AWS Startups Blog
How HeyJobs Ingests Millions of Jobs with AWS Lambda

Guest post by Gokay Kucuk, Engineering Manager, Inventory – Integrations Team, HeyJobs
At HeyJobs, we’re aiming to be the leading platform for those looking for the right job to live a fulfilling life. Serving millions of job seekers means that we need to ingest hundreds of thousands to future millions of job-offering details, multiple times a day, every day.
In this blog post, I will share our learnings about the AWS services we utilized for our serverless transformation. At the end of this transformation, the job ingestion capacity of HeyJobs grew from few hundred thousand to few millions per day while reducing our costs by ~30%.
In our first iteration of this ingestion service, we decided to make the inventory project its own service written in Ruby on Rails, as Rails was the most known framework in our company with PostgreSQL as the database. We utilized Sidekiq (a Rails job scheduling library) for background workers and data processing. The project was running on Amazon Elastic Container Service (Amazon ECS), and it was using RabbitMQ as the main communication tool with our monolith.

At first, our service was running smoothly, but with time, the number of job postings we processed grew from thousands a day to tens of thousands, and then to hundreds of thousands. This made us push more and more processing to the database layer with long and complicated SQL queries to be able to process everything in time. But it was still not enough. We still experienced high variance in processing times, which made us uncertain about our scalability metrics. Deploying larger instances would’ve solved the problem only temporarily while growing our costs by a large margin. We had to do something differently, but what?
Signal for Serverless Transformation
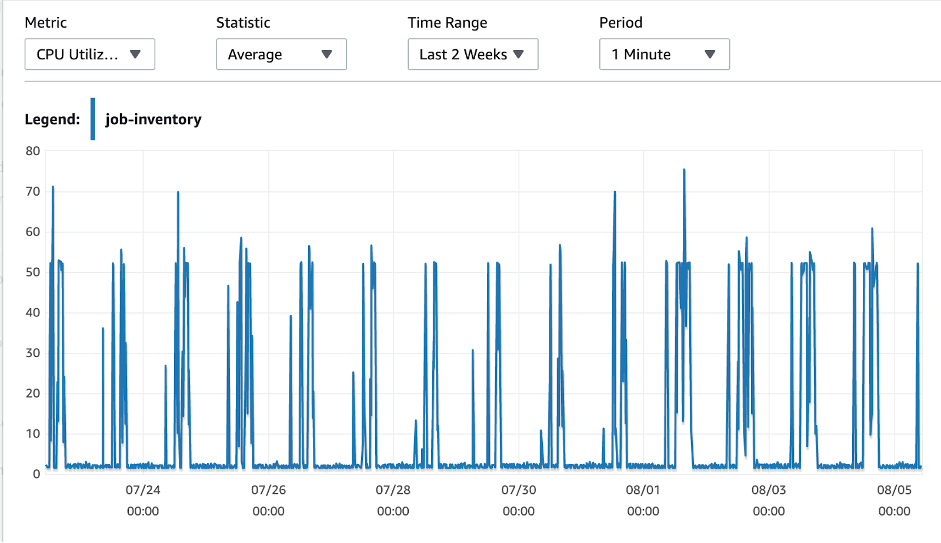
An important aspect of our project was that it needed to import job details at certain times, which created a very spiky usage pattern. We believe spiky usage is one of the most important triggers for serverless transformation. You can find the CPU utilization of our database server below.
Overview of Solution
Given that we needed to scale to accommodate spiking workloads, we decided to use Amazon Aurora Serverless since it scales to meet our demand. Combined with AWS Lambda functions for code execution, this setup gave us the greatest scaling possibilities, both up and down. We still wanted to keep our Rails monolith and minimize disruption, but our RabbitMQ provider had a hard cap on messages/sec processed. We decided to replace it with an Amazon Simple Queue Service (Amazon SQS) queue to remove this limitation as our processing was going to scale with demand.
We also decided to put another SQS queue at the start of our process to handle scaling windows of Aurora Serverless.
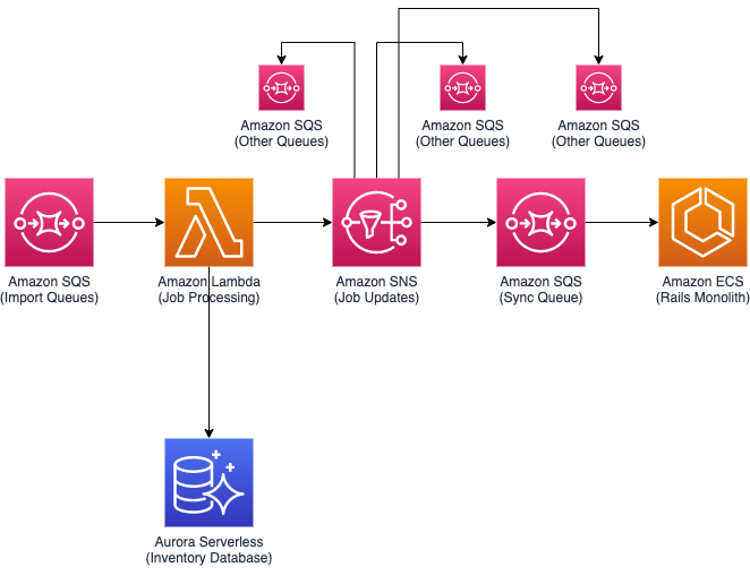
Amazon SQS and Amazon SNS
We utilize SQS and Amazon Simple Notification Service (Amazon SNS) heavily in our application. While we already had RabbitMQ queues for internal messaging, it was a rather alien component for most of the developers and did not provide any specific benefits for our use-case. Switching to SQS with Serverless Framework and deploying a new queue for a new function became easy and part of development. The more functionality we exposed with SQS as the trigger, the more we noticed that we ended up with more decoupled services we could build on top of.
Our application–based on event-driven architecture–has 2 main methods of communication:
- Commands: We use SQS for triggering commands. We do care about what happens when a command fails within our domain, and having them in a queue lets us retry or route them. We try to make sure every command gets executed.
- Events: We use SNS for publishing events. We don’t really care about what happens to an event, because it’s mostly going to be consumed from other domains/teams. We try to subscribe to this event from SQS queues from the domain that wants to consume the event. This creates a clear boundary between teams/domains.
Idempotent Operations
Using SQS as the main source of trigger for our Lambda functions required us to make our operations idempotent. If the SQS queue is not set-up in FIFO mode, it is an “at-least-once-delivery” queue system. This means sometimes it can deliver the same message more than once. While processing a low number of messages in SQS, we didn’t see any duplicated deliveries, but as soon as the number of messages in a queue grew to millions, we started seeing duplicate deliveries. This pushed us towards always trying to make our operations idempotent. As a bonus, making our operations idempotent made it easier to integrate other producers from our service landscape to the same SQS queues as we had to worry about states in our functions less.
Aurora Serverless
Aurora Serverless was the most novel component of the entire stack when we designed it, but after researching its capabilities we decided to use it as our main database. We had Lambdas as the main load generator to our database with SQS. Both components can scale fast. Having an ordinary database server would need us to either:
- Deploy a database instance that ccouldan handle the peak load, but it would be wasteful as our loads were spiky.
- Deploy a database instance that is rather small, which would cost less, but it would make our processing longer.
By choosing Aurora Serverless, we managed to both pay only as much as we needed while being able to scale up to very large instances to speed up our processing. We found out its scaling characteristics were a good fit for fast SQL queries, as having analytical long-running SQL queries makes it harder for Aurora Serverless to find scaling points.
Docker and Lambda
A recent update to Lambda made it possible to run docker images with Lambda as runtime. Previously, Lambda had a hard limit of 250 MB on the amount of source/library code that a Lambda function could have. The code also needed to be deployed in a special zip format, which most teams were not used to if they weren’t deploying AWS Lambda functions.
With the docker image support, the new size limitation for AWS Lambda is 10GB. This disk space is forgiving when it comes to loading large libraries and having big codebases. The image can be created from any CI system and published to an Amazon Elastic Container Registry (Amazon ECR) repository. This creates a perfect boundary for cross-team projects.
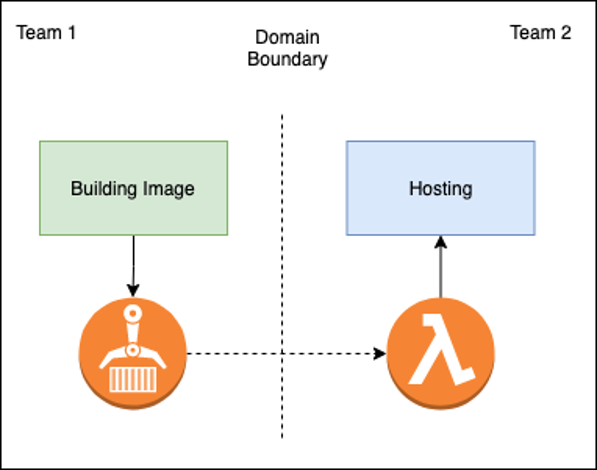
This method simply let us plug a docker image from another team into our processing pipeline, while having an infrastructure-as-code form Serverless Framework let us easily deploy a testing platform for other teams.
Conclusion
We saw lots of improvements during our move from a containerized Rails application to a serverless python application both in reduced complexity(~70%) and reduced costs(~%30). Our initial target for moving our application to a serverless architecture was mainly driven by our need to scale up and down many times during the day while trying to minimize development and running costs. While scaling could be also achieved with containers, it wouldn’t have been as easy as scaling Lambdas. We had to change our mindset and approach to problem-solving in certain situations. We started designing our applications in a more event-driven architecture with following domain driven design principles. This setup gave us a similar comfort level when it came to development, in comparison to the Rails environment that we were used to. After running our new application for a few months, we are happy with the results and have started to leverage the serverless setup in other areas. Follow us on our tech blogto learn more!
About the Author

Gokay Kucuk is an Engineering Manager working at HeyJobs Inventory and Integration teams, and he is always interested in learning more and utilizing the latest and greatest technology available. His main interests are serverless, blockchain (sauerbot), generative art (pollinations.ai), and photography. You can reach him on LinkedIn or gokay@hey.com