AWS Big Data Blog
Best practices to scale Apache Spark jobs and partition data with AWS Glue
July 2022: This post was reviewed for accuracy.
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more.
AWS Glue provides a serverless environment to prepare (extract and transform) and load large amounts of datasets from a variety of sources for analytics and data processing with Apache Spark ETL jobs. This series of posts discusses best practices to help developers of Apache Spark applications and Glue ETL jobs, big data architects, data engineers, and business analysts scale their data processing jobs running on AWS Glue automatically.
The first post of this series discusses two key AWS Glue capabilities to manage the scaling of data processing jobs. The first allows you to horizontally scale out Apache Spark applications for large splittable datasets. The second allows you to vertically scale up memory-intensive Apache Spark applications with the help of new AWS Glue worker types. The post also shows how to use AWS Glue to scale Apache Spark applications with a large number of small files commonly ingested from streaming applications using Amazon Kinesis Data Firehose. Finally, the post shows how AWS Glue jobs can use the partitioning structure of large datasets in Amazon S3 to provide faster execution times for Apache Spark applications.
Understanding AWS Glue worker types
AWS Glue comes with three worker types to help customers select the configuration that meets their job latency and cost requirements. These workers, also known as Data Processing Units (DPUs), come in Standard, G.1X, and G.2X configurations.
The standard worker consists of 16 GB memory, 4 vCPUs of compute capacity, and 50 GB of attached EBS storage with two Spark executors. The G.1X worker consists of 16 GB memory, 4 vCPUs, and 64 GB of attached EBS storage with one Spark executor. The G.2X worker allocates twice as much memory, disk space, and vCPUs as G.1X worker type with one Spark executor. For more details on AWS Glue Worker types, see the documentation on AWS Glue Jobs.
The compute parallelism (Apache Spark tasks per DPU) available for horizontal scaling is the same regardless of the worker type. For example, both standard and G1.X workers map to 1 DPU, each of which can run eight concurrent tasks. A G2.X worker maps to 2 DPUs, which can run 16 concurrent tasks. As a result, compute-intensive AWS Glue jobs that possess a high degree of data parallelism can benefit from horizontal scaling (more standard or G1.X workers). AWS Glue jobs that need high memory or ample disk space to store intermediate shuffle output can benefit from vertical scaling (more G1.X or G2.x workers).
Horizontal scaling for splittable datasets
AWS Glue automatically supports file splitting when reading common native formats (such as CSV and JSON) and modern file formats (such as Parquet and ORC) from S3 using AWS Glue DynamicFrames. For more information about DynamicFrames, see Work with partitioned data in AWS Glue.
A file split is a portion of a file that a Spark task can read and process independently on an AWS Glue worker. By default, file splitting is enabled for line-delimited native formats, which allows Apache Spark jobs running on AWS Glue to parallelize computation across multiple executors. AWS Glue jobs that process large splittable datasets with medium (hundreds of megabytes) or large (several gigabytes) file sizes can benefit from horizontal scaling and run faster by adding more AWS Glue workers.
File splitting also benefits block-based compression formats such as bzip2. You can read each compression block on a file split boundary and process them independently. Unsplittable compression formats such as gzip do not benefit from file splitting. To horizontally scale jobs that read unsplittable files or compression formats, prepare the input datasets with multiple medium-sized files.
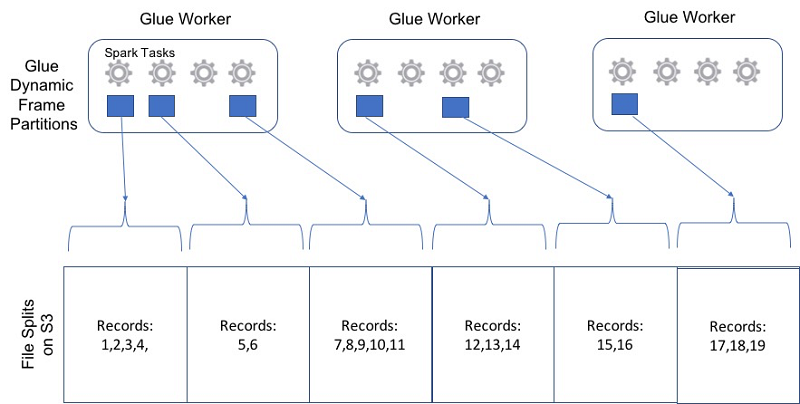
Each file split (the blue square in the figure) is read from S3, deserialized into an AWS Glue DynamicFrame partition, and then processed by an Apache Spark task (the gear icon in the figure). Deserialized partition sizes can be significantly larger than the on-disk 64 MB file split size, especially for highly compressed splittable file formats such as Parquet or large files using unsplittable compression formats such as gzip. Typically, a deserialized partition is not cached in memory, and only constructed when needed due to Apache Spark’s lazy evaluation of transformations, thus not causing any memory pressure on AWS Glue workers. For more information on lazy evaluation, see the RDD Programming Guide on the Apache Spark website.
However, explicitly caching a partition in memory or spilling it out to local disk in an AWS Glue ETL script or Apache Spark application can result in out-of-memory (OOM) or out-of-disk exceptions. AWS Glue can support such use cases by using larger AWS Glue worker types with vertically scaled-up DPU instances for AWS Glue ETL jobs.
Vertical scaling for Apache Spark jobs using larger worker types
A variety of AWS Glue ETL jobs, Apache Spark applications, and new machine learning (ML) Glue transformations supported with AWS Lake Formation have high memory and disk requirements. Running these workloads may put significant memory pressure on the execution engine. This memory pressure can result in job failures because of OOM or out-of-disk space exceptions. You may see exceptions from Yarn about memory and disk space.
Exceeding Yarn memory overhead
Apache Yarn is responsible for allocating cluster resources needed to run your Spark application. An application includes a Spark driver and multiple executor JVMs. In addition to the memory allocation required to run a job for each executor, Yarn also allocates an extra overhead memory to accommodate for JVM overhead, interned strings, and other metadata that the JVM needs. The configuration parameter spark.yarn.executor.memoryOverhead defaults to 10% of the total executor memory. Memory-intensive operations such as joining large tables or processing datasets with a skew in the distribution of specific column values may exceed the memory threshold, and result in the following error message:
Disk space
Apache Spark uses local disk on Glue workers to spill data from memory that exceeds the heap space defined by the spark.memory.fraction configuration parameter. During the sort or shuffle stages of a job, Spark writes intermediate data to local disk before it can exchange that data between the different workers. Jobs may fail due to the following exception when no disk space remains:
AWS Glue job metrics
Most commonly, this is a result of a significant skew in the dataset that the job is processing. You can also identify the skew by monitoring the execution timeline of different Apache Spark executors using AWS Glue job metrics. For more information, see Debugging Demanding Stages and Straggler Tasks.
The following AWS Glue job metrics graph shows the execution timeline and memory profile of different executors in an AWS Glue ETL job. One of the executors (the red line) is straggling due to processing of a large partition, and actively consumes memory for the majority of the job’s duration.

With AWS Glue’s Vertical Scaling feature, memory-intensive Apache Spark jobs can use AWS Glue workers with higher memory and larger disk space to help overcome these two common failures. Using AWS Glue job metrics, you can also debug OOM and determine the ideal worker type for your job by inspecting the memory usage of the driver and executors for a running job. For more information, see Debugging OOM Exceptions and Job Abnormalities.
In general, jobs that run memory-intensive operations can benefit from the G1.X worker type, and those that use AWS Glue’s ML transforms or similar ML workloads can benefit from the G2.X worker type.
Apache Spark UI for AWS Glue jobs
You can also use AWS Glue’s support for Spark UI to inpect and scale your AWS Glue ETL job by visualizing the Directed Acyclic Graph (DAG) of Spark’s execution, and also monitor demanding stages, large shuffles, and inspect Spark SQL query plans. For more information, see Monitoring Jobs Using the Apache Spark Web UI.
The following Spark SQL query plan on the Spark UI shows the DAG for an ETL job that reads two tables from S3, performs an outer-join that results in a Spark shuffle, and writes the result to S3 in Parquet format.

As seen from the plan, the Spark shuffle and subsequent sort operation for the join transformation takes the majority of the job execution time. With AWS Glue vertical scaling, each AWS Glue worker co-locates more Spark tasks, thereby saving on the number of data exchanges over the network.
Scaling to handle large numbers of small files
An AWS Glue ETL job might read thousands or millions of files from S3. This is typical for Kinesis Data Firehose or streaming applications writing data into S3. The Apache Spark driver may run out of memory when attempting to read a large number of files. When this happens, you see the following error message:
Apache Spark v2.2 can manage approximately 650,000 files on the standard AWS Glue worker type. To handle more files, AWS Glue provides the option to read input files in larger groups per Spark task for each AWS Glue worker. For more information, see Reading Input Files in Larger Groups.

You can reduce the excessive parallelism from the launch of one Apache Spark task to process each file by using AWS Glue file grouping. This method reduces the chances of an OOM exception on the Spark driver. To configure file grouping, you need to set groupFiles and groupSize parameters. The following code example uses AWS Glue DynamicFrame API in an ETL script with these parameters:
You can set groupFiles to group files within a Hive-style S3 partition (inPartition) or across S3 partitions (acrossPartition). In most scenarios, grouping within a partition is sufficient to reduce the number of concurrent Spark tasks and the memory footprint of the Spark driver. In benchmarks, AWS Glue ETL jobs configured with the inPartition grouping option were approximately seven times faster than native Apache Spark v2.2 when processing 320,000 small JSON files distributed across 160 different S3 partitions. A large fraction of the time in Apache Spark is spent building an in-memory index while listing S3 files and scheduling a large number of short-running tasks to process each file. With AWS Glue grouping enabled, the benchmark AWS Glue ETL job could process more than 1 million files using the standard AWS Glue worker type.
groupSize is an optional field that allows you to configure the amount of data each Spark task reads and processes as a single AWS Glue DynamicFrame partition. Users can set groupSize if they know the distribution of file sizes before running the job. The groupSize parameter allows you to control the number of AWS Glue DynamicFrame partitions, which also translates into the number of output files. However, using a considerably small or large groupSize can result in significant task parallelism or under-utilization of the cluster, respectively.
By default, AWS Glue automatically enables grouping without any manual configuration when the number of input files or task parallelism exceeds a threshold of 50,000. The default value of the groupFiles parameter is inPartition, so that each Spark task only reads files within the same S3 partition. AWS Glue computes the groupSize parameter automatically and configures it to reduce the excessive parallelism, and makes use of the cluster compute resources with sufficient Spark tasks running in parallel.
Partitioning data and pushdown predicates
Partitioning has emerged as an important technique for organizing datasets so that a variety of big data systems can query them efficiently. A hierarchical directory structure organizes the data, based on the distinct values of one or more columns. For example, you can partition your application logs in S3 by date, broken down by year, month, and day. Files corresponding to a single day’s worth of data receive a prefix such as the following:
s3://my_bucket/logs/year=2018/month=01/day=23/
Predicate pushdowns for partition columns
AWS Glue supports pushing down predicates, which define a filter criteria for partition columns populated for a table in the AWS Glue Data Catalog. Instead of reading all the data and filtering results at execution time, you can supply a SQL predicate in the form of a WHERE clause on the partition column. For example, assume the table is partitioned by the year column and run SELECT * FROM table WHERE year = 2019. year represents the partition column and 2019 represents the filter criteria.
AWS Glue lists and reads only the files from S3 partitions that satisfy the predicate and are necessary for processing.
To accomplish this, specify a predicate using the Spark SQL expression language as an additional parameter to the AWS Glue DynamicFrame getCatalogSource method. This predicate can be any SQL expression or user-defined function that evaluates to a Boolean, as long as it uses only the partition columns for filtering.
This example demonstrates this functionality with a dataset of Github events partitioned by year, month, and day. The following code example reads only those S3 partitions related to events that occurred on weekends:
Here you can use the SparkSQL string concat function to construct a date string. The to_date function converts it to a date object, and the date_format function with the ‘E’ pattern converts the date to a three-character day of the week (for example, Mon or Tue). For more information about these functions, Spark SQL expressions, and user-defined functions in general, see the Spark SQL, DataFrames and Datasets Guide and list of functions on the Apache Spark website.
There is a significant performance boost for AWS Glue ETL jobs when pruning AWS Glue Data Catalog partitions. It reduces the time needed for the Spark query engine for listing files in S3 and reading and processing data at runtime. You can achieve further improvement as you exclude additional partitions by using predicates with higher selectivity.
Partitioning data before and during writes to S3
By default, data is not partitioned when writing out the results from an AWS Glue DynamicFrame—all output files are written at the top level under the specified output path. AWS Glue enables partitioning of DynamicFrame results by passing the partitionKeys option when creating a sink. For example, the following code example writes out the dataset in Parquet format to S3 partitioned by the type column:
In this example, $outpath is a placeholder for the base output path in S3. The partitionKeys parameter corresponds to the names of the columns used to partition the output in S3. When you execute the write operation, it removes the type column from the individual records and encodes it in the directory structure. To demonstrate this, you can list the output path using the following aws s3 ls command from the AWS CLI:
For more information, see aws . s3 . ls in the AWS CLI Command Reference.
In general, you should select columns for partitionKeys that are of lower cardinality and are most commonly used to filter or group query results. For example, when analyzing AWS CloudTrail logs, it is common to look for events that happened between a range of dates. Therefore, partitioning the CloudTrail data by year, month, and day would improve query performance and reduce the amount of data that you need to scan to return the answer.
The benefit of output partitioning is two-fold. First, it improves execution time for end-user queries. Second, having an appropriate partitioning scheme helps avoid costly Spark shuffle operations in downstream AWS Glue ETL jobs when combining multiple jobs into a data pipeline. For more information, see Working with partitioned data in AWS Glue.
S3 or Hive-style partitions are different from Spark RDD or DynamicFrame partitions. Spark partitioning is related to how Spark or AWS Glue breaks up a large dataset into smaller and more manageable chunks to read and apply transformations in parallel. AWS Glue workers manage this type of partitioning in memory. You can control Spark partitions further by using the repartition or coalesce functions on DynamicFrames at any point during a job’s execution and before data is written to S3. You can set the number of partitions using the repartition function either by explicitly specifying the total number of partitions or by selecting the columns to partition the data.
Repartitioning a dataset by using the repartition or coalesce functions often results in AWS Glue workers exchanging (shuffling) data, which can impact job runtime and increase memory pressure. In contrast, writing data to S3 with Hive-style partitioning does not require any data shuffle and only sorts it locally on each of the worker nodes. The number of output files in S3 without Hive-style partitioning roughly corresponds to the number of Spark partitions. In contrast, the number of output files in S3 with Hive-style partitioning can vary based on the distribution of partition keys on each AWS Glue worker.
Conclusion
This post showed how to scale your ETL jobs and Apache Spark applications on AWS Glue for both compute and memory-intensive jobs. AWS Glue enables faster job execution times and efficient memory management by using the parallelism of the dataset and different types of AWS Glue workers. It also helps you overcome the challenges of processing many small files by automatically adjusting the parallelism of the workload and cluster. AWS Glue ETL jobs use the AWS Glue Data Catalog and enable seamless partition pruning using predicate pushdowns. It also allows for efficient partitioning of datasets in S3 for faster queries by downstream Apache Spark applications and other analytics engines such as Amazon Athena and Amazon Redshift. We hope you try out these best practices for your Apache Spark applications on AWS Glue.
The second post in this series will show how to use AWS Glue features to batch process large historical datasets and incrementally process deltas in S3 data lakes. It also demonstrates how to use a custom AWS Glue Parquet writer for faster job execution.
About the Author
 Mohit Saxena is a technical lead at AWS Glue. His passion is building scalable distributed systems for efficiently managing data on cloud. He also enjoys watching movies, and reading about the latest technology.
Mohit Saxena is a technical lead at AWS Glue. His passion is building scalable distributed systems for efficiently managing data on cloud. He also enjoys watching movies, and reading about the latest technology.