AWS Storage Blog
Extending Java applications to directly access files in Amazon S3 without recompiling
The Java programming language has been among the most used languages in software development for many years, and a vast number of Java applications exist today. Almost all applications interact with files in some way, yet most of these have been written to interact with a file system based on block storage and cannot directly read or write files located in an object store. Given the industry-leading scalability, data availability, security, and performance of Amazon Simple Storage Service (S3), there is a natural desire to use this as a storage medium.
With the 2011 release of Java 7, a Service Provider Interface (SPI) was introduced that allowed applications using the New Input/Output (NIO.2) model to interface with alternative data providers. This allowed Java programs to be agnostic to the actual source of data and delegate “file system” operations to the SPI. Because the Java Virtual Machine (JVM) will detect and use any SPIs on its classpath, it is usually not necessary to modify the Java application in any way.
Building off the SPI, I developed the aws-nio-spi-for-s3 package, a light-weight open-source Java NIO.2 SPI compliant implementation for Amazon S3. This allows Java applications to directly access Amazon S3 object storage without modifying or recompiling Java applications and without any need to stage S3 objects to local storage.
In this post, I introduce the benefits of the aws-nio-spi-for-s3 package, design decisions and implementation, and how it can be employed with java-based applications without any requirement to modify code or recompile the application. By allowing direct interaction between Java applications and Amazon S3, it becomes much simpler to realize the cost, scale, performance, and durability benefits of moving files into Amazon S3.
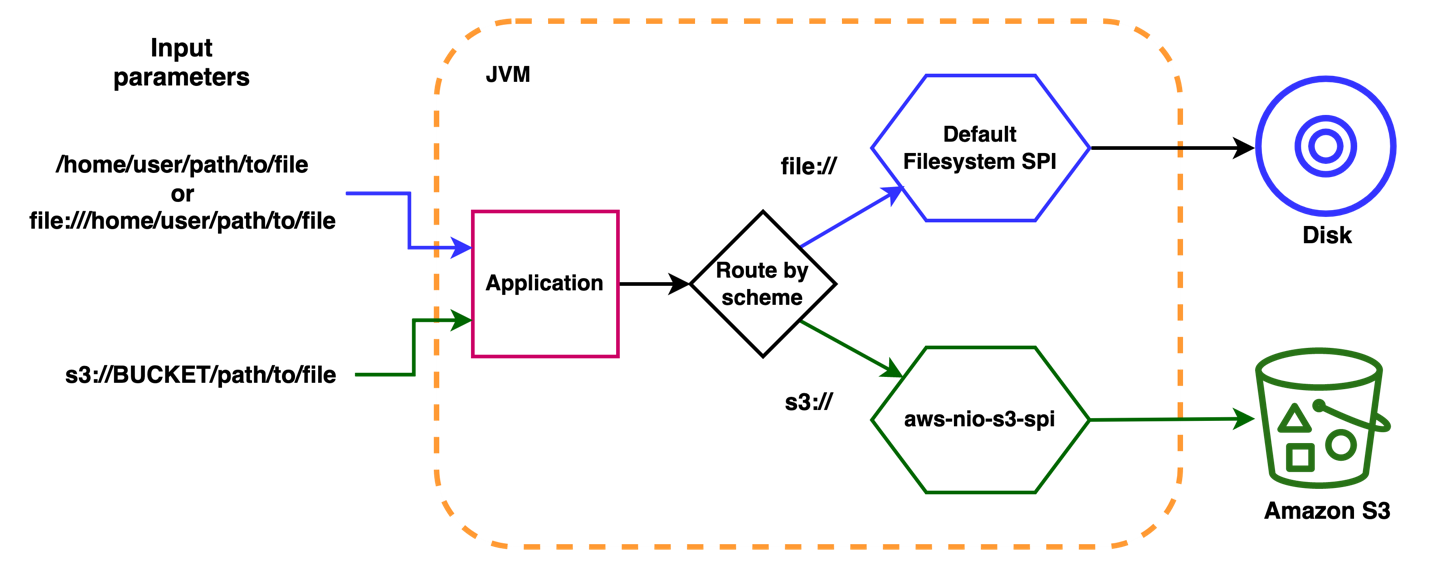
How it works
The SPI implementation registers itself with the JVM as a provider for URIs from the “s3” scheme. For example, if an application input is s3://some-bucket/input/file, then the JVM transparently delegates I/O operations to that library.
Bytes from S3 objects can be read using an S3SeekableByteChannel, which is an implementation of java.nio.channel.SeekableByteChannel. The S3SeekableByteChannel uses an in-memory read-ahead cache of ByteBuffers and is optimized for the scenario where bytes are generally read sequentially.
Writing to Amazon S3 is also supported. However, all write operations are gathered in a temporary file, which is uploaded to Amazon S3 upon closing the I/O channel.
Design decisions and implementation
As Amazon S3 is an object store and not a file system, I faced numerous important design decisions regarding how key Java file system interfaces could be mapped to Amazon S3 concepts. For example, an S3 bucket is represented as a java.nio.spi.FileSystem implemented by the software.amazon.nio.spi.s3.S3FileSystem class. One alternative was to represent all of Amazon S3 as a single FileSystem with buckets being top level folders. Although an S3 bucket name is globally unique, and the namespace is shared by all AWS accounts, they are owned by individual accounts, have their own permissions, Region, and potentially endpoints. All of this would have added additional complexity. Therefore, an S3 bucket seemed like the closest analog of the FileSystem interface.
Another important design decision was how to represent files and directories. Files (Paths in Java NIO.2) are relatively direct analogs of S3 objects. Yet directories are more complex. Amazon S3 doesn’t have directories, there are only buckets and keys. For example, in s3://mybucket/path/to/file/object the bucket name is mybucket and the key would be /path/to/file/object. By convention, the use of / in a key is thought of as a path separator. Therefore, object could be inferred to be a file in a directory called /path/to/file/ even though that directory does not exist. The aws-nio-spi-for-s3 package infers directories under what I call “POSIX-like” path representations. The logic of these is encoded in the project’s PosixLikePathRepresentation object. I refer to this as “POSIX-like”, because a perfect representation isn’t possible. For example, an Amazon S3 path is inferred to be a directory if the path ends with /, /. or /.. or contains only . or ... Therefore, these paths are inferred to be directories /dir/, /dir/., /dir/... However, dir and /dir cannot be inferred to be a directory. This is because Amazon S3 holds no metadata that can be used to make this inference and either could be a file. This is a divergence from a true POSIX filesystem where, if /dir/ is a directory, then /dir and dir relative to / must also be a directory.
Several other decisions, such as handling of hidden files, symbolic links, and timestamps, were also made. A full description is in the README file of the project.
Example use case: Genomics data
Large files stored in Amazon S3 are the norm for genomics research and development. There are popular Java applications dedicated to the analysis of this data, like the Genome Analysis Toolkit (GATK) from the Broad Institute, which encompasses more than 100 java applications. The majority of these use Java NIO.2 for file operations. Many genomics applications are I/O intensive, process files in their entirety, and can naturally be deployed as multiple independent processes that operate on different chunks, or intervals, of the source data. The high elastic throughput of Amazon S3, combined with the properties of the aws-nio-spi-for-s3 package described here, provide an ideal solution in these situations.
The aws-nio-spi-for-s3 package as a “drop in” provider
The simplest way to use the package is to include the package’s JAR file on the class path of a Java application. As a concrete example, by using the popular genomics application GATK, you could do the following:
java -classpath nio-spi-for-s3-1.2.1-all.jar:gatk-package-4.2.2.0-local.jar \ org.broadinstitute.hellbender.Main \ CountReads -I s3://EXAMPLE_BUCKET/example-genome.hg38.bam
Because the supplied input argument (-I) is an Amazon S3 URI and the provider jar is on the classpath of the JVM (nio-spi-for-s3-1.2.1-all.jar), GATK reads the input from Amazon S3 as if it were reading from a local filesystem. The same approach can be used by any Java application that utilizes Java NIO.2 for file operations. Other possible methods for using the package are described in the application’s README.
Security
The aws-nio-spi-for-s3 uses the AWS Java SDK v2, and naturally utilizes the AWS SDK credential chain. Any Java application using the package automatically adopts your configured AWS credentials. Likewise, if the application is run on an Amazon Elastic Compute Cloud (Amazon EC2) instance, permissions provided by the Amazon EC2’s AWS Identity and Access Management (IAM) instance profile are used. For containerized applications in Amazon Elastic Container Service (Amazon ECS) or Elastic Container Service for Kubernetes clusters, the configured service permissions are used. Most importantly, there is no requirement to provide any permanent credentials or embed credentials in configuration files. All interactions with Amazon S3 by the Java application are governed by IAM.
Benefits
The aws-nio-spi-for-s3 package works with any application using Java NIO.2 libraries, which have been the recommended default since July 2011. The package is automatically used by the JVM when it is found on the classpath. No modification or recompilation of an application is required.
Inputs and outputs that were previously supplied to an application as local file paths or file:// URIs can now be supplied as s3:// URIs. Moreover, the aws-nio-spi-for-s3 package automatically handles file operations on those URIs. Both local files and S3 objects can be used together in the same application simultaneously, so that a gradual migration of potential application inputs to Amazon S3 is possible.
When an application runs in a JVM using the aws-nio-spi-for-s3 package, computation can begin as soon as the first bytes are read. There is no need to wait for a file to be copied to disk, thereby avoiding potentially large copy times. Unlike other solutions, there is no need to localize S3 objects to local or mounted storage, which removes the cost of the additional infrastructure and the need to develop solutions to synchronize local and Amazon S3 files.
By avoiding the need for specialized FUSE mount software, we remove the need for additional configuration, mount point creation and background daemon processes which generally require root privileges to deploy and run.
Get started today
In this post, I discussed the nio-spi-for-s3 package, which provides a very light-weight solution for when you want to have an existing Java application read from or write to Amazon S3 without the need to provision additional infrastructure or drivers, or to marshal files to local storage. Using the package, you can easily benefit from the features of Amazon S3 without needing to modify your existing applications.
You can download a jar file with all the required dependencies, or you can build from the source hosted on GitHub. The source code is made available under the Apache 2.0 license. Community participation, including feature requests, bug reports, and code contributions, is very welcome. Why not test the package today with your favorite Java application?