AWS Storage Blog
Accelerating backups with Amazon EBS direct APIs and Commvault
As a critical part of data protection and disaster recovery (DR) readiness, backing up data is an integral part of data storage in the cloud or otherwise. AWS customers use Amazon EBS snapshots, which are point-in-time backups of EBS volumes, as part of their data protection strategy in the cloud, often as part of their backup solution. When AWS released snapshots, customers could take snapshots of the EBS volumes attached to Amazon EC2 instances and restore those snapshots to other EBS volumes. However, they could not directly read the contents of those snapshots, or tell what changed between two snapshots. Customers desired the ability to do so, as it would make it faster and simpler for them to access data in snapshots and identify incremental changes in their backups.
In December 2019, AWS released Amazon EBS direct APIs, which provide a means to directly interact with Amazon EBS snapshots. EBS direct APIs are accessible via EBS direct API endpoints available in all 25 AWS Regions. This powerful feature allows customers to list, read, and quickly identify changes within a snapshot. A key use case for this is to improve backup performance for customers using partner solutions. It enabled partner solutions to identify data that they needed to protect, without having to read the entire contents of EBS volumes. One of the APN advanced tier and AWS Storage competency partners that AWS worked closely with to add direct API support was Commvault.
In this blog, I explore Commvault’s intelligent data management solution called Commvault Complete™ Data Protection. As part of this solution, Commvault has added support for Amazon EBS direct APIs. They are providing optimized backup outcomes to their customers that have enabled EBS direct APIs, reducing those customers’ backup time by up to 85% compared to before. This solution provides a feature-rich backup, recovery, and disaster recovery (DR) solution for AWS services. This enables customers to ensure they have comprehensive enterprise class data protection for all their stateful workloads running on AWS. It protects against accidental deletion, corruption, ransomware, and across geographies.
Commvault
Commvault has had a rich partnership with AWS since 2009, when they added Amazon S3 as a cloud backup destination. Commvault takes advantage of the latest AWS features as they are released, providing rapid value to its customers. For example, Commvault supports all six currently available Amazon S3 storage classes. Commvault has also been using Amazon EBS snapshots to provide agentless backups for Amazon EC2, Amazon RDS, and Amazon EKS instances for some time.
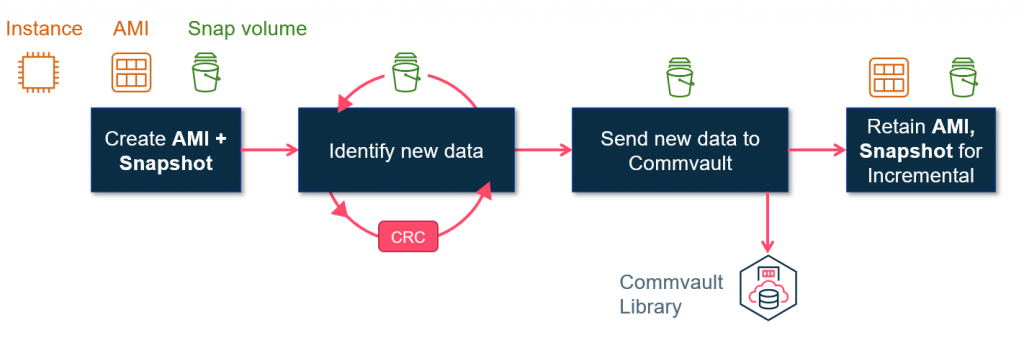
Previous (old) process for backing up Amazon EC2 instances
Let us look at a typical backup process without the new Amazon EBS direct APIs.
In order to perform agentless backups of Amazon EC2 instances, Commvault leverages Amazon EBS snapshots. When a backup initiates, Commvault calls the Amazon EC2 API to create a snapshot of the volumes attached to the instance. Amazon EBS io1 volumes are created from these snapshots and attached to an ephemeral access node to be read.
The entire volume must be read whether it is a new full backup or an incremental backup. Commvault calculates block-level cyclic redundancy checksums (CRC) to identify new or changed data. Any protected data is indexed into the Commvault database and any unique data blocks for the protected data are copied to the Commvault cloud storage location (that is, Amazon S3).
Current (new) process for backing up Amazon EC2 instances
While the existing process provides the benefit of being able to perform agentless backups, the process can take a long time to read and identify changes in a volume. Since there is no way to get details on what blocks are occupied, the entire disk must be read to identify data to protect. Combined with the requirement to initialize new EBS volumes (pre-warm) from Amazon S3, larger multi-TB volumes can take a significant amount of time. In order to optimize this process, it is necessary to find a way to quickly identify blocks that must be read.
This is exactly the role that the new Amazon EBS direct APIs provides. Starting with the ListSnapshotBlocks API. Even for a full backup, where it is necessary to back up all data on a volume, there can be many cases where large volumes are not fully populated. For example, a 2-TB volume can be attached to an Amazon EC2 instance but only 1 TB of data used on the volume. In the previous process, all 2 TB of blocks would need to be read. In the new process, the ListSnapshotBlocks API provides a list of just those blocks that are populated with data. This allows Commvault to call that API first and then just read the blocks required of the volume instead of all the blocks.
In addition, for incremental backups there were similar problems. First, in order for Commvault to do an incremental backup, changes would have to be identified between the old and new backup. This would require the snapshots to be created into volumes similar to full backups and all the data to be read and compared to the previous backed up data. This would significantly add time to the incremental process especially in cases were only a small amount of data changed. With the new process, the ListChangedBlocks API is used to immediately identify the blocks that have changed since the last snapshot, and then only those blocks must be read.
Now let us look at the second part of the process, which is reading the blocks. In the old process, this required an Amazon EBS volume to be created and mounted to an Amazon EC2 instance. While this process works well, it does have some limitations. For example, there is a limit on the number of EBS volumes that can be attached to a single instance, which may lead to more instances needing to be run, or a longer time to run instances. There is also a cost to running the instances and the volumes. The new GetSnapshotBlock API allows these blocks to be read directly from the EBS snapshots via API without requiring an EBS volume to be attached. This can be used in combination with the previously mentioned ListSnapshotBlocks. The ListSnapshotBlocks API identifies what blocks must be read and then the GetSnapshotBlock API is used to read those identified blocks.
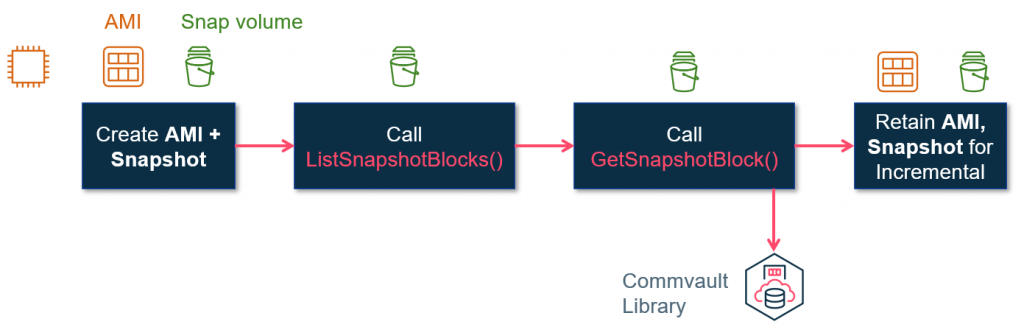
This capability is also extended to incremental backups, by allowing any new blocks to be identified between two EBS snapshots.

Configuration
Now let us look at how to enable this new functionality. This functionality was first introduced in Commvault version 11.20 (enabling or disabling changed block tracking – CBT – for backups). Existing customers must opt in for the new functionality by enabling CBT on existing Amazon EC2 virtual machine (VM) groups (see the upcoming screenshot).
New VM groups created from 11.20 will automatically enable this functionality to ensure that optimized backups occur. Amazon EBS direct read optimized backups are supported for all Commvault backup types, including:
- Streaming backup copies of EC2/EBS instances
- Snapshot backups and live browse of EC2/EBS instances
- Snapshot backup copies of EC2/EBS instances
- Cross-account backups
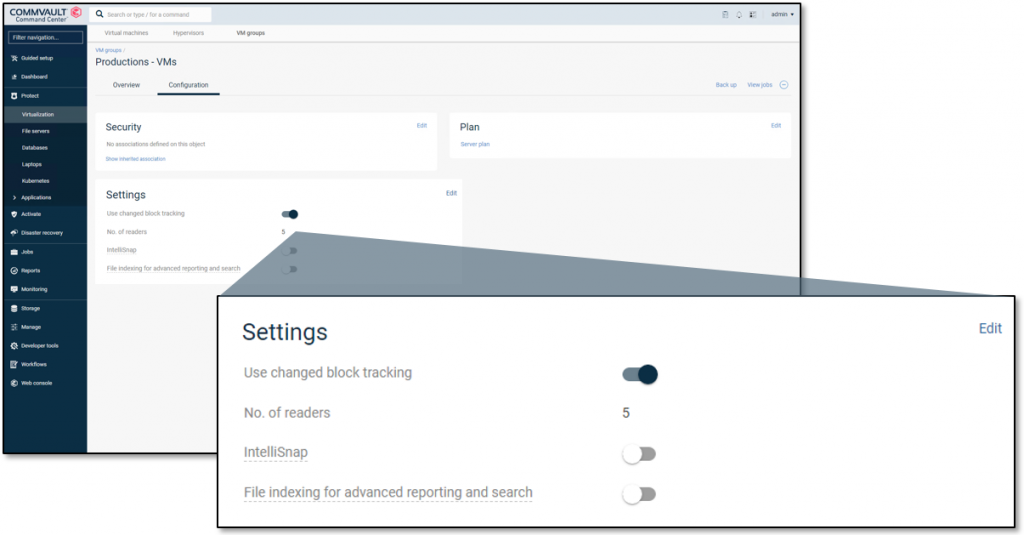
In addition to the Commvault configuration, you should enable a VPC endpoint for the Amazon EBS snapshot API before doing any backups. Enabling a VPC endpoint for the EBS direct APIs ensures that you can reach the APIs and read data within your VPC, which avoids using a NAT that could increase your networking cost.
Outcome
The impact of EBS direct APIs is significant, with a reduction in backup time of 85% observed within Commvault lab testing. Use of ebs:listSnapshotBlocks, ebs:ListChangedSnapshotBlocks, and ebs:GetSnapshotBlock effectively reduces backup time, removes temporary EC2 runtime cost and EBS volume costs.

* Commvault lab testing; your results may differ
Summary
In this blog, I have looked at the old and new processes for identifying data to be backed up on Amazon EC2 instances. By simply upgrading to a supported version and clicking a check box to enable this feature, you are able to get the benefit of faster backups. As seen in the test, a full backup can be reduced from 9 hours to 1.1 hours and an incremental can be reduced from 5 hours to 0.3 hours. This enables customers to use agentless backups on even large volumes and be able to meet their backup windows. Using this new functionality, customers can reduce their backup time by up to 85%, compared to not using the Amazon EBS direct APIs.
The new Amazon EBS direct snapshot APIs help make backup using Commvault on AWS even more efficient. By upgrading to version 11.20 (or later) customers can take advantage of this functionality for new or existing Amazon EC2 VM Groups.
To learn more about the EBS direct APIs for EBS snapshots, see the latest documentation. To learn more about how Commvault and AWS work together including customer case studies see the Commvault AWS site.
Thanks for reading this blog post on accelerating backups with Amazon EBS direct APIs and Commvault. If you have any comments or questions, please don’t hesitate to leave them in the comments section.