AWS Startups Blog
A Systematic Approach for Analytics Services Migration from GCP to AWS
Post by Frank Wang, Senior Startup Solutions Architect, AWS
Introduction
We often hear customers tell us they “are considering moving from Google BigQuery to AWS, but not sure where to start and how to do it.” Nowadays, it is not uncommon to see customers switching cloud vendors for their workloads for various reasons, including functionality, performance, scalability, cost, or consolidation of their cloud vendors. One of these workloads’ migration inquiries is in data analytics space, where customers seeking guidance on migrating, for example, their Google data analytics workloads to AWS.
In this post, we present a systematic approach to guide customers migrating a few commonly used cloud data analytics services from Google Cloud Platform (GCP) to AWS. Rather than a detailed step-by-step implementation guide for a specific service, the post is intended to provide a holistic view and systematic approach for the migrations of these GCP services to AWS.
Cloud Analytics Services – A Quick Glance
In this section, we have a quick glance at a few popular data analytics-related services in the cloud analytics offerings on AWS and GCP. The information provided here is for migration consideration rather than detailed service comparisons. For more details about the complete offerings from each cloud provider, please see below:
The following table lists some commonly used data analytics-related cloud services offered by AWS and GCP, including storage, data warehouse, NoSQL DB (HBase), Hadoop, Extract-Transform-Load (ETL), data processing pipeline, and application development platform with the associated data store.
In the following sections, we take a closer look at some of these services and their migration paths from GCP to AWS.
Workload Migration Paths
When designing your analytic services migrations from one vendor to the other, there is usually not one definite fixed path for the migrations, so there are several factors to consider when trying to migrate these workloads from GCP to AWS. For example, you might ask yourself these sample questions before you determine the migration targets and paths:
- Core functionality – does the target service(s) provide the required core analytics functionality?
- Data volumes/size – how large is the dataset?
- Update and query patterns/frequency – how frequently the data is being updated? What is the query access pattern (e.g. pre-defined complex queries, or ad-hoc queries)?
- Performance/latency requirements – are these real-time queries? What is the query latency requirement?
- Cost – what is cost structure in running these analytic services, including storage, requests, and backup etc.?
With that in mind, here are a few migration paths commonly seen moving from GCP to AWS with focus on functionality parity as the primary migration consideration:
BigQuery – Data Warehouse Platform
For customers using BigQuery as their official data warehouse platform with well-defined data schemas and predefined queries and frequent access patterns, migration to Amazon Redshift (and Amazon Redshift Spectrum) is the typical candidate migration path. However, for customers with less strict data schemas, ad-hoc query usage patterns and a large (unstructured/semi-structured) dataset, Amazon Athena, with its highly scalable storage layer based on Amazon S3, together with AWS Glue for data catalog and transformation, is usually the recommended migration path. If customers require further data processing capability with other programming interfaces supported (e.g. Hadoop and Spark), Amazon EMR with Hive and Spark is a better migration target service. The following diagram shows a high level decision flow for BigQuery migration paths to AWS. Please note that these are the typical migration paths. Depending on the source workload characteristics and datasets, there may be other migration paths for more specific use case considerations.

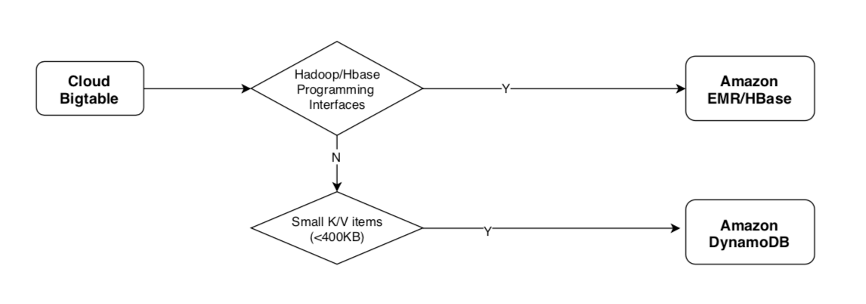
Bigtable – NoSQL Database Service
Bigtable is Google’s NoSQL database service. It is essentially a key-value pair, columnar-based database. It integrates with existing Apache ecosystems of open-sources Big Data software, including HBase library for java, thus the typical migration path is to Amazon EMR/HBase NoSQL database. For smaller key-value pair items not requiring HBase interface, Amazon DynamoDB can also be a migration target candidate, as it provides similar low latency, high throughput, and fully managed serverless architecture. The following diagram shows the typical migration paths for GCP Bigtable to AWS.
Firebase – Application Development Platform and Databases
Firebase is Google’s offering for mobile and web application development. The most commonly seen migration path is to move to AWS Amplify, a platform that builds and deploys secure, scalable, full stack applications on AWS. Firebase uses two database solutions (Realtime database & Cloud Firestore), both of which are essentially JSON-based document databases. To migrate the Firebase databases to AWS, for small documents, Amazon DynamoDB is the typical migration database target which is fully integrated with Amazon Amplify and supports global data replications. If the documents are too large and complex requiring specific interfaces or complex search capabilities, then other AWS document-based databases such as Amazon DocumentDB (with MongoDB compatibility) or Amazon ElasticSearch Service can be considered as the alternative target databases for the specific use cases. The potential migration paths for Firebase and its application data stores are depicted in the following diagram.

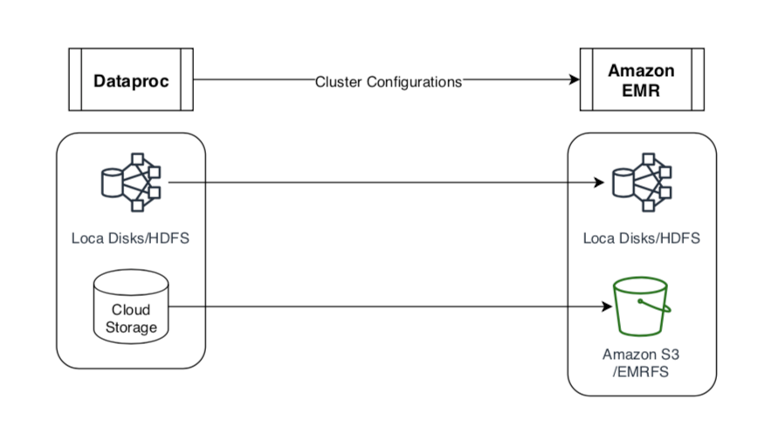
Hadoop Big Data Workload
Customers using Google’s Dataproc, a Hadoop Big Data framework, will also find a typical migration path to Amazon EMR service. The data (storage) layer Dataproc uses (HDFS local storage or in Cloud Storage) can also be migrated to corresponding AWS EMR storage options (Local Cluster Disks & Amazon S3-EMRFS) as shown in the following picture.
Systematic Migration Guide
With the migration paths outlined in the previous section, we describe a more systematic approach for these services’ migrations to AWS in this section. We first start out by providing a few high-level migration guiding principles:
1. Analyze the current workloads thoroughly, and define the target architecture and migration paths based on the requirements and constraints.
2. Following the data lake concept, try using source tooling to transform and export the source data into proper data format(s) and funneling the data into the common data storage area first.
3. Move the data across the cloud boundaries to AWS in as reliable and efficient a manner as possible.
4. Once the data is moved to AWS, perform additional data cleansing and transformations (format, schema, etc.) as necessary.
5. Leverage AWS internal tooling to migrate the data to target data stores/services.
6. Migrate other artifacts (e.g., platform configurations) as necessary.
The following diagram illustrates the migration solutions architecture for the GCP analytic services mentioned above to AWS.

Foundational Components for the Migrations
In this section, we outline the key components required for the migrations:
- Transitional Data Lakes: these refer to Amazon S3 and Google Cloud Storage, which serve as the transitional storage areas for all the migration activities in and out of the cloud platforms’ boundaries.
- Data formats: these refer to the most commonly seen data formats being used to store in and/or import/export out of these analytics services. The following table summarizes the key characteristics of these data formats.

As you can see from the above table, these data formats share and differentiate various characteristics and are suited for different data stores and use cases. For more detailed benchmark of these file formats please see here. From a migration standpoint, we look for more flexible schema evolution data format to potentially minimize the data transformation needs, thus AVRO, JSON or Parquet data formats are often selected as intermediate data formats for migration purpose. After the data is migrated to the target cloud platforms’ transitional data lake, the data format for the target architecture can be further transformed and optimized.
- Tooling: both cloud platforms provide equivalent tooling mechanisms for migrations. The following table summarizes the main tooling used for data services migrations.
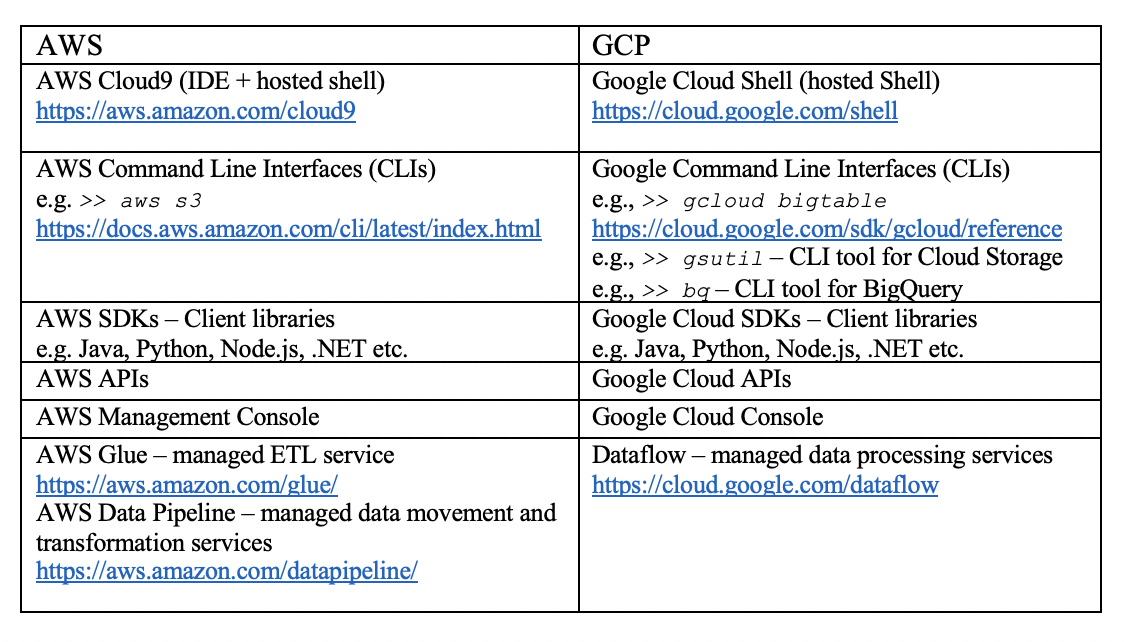
This tooling can be used to provide the necessary functionality for the transformation, processing, and data movement among these services as required by the migration tasks, depending on the complexity. As a general observation, Command Line Interfaces (CLIs) are the most commonly used tooling for DevOps, administrators and developers to experiment and conduct the migration tasks. In the following section, we will illustrate these migration examples primarily using the CLIs plus some other tooling where CLI capability is not available.
Practical Migration Considerations
Depending on the complexity of the source analytics workloads (on GCP’s side), there are many factors to consider for the migration tasks’ design, such as:
- Data models and schemas – If there are data model mismatches between the source and the target, or further design optimization consideration based on the target service best practices, data transformation or even data model/schema redesign may be required.
- Data volume and file format – The data volume and file format will impact the migration time, resulting in the selection of a more compact file format or the demand of a compression pre-processing requirement.
- Network connectivity – Based on the source and target network connectivity and latency, connectivity will also impact migration time and reliability, resulting in choosing a real-time or off-line data migration strategy.
- Tooling constraints – The availability of the tooling from the source, target, or even 3rd party sides will also impact the number of migration tasks and steps, or even the migration data quality.
- Skill sets – Depending on the migration personnel’s experience, skill may also influence the actual migration design and implementation.
- Production System Impacts – The requirements of production system downtime or impact during and post migration are also key factors in designing the migration solutions as well as the migration go-live strategy.
Example Migrations Illustration
In this section, we use a few migration examples to illustrate the typical migration steps involved in major migration paths of the GCP services outlined above.
Please note that these migration examples are for illustrative purposes and usually work for small data set with simple data models. For more complex data models and data size, there may be more processing steps involved, or even re-design of data schemas to be able to properly migrate the data. Also, specific command flag options may vary depending on the desired operational states. Please refer to the specific command references for your actual implementation.
BigQuery Data Migration Example
1. Create a GCP machine with CLI installed or use Google Cloud Shell.
2. Run BigQuery extract command to export dataset using the following example CLI scripts. Use the proper flags options that suit your source and targeted states and operations. Please visit this page for more details about BigQuery commands and options.

3. From the GCP instance or Cloud Shell, run the gsutil to copy the data from Google Cloud Storage to Amazon S3. Please refer to the gsutil tool for proper commands and flag options.

4. On AWS, depending on the migration targets, use the following steps, respectively:
a. Target: Amazon Redshift – the following highlights the key steps to create an Amazon Redshift cluster with data loading from an Amazon S3 bucket. You can find more details by following the getting started guide.
i. Provision the Amazon Redshift cluster.
ii. Create the target table.
iii. Run COPY command with source from the migration S3 bucket. For more details on how to COPY .avro data into Redshift cluster, see here.

iv. Vacuum and analyze the database.
v. Test and verify.
b. Target: Amazon Athena (Amazon S3) – The following are the steps required to convert file formats. For general steps to use AWS Glue to connect to data sources in Amazon S3, see here.
i. Use AWS Glue to convert the AVRO file format to Parquet format (more optimized data format for Amazon Athena). For format options for ETL input and outputs in AWS Glue, see details here.
ii. Use AWS Glue to crawl the transformed Parquet file to create the Athena table.
iii. Test and verify.
iv. An external reference for the migration from BigQuery to Amazon Athena can be found here.
c. Target: Amazon EMR (HIVE, Spark)
i. Download the source AVRO from Amazon S3 bucket to your local machine.
ii. Run Avro-tools command to extract the schema file from the source AVRO data file.

iii. Upload the schema file back to Amazon S3.

iv. Run HIVE CREATE TABLE command in the Amazon EMR cluster.

v. Test and verify with query.
vi. An external reference for the migration from BigQuery to Amazon EMR/Hive can be found here.
Bigtable Data Migration Example
The following outlines the approach and example steps to migrate from Bigtable to Amazon EMR Hbase:
1. Export Bigtable data as HBase Sequence Files into Cloud Storage.
a. Export HBase Sequence files from the tables page from Cloud Console.
b. Or use Dataflow with export template using HBase SequenceFiles: Cloud Bigtable to Cloud Storage SequenceFile.
2. From the GCP instance or cloud shell, run the gsutil tool to copy the data from Google Cloud Storage to target AWS S3 bucket as described in BigQuery migration step 3.
3. Provision the Amazon EMR cluster with HBase and other necessary packages included. See details here for creating an Hbase cluster.
4. Connect to HBase cluster to load the data using HBase shell.
5. Load the HBase Sequence file using HBase Importer Utility:

6. Verify and test.
Firebase Data Migration Example
1. Export data from Firebase data storage.
a. Firebase that uses older Realtime database -> export the data file to Local disk (JSON) – via Cloud Console, then migrate the file to Amazon S3 bucket. The following picture shows a screen shot of using the console to export the firebase data.

b. Firebase that uses the latest Firestore database will use a two-step process to export to a proprietary backup data format first (reference to firestore export commands here). Then, Import the data into BigQuery as an intermediate step (reference to the detailed commands here), and finally export out as AVRO format to Cloud Storage for migration to AWS .(reference to detailed commands here). The following example scripts illustrate the steps using the relevant commands.
2. From the GCP instance or cloud shell, run the gsutil to copy the data from Google Cloud Storage to target Amazon S3 bucket.
3. On AWS side, for illustration purpose, assume Amazon DynamoDB is the candidate target database to migrate to. Follow the steps below to migrate the firebase data into the DynamoDB table.
a. Download the JSON file from Amazon S3, and use the CLI command to load data:

b. Alternatively, you can use AWS Data Pipeline service to load JSON data from Amazon S3 bucket directly to Amazon DynamoDB as the following diagram shows. For more detailed information about using Amazon Data Pipeline to import and export data, you can find it here.
Conclusion
In this blog post, an overview of the typical migration paths for major GCP data analytics workloads moving to AWS is provided. Example migration steps for these workloads are also outlined. As mentioned, this post is not meant to be a complete detailed implementation guide for all use cases; rather, it provides a more systematic approach when it comes to solution the migrations of these GCP workloads to AWS. A thorough analysis of the source GCP workloads and a robust solution design for the target AWS architecture are still the keys to the ultimate success of the migrations. The post does center around getting the data across the boundary to the AWS side first. In addition, AWS does provide the most comprehensive toolsets and services to help migrate these GCP analytics workloads to the final desired architecture state. So feel free to initiate the conversations next time you hear that your customers are interested in moving from BigQuery or Bigtable to AWS. Get the data move first, and happy migration!
About the Author

Frank Wang is a Startup Senior Solutions Architect at AWS. He has worked with a wide range of customers with focus on Independent Software Vendors (ISVs) and now startups. He has several years of engineering leadership, software architecture, and IT enterprise architecture experiences and now focuses on helping customers through their cloud journey on AWS.