AWS Big Data Blog
Introducing the vector engine for Amazon OpenSearch Serverless, now in preview
We are pleased to announce the preview release of the vector engine for Amazon OpenSearch Serverless. The vector engine provides a simple, scalable, and high-performing similarity search capability in Amazon OpenSearch Serverless that makes it easy for you to build modern machine learning (ML) augmented search experiences and generative artificial intelligence (AI) applications without having to manage the underlying vector database infrastructure. This post summarizes the features and functionalities of our vector engine.
Using augmented ML search and generative AI with vector embeddings
Organizations across all verticals are rapidly adopting generative AI for its ability to handle vast datasets, generate automated content, and provide interactive, human-like responses. Customers are exploring ways to transform the end-user experience and interaction with their digital platform by integrating advanced conversational generative AI applications such as chatbots, question and answer systems, and personalized recommendations. These conversational applications enable you to search and query in natural language and generate responses that closely resemble human-like responses by accounting for the semantic meaning, user intent, and query context.
ML-augmented search applications and generative AI applications use vector embeddings, which are numerical representations of text, image, audio, and video data to generate dynamic and relevant content. The vector embeddings are trained on your private data and represent the semantic and contextual attributes of the information. Ideally, these embeddings can be stored and managed close to your domain-specific datasets, such as within your existing search engine or database. This enables you to process a user’s query to find the closest vectors and combine them with additional metadata without relying on external data sources or additional application code to integrate the results. Customers want a vector database option that is simple to build on and enables them to move quickly from prototyping to production so they can focus on creating differentiated applications. The vector engine for OpenSearch Serverless extends OpenSearch’s search capabilities by enabling you to store, search, and retrieve billions of vector embeddings in real time and perform accurate similarity matching and semantic searches without having to think about the underlying infrastructure.
Exploring the vector engine’s capabilities
Built on OpenSearch Serverless, the vector engine inherits and benefits from its robust architecture. With the vector engine, you don’t have to worry about sizing, tuning, and scaling the backend infrastructure. The vector engine automatically adjusts resources by adapting to changing workload patterns and demand to provide consistently fast performance and scale. As the number of vectors grows from a few thousand during prototyping to hundreds of millions and beyond in production, the vector engine will scale seamlessly, without the need for reindexing or reloading your data to scale your infrastructure. Additionally, the vector engine has separate compute for indexing and search workloads, so you can seamlessly ingest, update, and delete vectors in real time while ensuring that the query performance your users experience remains unaffected. All the data is persisted in Amazon Simple Storage Service (Amazon S3), so you get the same data durability guarantees as Amazon S3 (eleven nines). Even though we are still in preview, the vector engine is designed for production workloads with redundancy for Availability Zone outages and infrastructure failures.
The vector engine for OpenSearch Serverless is powered by the k-nearest neighbor (kNN) search feature in the open-source OpenSearch Project, proven to deliver reliable and precise results. Many customers today are using OpenSearch kNN search in managed clusters for offering semantic search and personalization in their applications. With the vector engine, you can get the same functionality with the simplicity of a serverless environment. The vector engine supports the popular distance metrics such as Euclidean, cosine similarity, and dot product, and can accommodate 16,000 dimensions, making it well-suited to support a wide range of foundational and other AI/ML models. You can also store diverse fields with various data types such as numeric, boolean, date, keyword, geopoint for metadata, and text for descriptive information to add more context to the stored vectors. Colocating the data types reduces the complexity and maintainability and avoids data duplication, version compatibility challenges, and licensing issues, effectively simplifying your application stack. Because the vector engine supports the same OpenSearch open-source suite APIs, you can take advantage of its rich query capabilities, such as full text search, advanced filtering, aggregations, geo-spatial query, nested queries for faster retrieval of data, and enhanced search results. For example, if your use case requires you to find the results within 15 miles of the requestor, the vector engine can do this in a single query, eliminating the need for maintaining two different systems and then combining the results through application logic. With support for integration with LangChain, Amazon Bedrock, and Amazon SageMaker, you can easily integrate your preferred ML and AI system with the vector engine.
The vector engine supports a wide range of use cases across various domains, including image search, document search, music retrieval, product recommendation, video search, location-based search, fraud detection, and anomaly detection. We also anticipate a growing trend for hybrid searches that combine lexical search methods with advanced ML and generative AI capabilities. For example, when a user searches for a “red shirt” on your e-commerce website, semantic search helps expand the scope by retrieving all shades of red, while preserving the tuning and boosting logic implemented on the lexical (BM25) search. With OpenSearch filtering, you can further enhance the relevance of your search results by providing users with options to refine their search based on size, brand, price range, and availability in nearby stores, allowing for a more personalized and precise experience. The hybrid search support in the vector engine enables you to query vector embeddings, metadata, and descriptive information within a single query call, making it easy to provide more accurate and contextually relevant search results without building complex application code.
You can get started in minutes with the vector engine by creating a specialized vector search collection under OpenSearch Serverless using the AWS Management Console, AWS Command Line Interface (AWS CLI), or the AWS software development kit (AWS SDK). Collections are a logical grouping of indexed data that works together to support a workload, while the physical resources are automatically managed in the backend. You don’t have to declare how much compute or storage is needed or monitor the system to make sure it’s running well. OpenSearch Serverless applies different sharding and indexing strategies for the three available collection types: time series, search, and vector search. The vector engine’s compute capacity used for data ingestion, and search and query are measured in OpenSearch Compute Units (OCUs). One OCU can handle 4 million vectors for 128 dimensions or 500K for 768 dimensions at 99% recall rate. The vector engine is built on OpenSearch Serverless, which is a highly available service and requires a minimum of 4 OCUs (two OCUs for the ingest including primary and standby, and two OCUs for the search with two active replicas across Availability Zones) for that first collection in an account. All subsequent collections using the same AWS Key Management Service (AWS KMS) key can share those OCUs.
Get started with vector embeddings
To get started using vector embeddings using the console, complete the following steps:
- Create a new collection on the OpenSearch Serverless console.
- Provide a name and optional description.
- Currently, vector embeddings are supported exclusively by vector search collections; therefore, for Collection type, select Vector search.

- Next, you must configure the security policies, which includes encryption, network, and data access policies.
We are introducing the new Easy create option, which streamlines the security configuration for faster onboarding. All the data in the vector engine is encrypted in transit and at rest by default. You can choose to bring your own encryption key or use the one provided by the service that is dedicated for your collection or account. You can choose to host your collection on a public endpoint or within a VPC. The vector engine supports fine-grained AWS Identity and Access Management (IAM) permissions so that you can define who can create, update, and delete encryption, network, collections, and indexes, thereby enabling organizational alignment.
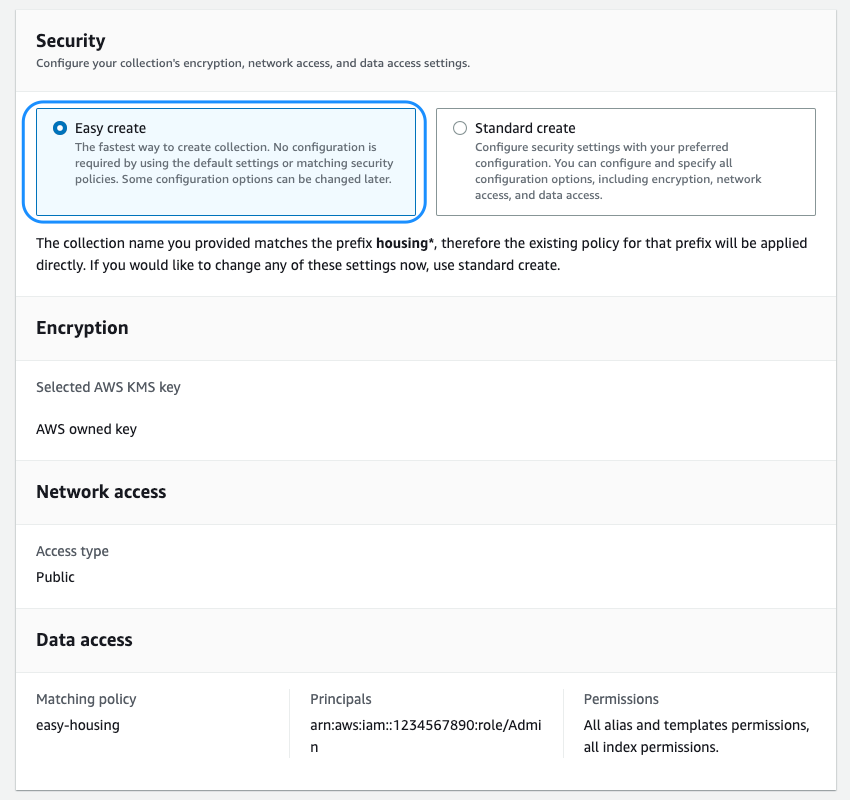
- With the security settings in place, you can finish creating the collection.
After the collection is successfully created, you can create the vector index. At this point, you can use the API or the console to create an index. An index is a collection of documents with a common data schema and provides a way for you to store, search, and retrieve your vector embeddings and other fields. The vector index supports up to 1,000 fields.
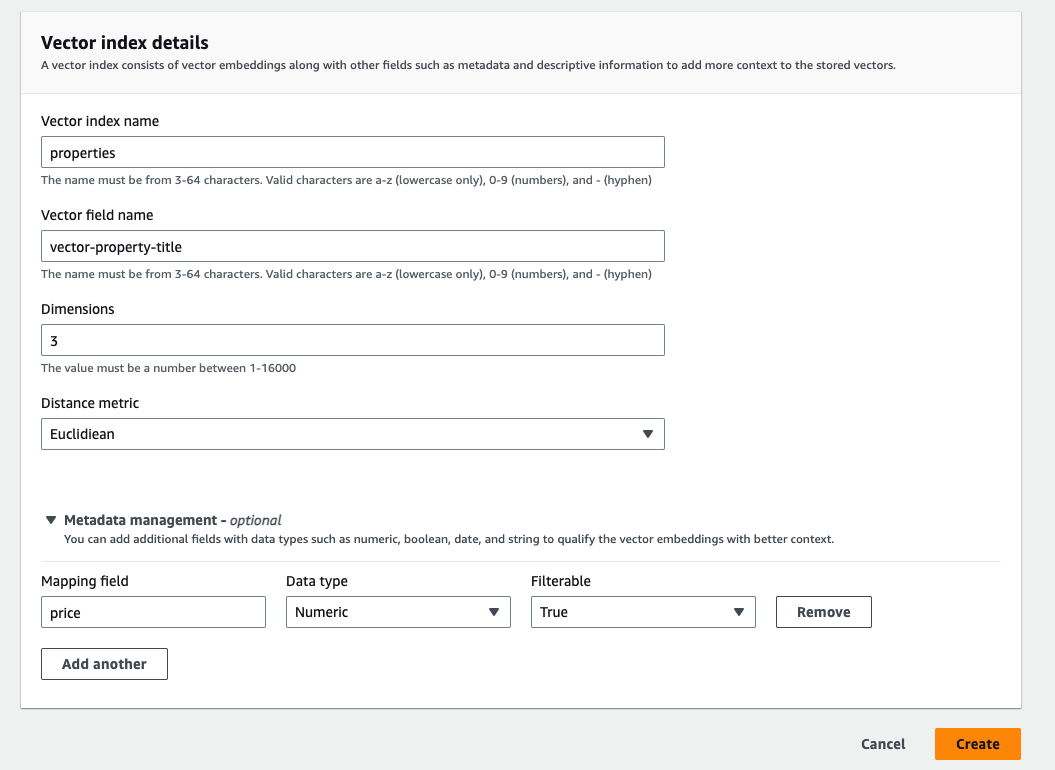
- To create the vector index, you must define the vector field name, dimensions, and the distance metric.
The vector index supports up to 16,000 dimensions and three types of distance metrics: Euclidean, cosine, and dot product.
Once you have successfully created the index, you can use OpenSearch’s powerful query capabilities to get comprehensive search results.
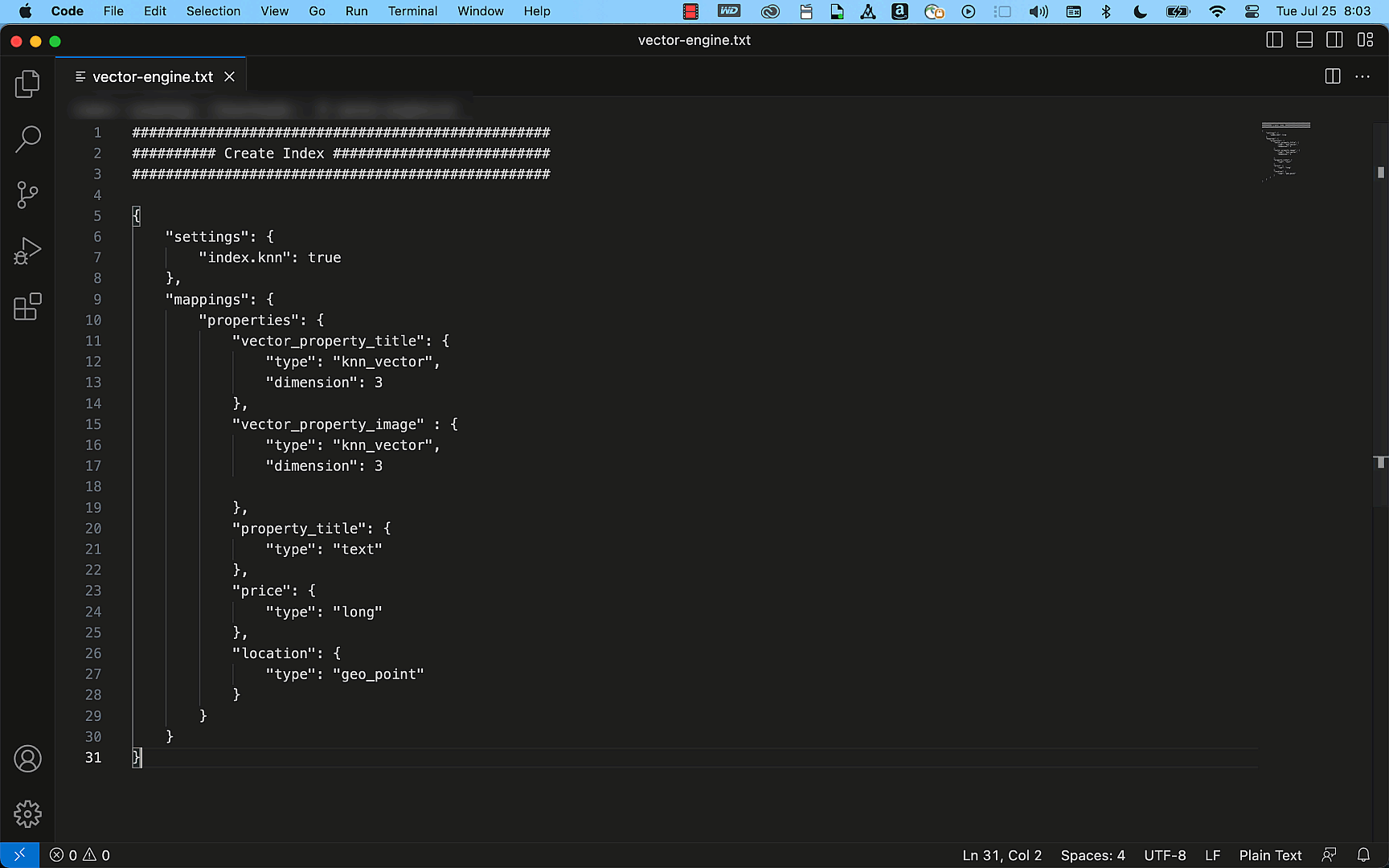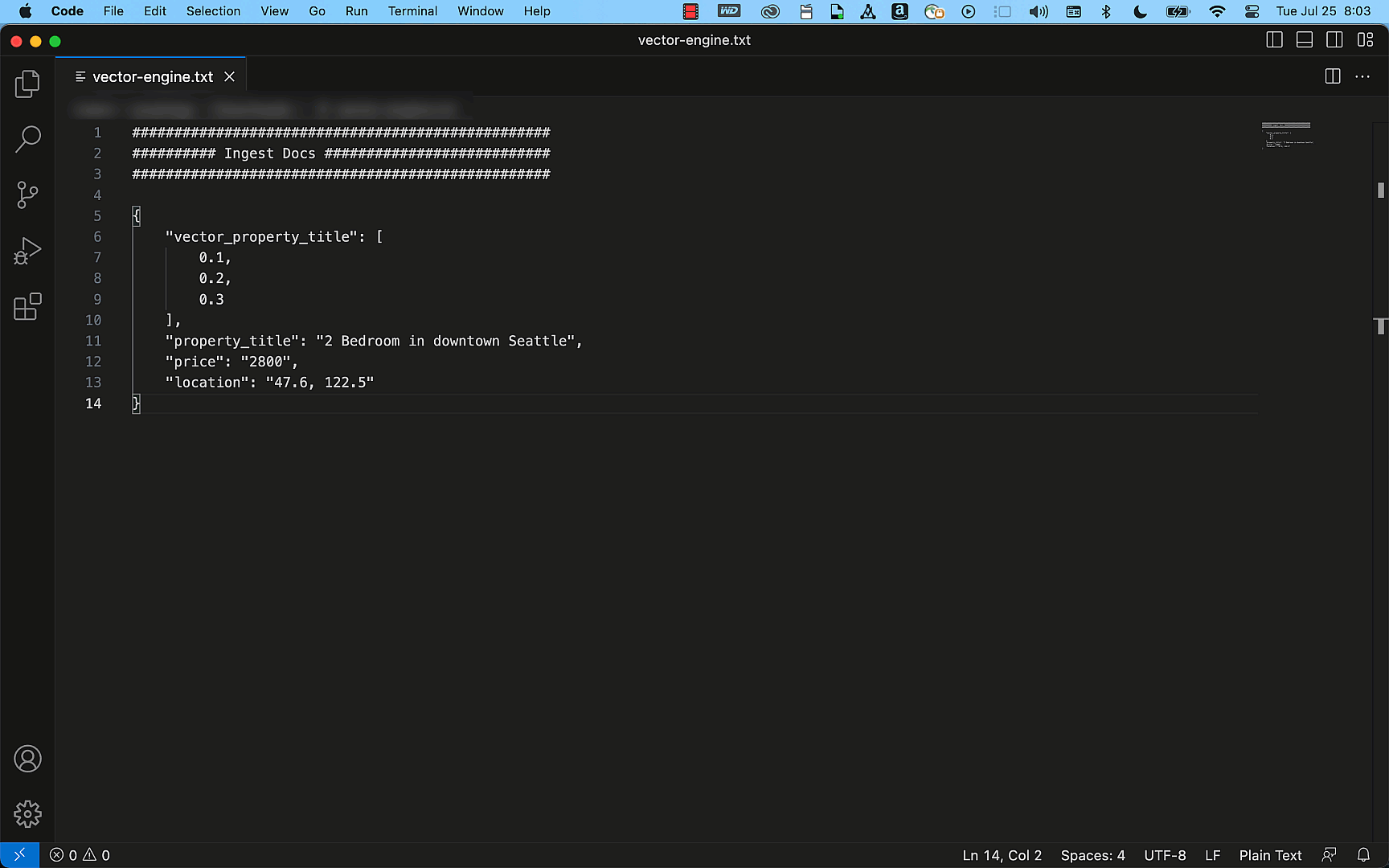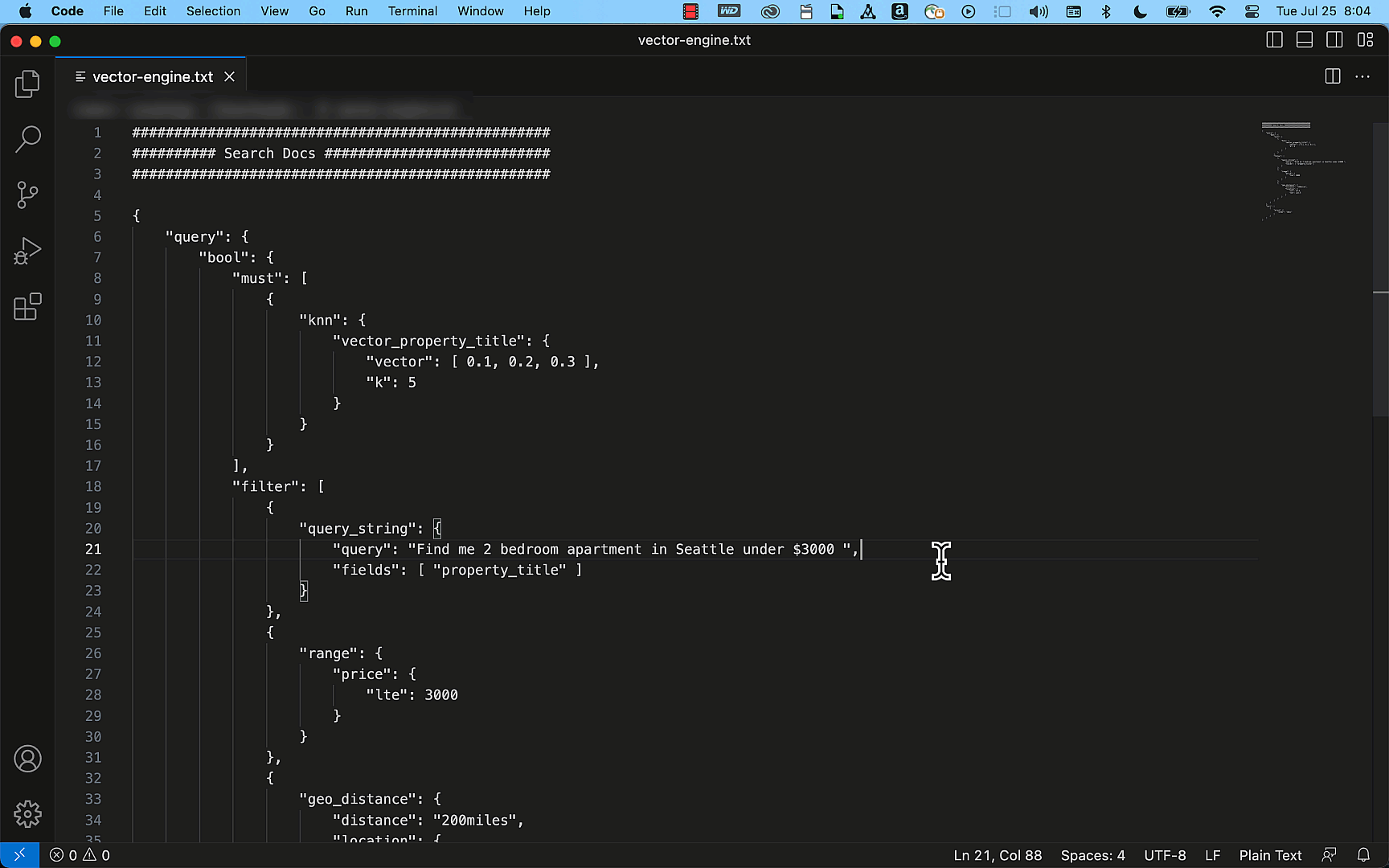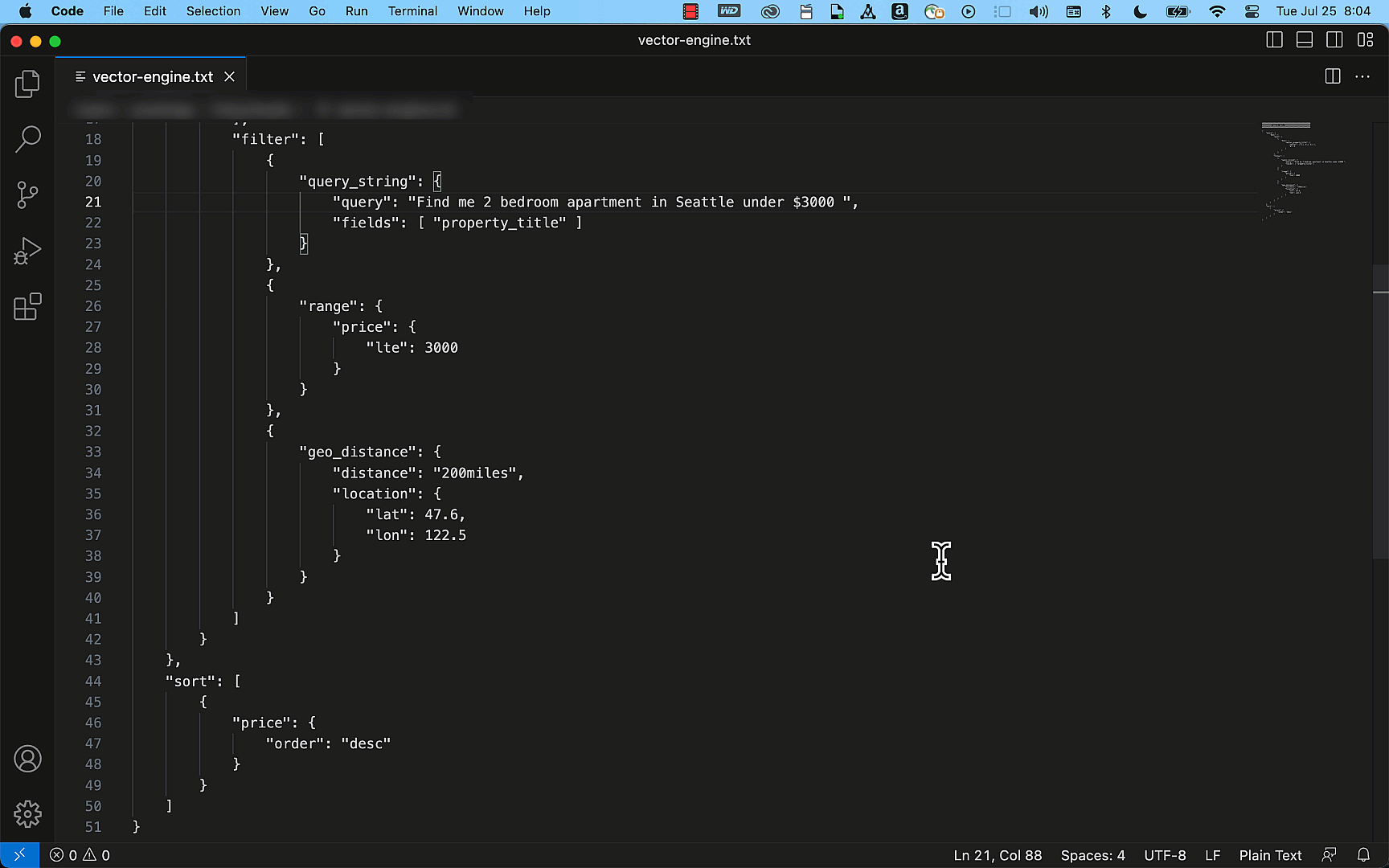
The following example shows how easily you can create a simple property listing index with the title, description, price, and location details as fields using the OpenSearch API. By using the query APIs, this index can efficiently provide accurate results to match your search requests, such as “Find me a two-bedroom apartment in Seattle that is under $3000.”
From preview to GA and beyond
Today, we are excited to announce the preview of the vector engine, making it available for you to begin testing it out immediately. As we noted earlier, OpenSearch Serverless was designed to provide a highly available service to power your enterprise applications, with independent compute resources for index and search and built-in redundancy.
We recognize that many of you are in the experimentation phase and would like a more economical option for dev-test. Prior to GA, we plan to offer two features that will enable us to reduce the cost of your first collection. The first is a new dev-test option that enables you to launch a collection with no active standby or replica, reducing the entry cost by 50%. The vector engine still provides durability guarantees because it persists all the data in Amazon S3. The second is to initially provision a 0.5 OCU footprint, which will scale up as needed to support your workload, further lowering costs if your initial workload is in the tens of thousands to low-hundreds of thousands of vectors (depending on the number of dimensions). Between these two features, we will reduce the minimum OCUs needed to power your first collection from 4 OCUs down to 1 OCU per hour.
We are also working on features that will allow us to achieve workload pause and resume capabilities in the coming months, which is particularly useful for the vector engine because many of these use cases don’t require continuous indexing of the data.
Lastly, we are diligently focused on optimizing the performance and memory usage of the vector graphs, including improving caching, merging and more.
While we work on these cost reductions, we will be offering the first 1400 OCU-hours per month free on vector collections until the dev-test option is made available. This will enable you to test the vector engine preview for up to two weeks every month at no cost, based on your workload.
Summary
The vector engine for OpenSearch Serverless introduces a simple, scalable, and high-performing vector storage and search capability that makes it straightforward for you to quickly store and query billions of vector embeddings generated from a variety of ML models, such as those provided by Amazon Bedrock, with response times in milliseconds.
The preview release of vector engine for OpenSearch Serverless is now available in eight Regions globally: US East (Ohio), US East (N. Virginia), US West (Oregon), Asia Pacific (Singapore), Asia Pacific (Sydney), Asia Pacific (Tokyo), Europe (Frankfurt), and Europe (Ireland).
We are the excited about the future ahead and your feedback will play a vital role in guiding the progress of this product. We encourage you to try out the vector engine for OpenSearch Serverless and share your use cases, questions, and feedback in the comments section.
In the coming weeks, we will be publishing a series of posts to provide you with detailed guidance on how to integrate the vector engine with LangChain, Amazon Bedrock, and SageMaker. To learn more about the vector engine’s capabilities, refer to our Getting Started with Amazon OpenSearch Serverless documentation
About the authors
 Pavani Baddepudi is a Principal Product Manager for Search Services at AWS and the lead PM for OpenSearch Serverless. Her interests include distributed systems, networking, and security. When not working, she enjoys hiking and exploring new cuisines.
Pavani Baddepudi is a Principal Product Manager for Search Services at AWS and the lead PM for OpenSearch Serverless. Her interests include distributed systems, networking, and security. When not working, she enjoys hiking and exploring new cuisines.
 Carl Meadows is Director of Product Management at AWS and is responsible for Amazon Elasticsearch Service, OpenSearch, Open Distro for Elasticsearch, and Amazon CloudSearch. Carl has been with Amazon Elasticsearch Service since before it was launched in 2015. He has a long history of working in the enterprise software and cloud services spaces. When not working, Carl enjoys making and recording music.
Carl Meadows is Director of Product Management at AWS and is responsible for Amazon Elasticsearch Service, OpenSearch, Open Distro for Elasticsearch, and Amazon CloudSearch. Carl has been with Amazon Elasticsearch Service since before it was launched in 2015. He has a long history of working in the enterprise software and cloud services spaces. When not working, Carl enjoys making and recording music.