, provides an appropriate environment at the edge of the AWS network to protect sensitive data upon ingestion in AWS.
Since the downstream systems don’t have access to sensitive data, data exposure is reduced, which helps to minimize your compliance footprint for auditing purposes.
The number of sensitive data elements that may need field-level encryption depends on your requirements. For example:
- For healthcare applications, HIPAA regulates 18 personal data elements.
- In California, the California Consumer Privacy Act (CCPA) regulates at least 11 categories of personal information—each with its own set of data elements.
The idea behind field-level encryption is to protect sensitive data fields individually, while retaining the structure of the application payload. The alternative is full payload encryption, where the entire application payload is encrypted as a binary blob, which makes it unusable until the entirety of it is decrypted. With field-level encryption, the non-sensitive data left in plaintext remains usable for ordinary business functions. When retrofitting data protection in existing applications, this approach can reduce the risk of application malfunction since the data format is maintained.
The following figure shows how PII data fields in a JSON construction that are deemed sensitive by an application can be transformed from plaintext to ciphertext with a field-level encryption mechanism.

Figure 1: Example of field-level encryption
You can change plaintext to ciphertext as depicted in Figure 1 by using a Lambda@Edge function to perform field-level encryption. I discuss the encryption and decryption processes separately in the following sections.
Field-level encryption process
Let’s discuss the individual steps involved in the encryption process as shown in Figure 2.
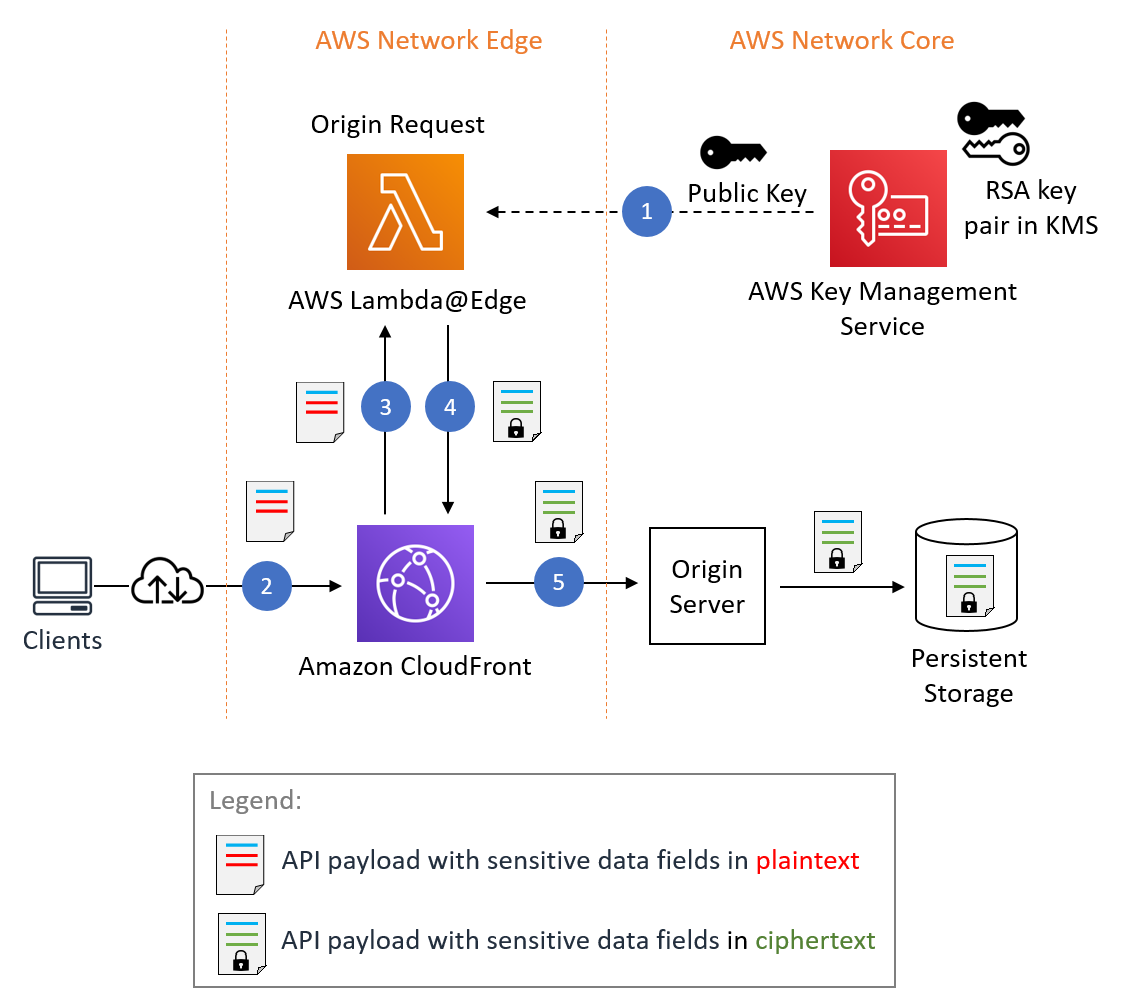
Figure 2: Field-level encryption process
Figure 2 shows CloudFront invoking a Lambda@Edge function while processing a client request. CloudFront offers multiple integration points for invoking Lambda@Edge functions. Since you are processing a client request and your encryption behavior is related to requests being forwarded to an origin server, you want your function to run upon the origin request event in CloudFront. The origin request event represents an internal state transition in CloudFront that happens immediately before CloudFront forwards a request to the downstream origin server.
You can associate your Lambda@Edge with CloudFront as described in Adding Triggers by Using the CloudFront Console. A screenshot of the CloudFront console is shown in Figure 3. The selected event type is Origin Request and the Include Body check box is selected so that the request body is conveyed to Lambda@Edge.

Figure 3: Configuration of Lambda@Edge in CloudFront
The Lambda@Edge function acts as a programmable hook in the CloudFront request processing flow. You can use the function to replace the incoming request body with a request body with the sensitive data fields encrypted.
The process includes the following steps:
Step 1 – RSA key generation and inclusion in Lambda@Edge
You can generate an RSA customer managed key (CMK) in AWS KMS as described in Creating asymmetric CMKs. This is done at system configuration time.
Note: You can use your existing RSA key pairs or generate new ones externally by using OpenSSL commands, especially if you need to perform RSA decryption and key management independently of AWS KMS. Your choice won’t affect the fundamental encryption design pattern presented here.
The RSA key creation in AWS KMS requires two inputs: key length and type of usage. In this example, I created a 2048-bit key and assigned its use for encryption and decryption. The cryptographic configuration of an RSA CMK created in AWS KMS is shown in Figure 4.
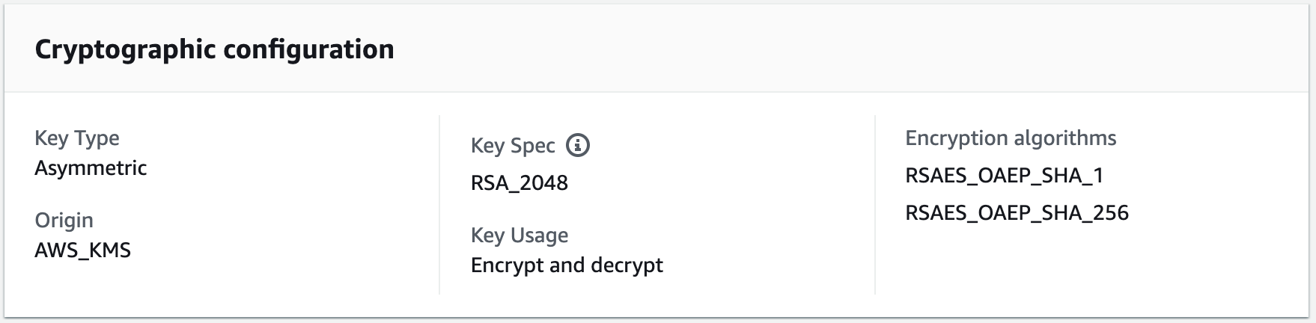
Figure 4: Cryptographic properties of an RSA key managed by AWS KMS
Of the two encryption algorithms shown in Figure 4— RSAES_OAEP_SHA_256 and RSAES_OAEP_SHA_1, this example uses RSAES_OAEP_SHA_256. The combination of a 2048-bit key and the RSAES_OAEP_SHA_256 algorithm lets you encrypt a maximum of 190 bytes of data, which is enough for most PII fields. You can choose a different key length and encryption algorithm depending on your security and performance requirements. How to choose your CMK configuration includes information about RSA key specs for encryption and decryption.
Using AWS KMS for RSA key management versus managing the keys yourself eliminates that complexity and can help you:
- Enforce IAM and key policies that describe administrative and usage permissions for keys.
- Manage cross-account access for keys.
- Monitor and alarm on key operations through Amazon CloudWatch.
- Audit AWS KMS API invocations through AWS CloudTrail.
- Record configuration changes to keys and enforce key specification compliance through AWS Config.
- Generate high-entropy keys in an AWS KMS hardware security module (HSM) as required by NIST.
- Store RSA private keys securely, without the ability to export.
- Perform RSA decryption within AWS KMS without exposing private keys to application code.
- Categorize and report on keys with key tags for cost allocation.
- Disable keys and schedule their deletion.
You need to extract the RSA public key from AWS KMS so you can include it in the AWS Lambda deployment package. You can do this from the AWS Management Console, through the AWS KMS SDK, or by using the get-public-key command in the AWS Command Line Interface (AWS CLI). Figure 5 shows Copy and Download options for a public key in the Public key tab of the AWS KMS console.
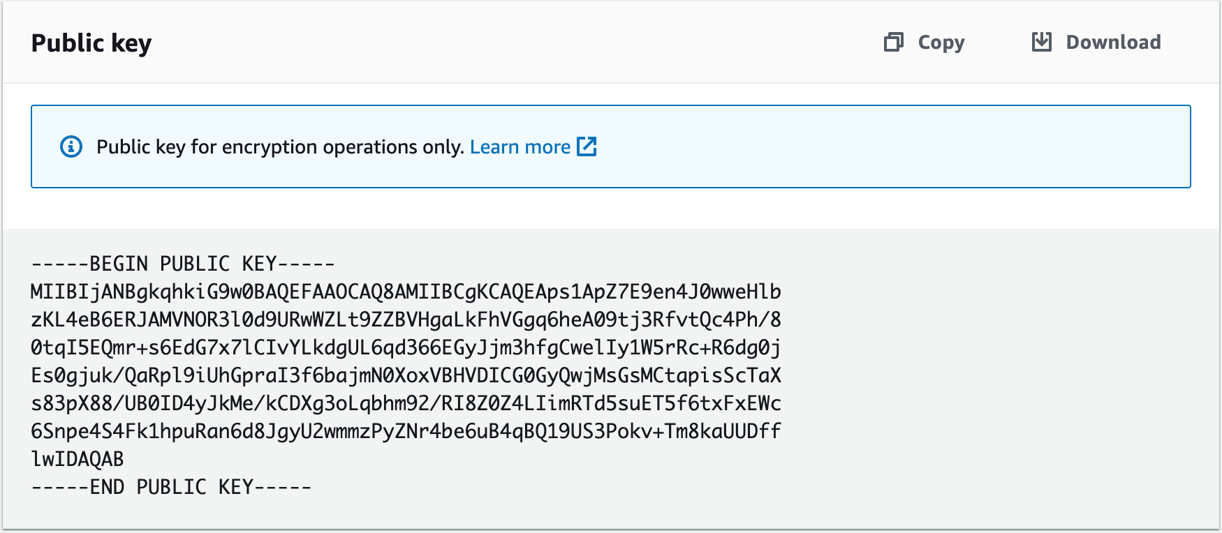
Figure 5: RSA public key available for copy or download in the console
Note: As we will see in the sample code in step 3, we embed the public key in the Lambda@Edge deployment package. This is a permissible practice because public keys in asymmetric cryptography systems aren’t a secret and can be freely distributed to entities that need to perform encryption. Alternatively, you can use Lambda@Edge to query AWS KMS for the public key at runtime. However, this introduces latency, increases the load against your KMS account quota, and increases your AWS costs. General patterns for using external data in Lambda@Edge are described in Leveraging external data in Lambda@Edge.
Step 2 – HTTP API request handling by CloudFront
CloudFront receives an HTTP(S) request from a client. CloudFront then invokes Lambda@Edge during origin-request processing and includes the HTTP request body in the invocation.
Step 3 – Lambda@Edge processing
The Lambda@Edge function processes the HTTP request body. The function extracts sensitive data fields and performs RSA encryption over their values.
The following code is sample source code for the Lambda@Edge function implemented in Python 3.7:
import Crypto
import base64
import json
from Crypto.Cipher import PKCS1_OAEP
from Crypto.PublicKey import RSA
# PEM-formatted RSA public key copied over from AWS KMS or your own public key.
RSA_PUBLIC_KEY = "-----BEGIN PUBLIC KEY-----<your key>-----END PUBLIC KEY-----"
RSA_PUBLIC_KEY_OBJ = RSA.importKey(RSA_PUBLIC_KEY)
RSA_CIPHER_OBJ = PKCS1_OAEP.new(RSA_PUBLIC_KEY_OBJ, Crypto.Hash.SHA256)
# Example sensitive data field names in a JSON object.
PII_SENSITIVE_FIELD_NAMES = ["fname", "lname", "email", "ssn", "dob", "phone"]
CIPHERTEXT_PREFIX = "#01#"
CIPHERTEXT_SUFFIX = "#10#"
def lambda_handler(event, context):
# Extract HTTP request and its body as per documentation:
# https://docs.aws.amazon.com/AmazonCloudFront/latest/DeveloperGuide/lambda-event-structure.html
http_request = event['Records'][0]['cf']['request']
body = http_request['body']
org_body = base64.b64decode(body['data'])
mod_body = protect_sensitive_fields_json(org_body)
body['action'] = 'replace'
body['encoding'] = 'text'
body['data'] = mod_body
return http_request
def protect_sensitive_fields_json(body):
# Encrypts sensitive fields in sample JSON payload shown earlier in this post.
# [{"fname": "Alejandro", "lname": "Rosalez", … }]
person_list = json.loads(body.decode("utf-8"))
for person_data in person_list:
for field_name in PII_SENSITIVE_FIELD_NAMES:
if field_name not in person_data:
continue
plaintext = person_data[field_name]
ciphertext = RSA_CIPHER_OBJ.encrypt(bytes(plaintext, 'utf-8'))
ciphertext_b64 = base64.b64encode(ciphertext).decode()
# Optionally, add unique prefix/suffix patterns to ciphertext
person_data[field_name] = CIPHERTEXT_PREFIX + ciphertext_b64 + CIPHERTEXT_SUFFIX
return json.dumps(person_list)
The event structure passed into the Lambda@Edge function is described in Lambda@Edge Event Structure. Following the event structure, you can extract the HTTP request body. In this example, the assumption is that the HTTP payload carries a JSON document based on a particular schema defined as part of the API contract. The input JSON document is parsed by the function, converting it into a Python dictionary. The Python native dictionary operators are then used to extract the sensitive field values.
Note: If you don’t know your API payload structure ahead of time or you’re dealing with unstructured payloads, you can use techniques such as regular expression pattern searches and checksums to look for patterns of sensitive data and target them accordingly. For example, credit card primary account numbers include a Luhn checksum that can be programmatically detected. Additionally, services such as Amazon Comprehend and Amazon Macie can be leveraged for detecting sensitive data such as PII in application payloads.
While iterating over the sensitive fields, individual field values are encrypted using the standard RSA encryption implementation available in the Python Cryptography Toolkit (PyCrypto). The PyCrypto module is included within the Lambda@Edge zip archive as described in Lambda@Edge deployment package.
The example uses the standard optimal asymmetric encryption padding (OAEP) and SHA-256 encryption algorithm properties. These properties are supported by AWS KMS and will allow RSA ciphertext produced here to be decrypted by AWS KMS later.
Note: You may have noticed in the code above that we’re bracketing the ciphertexts with predefined prefix and suffix strings:
person_data[field_name] = CIPHERTEXT_PREFIX + ciphertext_b64 + CIPHERTEXT_SUFFIXThis is an optional measure and is being implemented to simplify the decryption process.
The prefix and suffix strings help demarcate ciphertext embedded in unstructured data in downstream processing and also act as embedded metadata. Unique prefix and suffix strings allow you to extract ciphertext through string or regular expression (regex) searches during the decryption process without having to know the data body format or schema, or the field names that were encrypted.
Distinct strings can also serve as indirect identifiers of RSA key pair identifiers. This can enable key rotation and allow separate keys to be used for separate fields depending on the data security requirements for individual fields.
You can ensure that the prefix and suffix strings can’t collide with the ciphertext by bracketing them with characters that don’t appear in cyphertext. For example, a hash (#) character cannot be part of a base64 encoded ciphertext string.
Deploying a Lambda function as a Lambda@Edge function requires specific IAM permissions and an IAM execution role. Follow the Lambda@Edge deployment instructions in Setting IAM Permissions and Roles for Lambda@Edge.
Step 4 – Lambda@Edge response
The Lambda@Edge function returns the modified HTTP body back to CloudFront and instructs it to replace the original HTTP body with the modified one by setting the following flag:
http_request['body']['action'] = 'replace'
Step 5 – Forward the request to the origin server
CloudFront forwards the modified request body provided by Lambda@Edge to the origin server. In this example, the origin server writes the data body to persistent storage for later processing.
Field-level decryption process
An application that’s authorized to access sensitive data for a business function can decrypt that data. An example decryption process is shown in Figure 6. The figure shows a Lambda function as an example compute environment for invoking AWS KMS for decryption. This functionality isn’t dependent on Lambda and can be performed in any compute environment that has access to AWS KMS.
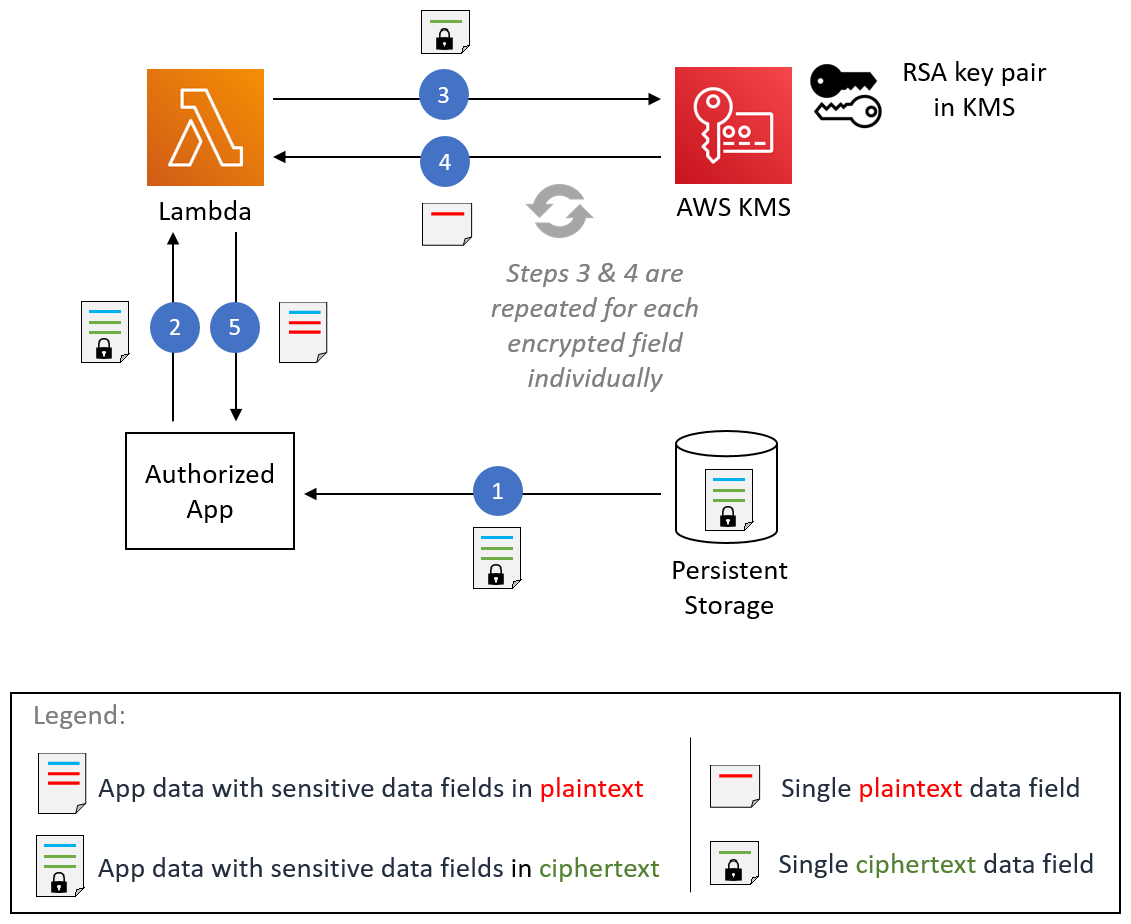
Figure 6: Field-level decryption process
The steps of the process shown in Figure 6 are described below.
Step 1 – Application retrieves the field-level encrypted data
The example application retrieves the field-level encrypted data from persistent storage that had been previously written during the data ingestion process.
Step 2 – Application invokes the decryption Lambda function
The application invokes a Lambda function responsible for performing field-level decryption, sending the retrieved data to Lambda.
Step 3 – Lambda calls the AWS KMS decryption API
The Lambda function uses AWS KMS for RSA decryption. The example calls the KMS decryption API that inputs ciphertext and returns plaintext. The actual decryption happens in KMS; the RSA private key is never exposed to the application, which is a highly desirable characteristic for building secure applications.
Note: If you choose to use an external key pair, then you can securely store the RSA private key in AWS services like AWS Systems Manager Parameter Store or AWS Secrets Manager and control access to the key through IAM and resource policies. You can fetch the key from relevant vault using the vault’s API, then decrypt using the standard RSA implementation available in your programming language. For example, the cryptography toolkit in Python or javax.crypto in Java.
The Lambda function Python code for decryption is shown below.
import base64
import boto3
import re
kms_client = boto3.client('kms')
CIPHERTEXT_PREFIX = "#01#"
CIPHERTEXT_SUFFIX = "#10#"
# This lambda function extracts event body, searches for and decrypts ciphertext
# fields surrounded by provided prefix and suffix strings in arbitrary text bodies
# and substitutes plaintext fields in-place.
def lambda_handler(event, context):
org_data = event["body"]
mod_data = unprotect_fields(org_data, CIPHERTEXT_PREFIX, CIPHERTEXT_SUFFIX)
return mod_data
# Helper function that performs non-greedy regex search for ciphertext strings on
# input data and performs RSA decryption of them using AWS KMS
def unprotect_fields(org_data, prefix, suffix):
regex_pattern = prefix + "(.*?)" + suffix
mod_data_parts = []
cursor = 0
# Search ciphertexts iteratively using python regular expression module
for match in re.finditer(regex_pattern, org_data):
mod_data_parts.append(org_data[cursor: match.start()])
try:
# Ciphertext was stored as Base64 encoded in our example. Decode it.
ciphertext = base64.b64decode(match.group(1))
# Decrypt ciphertext using AWS KMS
decrypt_rsp = kms_client.decrypt(
EncryptionAlgorithm="RSAES_OAEP_SHA_256",
KeyId="<Your-Key-ID>",
CiphertextBlob=ciphertext)
decrypted_val = decrypt_rsp["Plaintext"].decode("utf-8")
mod_data_parts.append(decrypted_val)
except Exception as e:
print ("Exception: " + str(e))
return None
cursor = match.end()
mod_data_parts.append(org_data[cursor:])
return "".join(mod_data_parts)
The function performs a regular expression search in the input data body looking for ciphertext strings bracketed in predefined prefix and suffix strings that were added during encryption.
While iterating over ciphertext strings one-by-one, the function calls the AWS KMS decrypt() API. The example function uses the same RSA encryption algorithm properties—OAEP and SHA-256—and the Key ID of the public key that was used during encryption in Lambda@Edge.
Note that the Key ID itself is not a secret. Any application can be configured with it, but that doesn’t mean any application will be able to perform decryption. The security control here is that the AWS KMS key policy must allow the caller to use the Key ID to perform the decryption. An additional security control is provided by Lambda execution role that should allow calling the KMS decrypt() API.
Step 4 – AWS KMS decrypts ciphertext and returns plaintext
To ensure that only authorized users can perform decrypt operation, the KMS is configured as described in Using key policies in AWS KMS. In addition, the Lambda IAM execution role is configured as described in AWS Lambda execution role to allow it to access KMS. If both the key policy and IAM policy conditions are met, KMS returns the decrypted plaintext. Lambda substitutes the plaintext in place of ciphertext in the encapsulating data body.
Steps three and four are repeated for each ciphertext string.
Step 5 – Lambda returns decrypted data body
Once all the ciphertext has been converted to plaintext and substituted in the larger data body, the Lambda function returns the modified data body to the client application.
Conclusion
In this post, I demonstrated how you can implement field-level encryption integrated with AWS KMS to help protect sensitive data workloads for their entire lifecycle in AWS. Since your Lambda@Edge is designed to protect data at the network edge, data remains protected throughout the application execution stack. In addition to improving your data security posture, this protection can help you comply with data privacy regulations applicable to your organization.
Since you author your own Lambda@Edge function to perform standard RSA encryption, you have flexibility in terms of payload formats and the number of fields that you consider to be sensitive. The integration with AWS KMS for RSA key management and decryption provides significant simplicity, higher key security, and rich integration with other AWS security services enabling an overall strong security solution.
By using encrypted fields with identifiers as described in this post, you can create fine-grained controls for data accessibility to meet the security principle of least privilege. Instead of granting either complete access or no access to data fields, you can ensure least privileges where a given part of an application can only access the fields that it needs, when it needs to, all the way down to controlling access field by field. Field by field access can be enabled by using different keys for different fields and controlling their respective policies.
In addition to protecting sensitive data workloads to meet regulatory and security best practices, this solution can be used to build de-identified data lakes in AWS. Sensitive data fields remain protected throughout their lifecycle, while non-sensitive data fields remain in the clear. This approach can allow analytics or other business functions to operate on data without exposing sensitive data.
If you have feedback about this post, submit comments in the Comments section below.
Want more AWS Security how-to content, news, and feature announcements? Follow us on Twitter.