AWS Database Blog
Building AI-powered search in PostgreSQL using Amazon SageMaker and pgvector
Organizations across diverse sectors are exploring novel ways to enhance user experiences by harnessing the potential of Generative AI and large language models (LLMs).
In the fashion industry generative AI is revolutionizing the creative process. By analyzing user preferences and data, AI algorithms can generate unique apparel patterns and designs, bringing a new level of personalization and cost-effectiveness to the table.
Online streaming platforms are also benefiting from the capabilities of AI, particularly in video similarity search and recommendations. AI algorithms can analyze user behavior and recommend videos that closely align with their interests, enhancing the overall viewing experience. Moreover, AI-powered image and video hosting services can provide image deduplication, image similarity search, and text-to-image similarity search, resulting in improved search functionality.
The cheminformatics and bioinformatics industries are another area where AI is making its mark. With molecular similarity search and DNA sequence classification similarity search, AI is playing a key role in drug discovery and research. Whether it’s identifying potential drug candidates or analyzing DNA sequences, AI is proving to be an invaluable tool.
In this post, you’ll learn how to build a similar solution by creating a product catalog similarity search solution by integrating Amazon SageMaker and Amazon Relational Database Service (Amazon RDS) for PostgreSQL with the pgvector extension.
pgvector is an open-source extension for PostgreSQL that adds the ability to store and search over ML-generated embeddings. pgvector provides different capabilities that let users identify both exact and approximate nearest neighbors. It’s designed to work seamlessly with other PostgreSQL features, including indexing and querying. You can even use pgvector to store ML embeddings from Amazon Bedrock (limited preview).
No matter which industry you belong to, be it retail, gaming, streaming services, or life sciences, this post will provide valuable insights into using AI and the PostgreSQL extension pgvector for similarity search and beyond. Let’s get started!
Overview of vector embeddings
Embedding refers to the process of transforming objects such as text, images, video, or audio into numerical representations that reside in a high-dimensional vector space. This technique is achieved through the use of machine learning (ML) algorithms that enable the understanding of the meaning and context of data (semantic relationships), learning of complex relationships and patterns within the data (syntactic relationships). You can use the resulting vector representations for a wide range of applications such as information retrieval, image classification, natural language processing, and many others.
Vector embeddings have become increasingly popular due to their ability to capture semantic meaning and similarities between objects in a way that is easily computable and scalable. The following diagram provides a visual representation of what this looks like for word embeddings.

Figure 1: word embeddings: words that are semantically similar are close together in the embedding space.
After generating embeddings, an application or researcher can perform similarity searches within the vector space. Similarity searches over embeddings benefit various industry applications, including e-commerce, recommendation systems, and fraud detection. For example, systems can discern mathematical similarities between products or transactions to create relevant product recommendations or identifying potentially fraudulent activity.
In this post, we use the open-source pgvector extension for Amazon RDS for PostgreSQL, which facilitates the storage of embeddings and enables querying for a vector’s nearest neighbors. We demonstrate this functionality by constructing a laboratory scenario for an online retail store. We generate embeddings for products catalog using SageMaker, store them in RDS for PostgreSQL using the extension pgvector, and use them to provide vector similarity search capabilities for products catalog.
Using pgvector for efficient similarity searches over embeddings
By utilizing the pgvector extension, PostgreSQL can effectively perform similarity searches on vector embeddings, providing businesses with a speedy and proficient solution.
To generate vector embeddings for your product catalog, you can use an ML service such as Amazon SageMaker or Amazon Bedrock (limited preview). SageMaker allows you to easily train and deploy machine learning models, including models that generate vector embeddings for text data.
In this post, we use a pre-trained model, Hugging Face Inference Deep Learning Containers (DLCs) and Amazon SageMaker Python SDK to create a real-time inference endpoint running an all-MiniLM-L6-v2 sentence transformer model for generating document embeddings. We store the vector embeddings in RDS for PostgreSQL database using the pgvector extension. We then use pgvector’s similarity search capabilities to find the items in the product catalog that best match a customer’s search query intent.
pgvector’s indexing features further enhance search optimization. By indexing your vector data, you can expedite search processes and minimize the time required to identify the nearest neighbors to any given vector. We examine how the pgvector extension coalesces with PostgreSQL, providing a streamlined and effective solution for similarity searches on vector embeddings.
Let’s learn how pgvector works. First, we create and connect to an RDS for PostgreSQL database and install the extension. Following successful installation, you can initiate the storage of vector embeddings in the database and conduct searches as needed.
The pgvector extension introduces a new datatype called vector. You can see that the vector data type is installed using the following SQL statement:
You should see the following output:
We use the sentence-transformers/all-MiniLM-L6-v2 model for generating vector embeddings. It maps sentences and paragraphs to a 384-dimensional dense vector space, so we use that for our vector size in our solution.
Let’s review an example using pgvector. Using the code below, you’ll create a test table for storing three-dimensional vectors, insert some sample data, query it using Euclidean distance (also known as the L2 distance), and drop the test table:
The SELECT statement should return the following output:
Refer to the GitHub repo for additional details.
Demo: Using a similarity search for enhancing product catalog search in an online retail store
Now that we’ve reviewed how to use pgvector to build vector similarity searches, let’s learn how to use pgvector to build a search solution for an online retail store product catalog. We’ll build a search system that lets customers provide an item description to find similar items.
The following sections provide a step-by-step demo to perform a product similarity search. We will generate vector embeddings for product descriptions using a Hugging Face pre-trained model on a SageMaker instance. We will use Amazon RDS for PostgreSQL to store and perform a similarity search on our vector embeddings using the the pgvector extension.
The workflow steps are as follows:
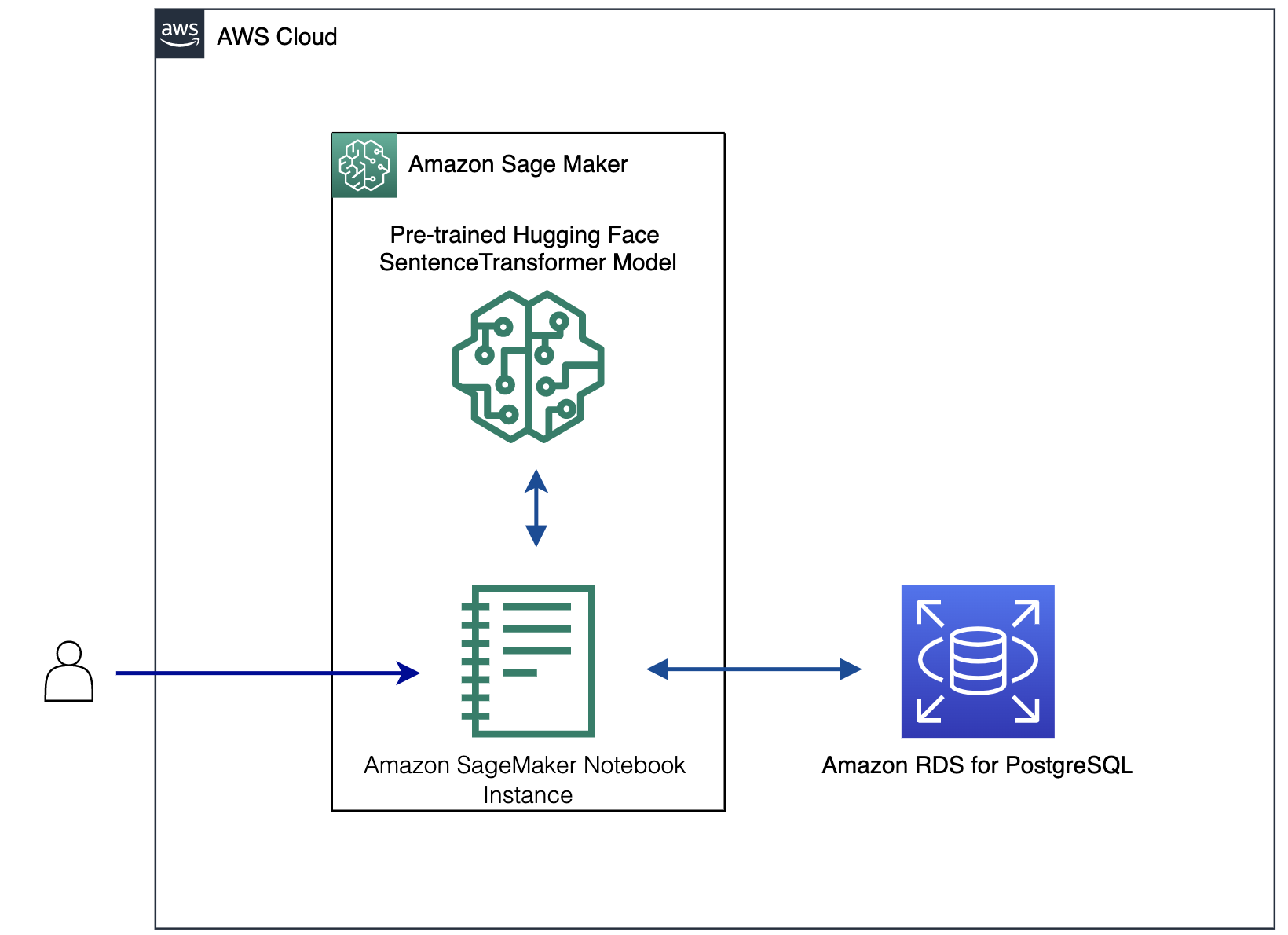
- Users interact with a Jupyter notebook on an a SageMaker notebook instance. A SageMaker notebook instance is an ML compute instance running the Jupyter Notebooks app. SageMaker manages creating the instance and related resources.
- Each item description, originally open-sourced in German, is translated to English using Amazon Translate.
- To generate embeddings for item descriptions, a pre-trained Hugging Face sentence transformer model will be deployed to SageMaker for real-time inference.
- Generate embeddings for a product catalog descriptions using SageMaker real-time inference.
- Use RDS for PostgreSQL to store the raw text (product description) and text embeddings.
- Use the SageMaker real-time inference to encode the query text into your embeddings.
- Use RDS for PostgreSQL to perform similarity search using the extension pgvector.
We use Amazon SageMaker Studio notebooks as the integrated development environment (IDE) to develop the solution. The following diagram illustrates the solution architecture.
Prerequisites
For this walkthrough, you should have an AWS account with the appropriate AWS Identity and Access Management (IAM) permissions to launch the provided Amazon CloudFormation template.
This solution will incur costs. Refer to the AWS pricing page to learn more.
Deploy your solution
We’ll use a CloudFormation stack to deploy this solution. The stack creates all the necessary resources, including the following:
- Networking components such as VPC and subnet resources.
- A SageMaker notebook instance to run the Python code in a Jupyter notebook.
- An IAM role associated with the notebook instance.
- A RDS for PostgreSQL instance to store and query vector embeddings.
To get started, complete the following steps:
- Sign in to the AWS Management Console with your IAM user name and password.
- Choose Launch Stack and open it in a new tab:

- On the Create stack page, select the check box to acknowledge the creation of IAM resources.
- Choose Create stack.
- Wait for the stack creation to complete. You can examine various events from the stack creation process on the Events tab. When the stack creation is complete, you see the status CREATE_COMPLETE.
- On the Outputs tab, choose
NotebookInstanceURL. This hyperlink opens the Jupyter notebook on your SageMaker notebook instance that you use to complete the rest of the solution.

- Open the notebook
rdspg-vector.ipynband run the code in all the cells in order and one at a time.

In the following sections, we examine parts of the code from a few important cells in the Jupyter notebook to demonstrate the solution.
Data ingestion
We use Zalando research FEIDEGGER data, which consists of 8,732 high-resolution fashion images and five textual annotations in German, each of which has been generated by a separate user. We use the Amazon Translate to translate each dress description from German to English. The code is as follows:
SageMaker model hosting
In this section, we host the pre-trained all-MiniLM-L6-v2 Hugging Face sentence transformer model, into SageMaker and generate 384 dimensional vector embeddings for our product catalog.
The steps are as follows:
- Run the following code:
- Test the SageMaker real-time inference endpoint and generate embeddings:
The result will display 384-dimensional vector embeddings for the given input text.
- Make inference requests using SageMaker to generate the vector embeddings (384 dimension) for our product catalog descriptions:
- Connect to RDS for PostgreSQL and create a products table with the vector data type and ingest the data. Then, create an index for the similarity search for finding the nearest L2 distance neighbors:
- Run a query to perform a similarity search on the products table in RDS for PostgreSQL using the pgvector extension:
The above code should return output that is similar to the examples below:

Now, when a customer enters a search query like “red sleeveless summer dress” on your online retail application, the vector similarity search feature provides your customer with the closest matching results.
Cleanup
Run the following code in the Jupyter notebook cell to delete the model and endpoint:
Next, delete the CloudFormation template to clean up the remaining resources.
Conclusion
The integration of embeddings generated using SageMaker and Amazon RDS for PostgreSQL with the pgvector open-source extension for PostgreSQL presents a powerful and efficient solution for optimizing the product catalog similarity search experience. By using ML models and vector embeddings, businesses can enhance the accuracy and speed of similarity searches, personalized recommendations, and fraud detection, which ultimately leads to improved user satisfaction and a more personalized experience.
The use of pgvector provides scalability to query large datasets and also integrates with PostgreSQL’s existing features. Whether you’re navigating through extensive e-commerce product catalogs or delivering highly relevant recommendations, the combination of SageMaker and pgvector equips organizations with the tools they need to succeed in a dynamic and data-driven world.
PostgreSQL’s extensibility makes it possible for developers to build new data types and indexing mechanisms as workloads continue to evolve. As we continue to see new innovations in AI and ML, we can use PostgreSQL for building applications that harness the power of these new AI/ML models.
For more information about the code sample used in the post, see the GitHub repo.
About the Author
 Krishna Sarabu is a Senior Database Specialist Solutions Architect with Amazon Web Services. He works with the Amazon RDS team, focusing on open-source database engines Amazon RDS for PostgreSQL and Amazon Aurora PostgreSQL. He has over 20 years of experience in managing commercial and open-source database solutions in the financial industry. He enjoys working with customers to help design, deploy, and optimize relational database workloads on AWS.
Krishna Sarabu is a Senior Database Specialist Solutions Architect with Amazon Web Services. He works with the Amazon RDS team, focusing on open-source database engines Amazon RDS for PostgreSQL and Amazon Aurora PostgreSQL. He has over 20 years of experience in managing commercial and open-source database solutions in the financial industry. He enjoys working with customers to help design, deploy, and optimize relational database workloads on AWS.