AWS Database Blog
Amazon DynamoDB can now import Amazon S3 data into a new table
Today we’re launching new functionality that makes it easier for you to import data from Amazon Simple Storage Service (Amazon S3) into new DynamoDB tables. This is a fully managed feature that doesn’t require writing code or managing infrastructure. In this post, we introduce DynamoDB import from S3 and show you how to use it to perform a bulk import.
Overview
Before DynamoDB import from S3, you had limited options for bulk importing data into DynamoDB. Extract, transform, load (ETL) tools and migration tools designed for traditional schemas are available but might not be straightforward for a variety of NoSQL patterns, including single table design and document storage. Bulk importing data can require a custom data loader, which takes resources to build and operate. Loading terabytes of data can take days or weeks unless the solution is multi-threaded and deployed across a fleet of virtual instances, such as an Amazon EMR cluster. Capacity decisions, job monitoring, and exception handling add complexity to a solution that you may only run once. If you need to perform a DBA task such as cross-account table migration, you could use the DynamoDB table export to Amazon S3 feature, but you would also need to build custom table loading routines to import the data back to a new DynamoDB table.
DynamoDB import from S3 helps you to bulk import terabytes of data from Amazon S3 into a new DynamoDB table with no code or servers required. Combined with the table export to S3 feature, you can now more easily move, transform, and copy your DynamoDB tables from one application, account, or AWS Region to another. Legacy application data staged in CSV, DynamoDB JSON, or ION format can be imported to DynamoDB, accelerating cloud application migrations. Imports can be initiated from the AWS Management Console, the AWS Command Line Interface (AWS CLI), or using the AWS SDK.
DynamoDB import from S3 doesn’t consume any write capacity, so you don’t need to provision extra capacity when defining the new table. You only specify the final table settings you want, including capacity mode and capacity units, if using provisioned capacity mode.
During the import, DynamoDB might encounter errors while parsing your data. For each error, DynamoDB creates a log entry in Amazon CloudWatch Logs and keeps a count of the total number of errors encountered. If that count exceeds a threshold of 10,000, the logging will cease but the import will continue. Therefore, it’s recommended you test your import with a small dataset first to ensure it can run without errors. The data in your S3 bucket must be in either CSV, DynamoDB JSON, or ION format, with GZIP or ZSTD compression, or no compression. Each record must also include a partition key value, and a sort key if the table is configured with one, to match the key schema of the target table. You must also choose the appropriate data type for the keys, either string, number, or binary.
Import data from S3 to DynamoDB
Now that you know the basics of DynamoDB import from S3, let’s use it to move data from Amazon S3 to a new DynamoDB table. You can download and deploy a set of sample JSON files into your S3 bucket to get started. For this walkthrough, let’s assume you staged these uncompressed DynamoDB JSON data files in an S3 bucket called s3-import-demo in the folder path /demo, as shown in Figure 1 that follows.

Figure 1 –S3 bucket contents
The data records each contain a PK and SK attribute intended for a table with a partition key called PK and a sort key called SK. You need to enter the matching key names during the import process to define the key schema for your new table. The following snippet shows a few sample records in the DynamoDB JSON format.
Notice that the first JSON record has both the PK and SK key attributes, whereas the second record misses the PK attribute. Due to the missing key schema attribute PK, the second record will cause an error during the import. For the purpose of this demonstration, two errored records are intentionally included in the sample data, one with a missing PK attribute and another with a missing SK attribute.
To import data from S3 to DynamoDB
- Log in to the console and navigate to the DynamoDB service. Choose Imports from S3 in the navigation pane.

Figure 2 – Choose Imports from S3
- The Imports from S3 page lists information about any existing or recent import jobs that have been created. Choose Import from S3 to move to the Import options page.

Figure 3 – List of imports from S3
- On the Import options page:
- In S3 URL, enter the path to the source S3 bucket and any folder in URI format, for example
s3://s3-import-demo/demo - Select This AWS account as the bucket owner
- Verify that the remaining fields are set at the defaults:
Import file format: DynamoDB JSON
Import file compression: None - Choose Next

Figure 4 – Import options for the S3 bucket
- In S3 URL, enter the path to the source S3 bucket and any folder in URI format, for example
- On Destination table – new table
- In Table name, enter a name for your new table.
- In the Partition key, enter PK as the name and select String as the type.
- For this example, our data includes a sort key. In the Sort key box, define the sort key by entering SK as the sort key name and selecting String as the datatype.
- In Settings, verify that Default settings are selected and choose Next. This creates a table with provisioned capacity of 5 read capacity units (RCU) and 5 write capacity units (WCU). However, the import doesn’t consume your table’s capacity and doesn’t depend on these settings.
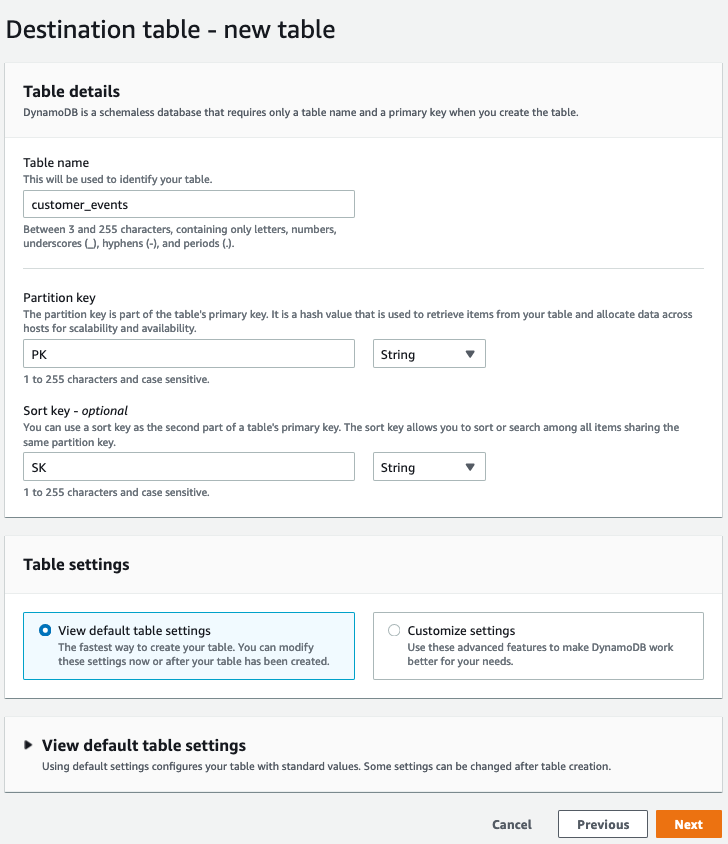
Figure 5 – Destination table – new table
- Confirm the choices and settings are correct and choose Import to begin your import.
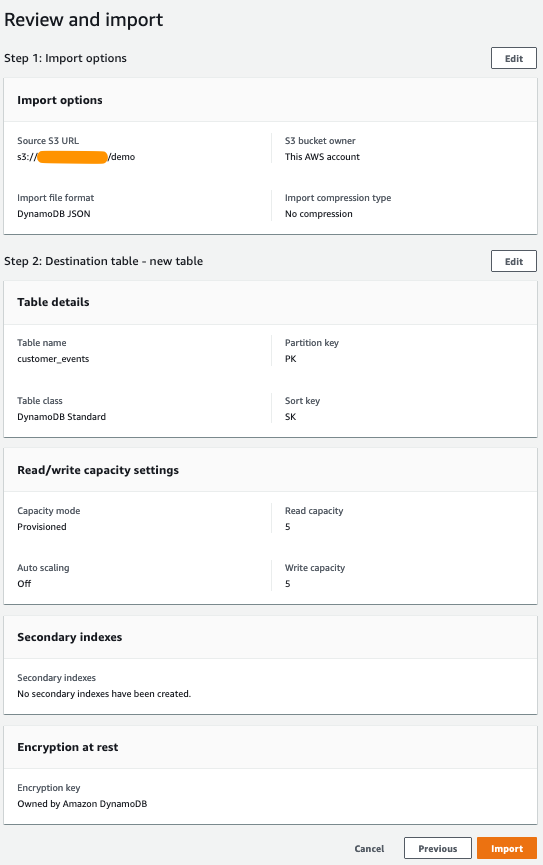
Figure 6 – Review and import
- The import will take a few moments. You can track the status of your import on the Imports from S3 page. Wait for the status of the import job to change from Importing to Complete before continuing.
Check the results of the import
For each import job, DynamoDB logs an initial /info log stream in CloudWatch. This log stream indicates the start of the import and ensures that sufficient permissions exist to continue logging. If sufficient permissions do not exist, the import job fails immediately.
Figure 7 that follows shows an example of log streams in CloudWatch.

Figure 7 – CloudWatch error log group
Individual records that cause an error are logged (up to 10,000 in total error count), along with error metadata such as the record number within the S3 object and the error message.

Figure 8 – CloudWatch error logs for DynamoDB Import from S3
As shown in the preceding Figure 8, one of the two intentionally put error records is missing the PK attribute, and the other is missing the SK attribute. DynamoDB requires both these attributes as they are the partition key and sort key of the new table, and so DynamoDB can’t import either record into the table.
As mentioned earlier, if the error count exceeds 10,000, DynamoDB would cease logging errors but continue importing the remaining source data. Please see the full details on troubleshooting errors in Validation errors section in the Developer Guide. It is not possible to access data in the table while the table status is CREATING which in this context indicates the import being in progress.
Operating considerations
The service will attempt to process all S3 objects that match the specified source prefix.
The S3 bucket doesn’t have to be in the same Region as the target DynamoDB table.
If you’re importing files created previously by the DynamoDB table export to S3 feature, you must provide the path to the data folder. The manifest files included in a parent folder aren’t used. Here is an example S3 path: s3://my-bucket/AWSDynamoDB/01636728158007-9c06f1a9/data
For importing data across AWS accounts, you need to make sure the requester of the import has permissions to list and get data from the source S3 bucket. The S3 bucket policies also need to allow the requester access.
As an import job runs, many parallel processes read objects from S3 and load the table. You won’t consume any traditional write units nor have to worry about throttling during the import process. The time required to perform an import can vary from a few minutes to several hours, depending mainly on the size of your source data and the distribution of keys in the source data. Highly skewed key distribution in source data will likely import slower than data with well distributed keys.
Common errors you might encounter include syntax errors, formatting problems, and records without the required primary key. Information about errors is logged in CloudWatch logs for further investigation.
Much like the regular process to define a new DynamoDB table, you can choose to create secondary indexes to support additional access patterns for the application. Defining a secondary index during data load will cause the index to be filled during the import, saving time and cost compared with creating a new secondary index after the table is live and consuming write capacity units.
Note: The import process can only load data into a brand-new table that is created during the import process.
Cost considerations
The cost of running an import is based on the uncompressed size of the source data in S3, multiplied by a per-GB cost, which is $0.15 per GB in the US East (Northern Virginia) Region. Tables with one or more global secondary indexes (GSIs) defined incur no additional cost, but the size of any failed records adds to the total cost.
If you currently use DynamoDB on-demand backup and have experience restoring tables, you’ll find the cost and performance of the new S3 import feature is comparable.
The total cost to load data using the S3 import feature is significantly less than the normal write costs for loading data into DynamoDB yourself using non-native solutions, as shown in a sample scenario with cost breakdowns shown here.
| Items to load | 100,000,000 |
| Item size | 2 KB |
| GSIs | 1 |
| Base table size | 191 GB |
| Total table size | 381 GB |
| WCUs required | 400,000,000 |
| DynamoDB Import from S3 price per GB | $0.15 |
| DynamoDB write modes, if importing yourself | Cost |
| On demand | $500 |
| Provisioned capacity | $83 |
| DynamoDB Import from S3 | $28 |
The S3 import feature is available in all Regions. Refer to the DynamoDB pricing page for more details.
Conclusion
In this post, we introduced the DynamoDB import from S3 feature and showed you how to import data from an S3 bucket into DynamoDB. Ingesting large legacy datasets into DynamoDB just became much easier because now you can request an import without needing to set up infrastructure, write loading routines, or worry about capacity settings or throttling errors. You can use the previously released export to S3 feature to streamline administration of DynamoDB; you can move DynamoDB table data across Regions and across accounts with a few clicks in the console. You can use this sample script as a template for a script to convert MySQL data to DynamoDB JSON format and then write to an S3 bucket.
Please let us know your feedback in the comments section below.
About the authors
 Robert McCauley is a DynamoDB Specialist Solutions Architect based out of Boston. He began his Amazon career ten years ago as a SQL developer at Amazon Robotics, followed by a stint as an Alexa Skills solutions architect, before joining AWS.
Robert McCauley is a DynamoDB Specialist Solutions Architect based out of Boston. He began his Amazon career ten years ago as a SQL developer at Amazon Robotics, followed by a stint as an Alexa Skills solutions architect, before joining AWS.
 Aman Dhingra is a DynamoDB Specialist Solutions Architect based out of Dublin, Ireland. He is passionate about distributed systems and has a background in big data & analytics technologies. As a DynamoDB Specialist Solutions Architect, Aman helps customers design, evaluate, and optimize their workloads backed by DynamoDB.
Aman Dhingra is a DynamoDB Specialist Solutions Architect based out of Dublin, Ireland. He is passionate about distributed systems and has a background in big data & analytics technologies. As a DynamoDB Specialist Solutions Architect, Aman helps customers design, evaluate, and optimize their workloads backed by DynamoDB.