AWS Big Data Blog
Improve federated queries with predicate pushdown in Amazon Athena
In modern data architectures, it’s common to store data in multiple data sources. However, organizations embracing this approach still need insights from their data and require technologies that help them break down data silos. Amazon Athena is an interactive query service that makes it easy to analyze structured, unstructured, and semi-structured data stored in Amazon Simple Storage Service (Amazon S3) in addition to relational, non-relation, object, and custom data sources through its query federation capabilities. Athena is serverless, so there’s no infrastructure to manage, and you only pay for the queries that you run.
Organizations building a modern data architecture want to query data in-place from purpose-built data stores without building complex extract, transform, and load (ETL) pipelines. Athena’s federated query feature allows organizations to achieve this and makes it easy to:
- Create reports and dashboards from data stored in relational, non-relational, object, and custom data sources
- Run on-demand analysis on data spread across multiple systems of record using a single tool and single SQL dialect
- Join multiple data sources together to produce new input features for machine learning model training workflows
However, when querying and joining huge amounts of data from different data stores, it’s important for queries to run quickly, at low cost, and without impacting source systems. Predicate pushdown is supported by many query engines and is a technique that can drastically reduce query processing time by filtering data at the source early in the processing workflow. In this post, you’ll learn how predicate pushdown improves query performance and how you can validate when Athena applies predicate pushdown to federated queries.
Benefits of predicate pushdown
The key benefits of predicate pushdown are as follows:
- Improved query runtime
- Reduced network traffic between Athena and the data source
- Reduced load on the remote data source
- Reduced cost resulting from reduced data scans
Let’s explore a real-world scenario to understand when predicate pushdown is applied to federated queries in Athena.
Solution overview
Imagine a hypothetical ecommerce company with data stored in
- Amazon Redshift – Company’s Datawarehouse, used for current and historical analytics
- Amazon Aurora MySQL-Compatible Edition – Relational Database, used for pricing related transactions done by company’s customer
- Amazon DynamoDB – NoSQL Database, used for real-time inventory tracking and latest supplier data in the company
Record counts for these tables are as follows.
| Data Store | Table Name | Number of Records | Description |
| Amazon Redshift | Catalog_Sales |
4.3 billion | Current and historical Sales data fact Table |
| Amazon Redshift | Date_dim |
73,000 | Date Dimension table |
| DynamoDB | Part |
20,000 | Realtime Parts and Inventory data |
| DynamoDB | Partsupp |
80,000 | Realtime Parts and supplier data |
| Aurora MySQL | Supplier |
1,000 | Latest Supplier transactions |
| Aurora MySQL | Customer |
15,000 | Latest Customer transactions |
Our requirement is to query these sources individually and join the data to track pricing and supplier information and compare recent data with historical data using SQL queries with various filters applied. We’ll use Athena federated queries to query and join data from these sources to meet this requirement.
The following diagram depicts how Athena federated queries use data source connectors run as Lambda functions to query data stored in sources other than Amazon S3.

When a federated query is submitted against a data source, Athena invokes the data source connector to determine how to read the requested table and identify filter predicates in the WHERE clause of the query that can be pushed down to the source. Applicable filters are automatically pushed down by Athena and have the effect of omitting unnecessary rows early in the query processing workflow and improving overall query execution time.
Let’s explore three use cases to demonstrate predicate pushdown for our ecommerce company using each of these services.
Prerequisites
As a prerequisite, review Using Amazon Athena Federated Query to know more about Athena federated queries and how to deploy these data source connectors.
Use case 1: Amazon Redshift
In our first scenario, we run an Athena federated query on Amazon Redshift by joining its Catalog_sales and Date_dim tables. We do this to show the number of sales orders grouped by order date. The following query gets the information required and takes approximately 14 seconds scanning approximately 43 MB of data:
Athena pushes the following filters to the source for processing:
cs_sold_date_skbetween 2450815 and 2450822 for theCatalog_Salestable in Amazon Redshift.d_date_sk between 2450815 and 2450822;because of the joinl.cs_sold_date_sk=d_date_skin the query, theDate_dimtable is also filtered at the source, and only filtered data is moved from Amazon Redshift to Athena.
Let’s analyze the query plan by using recently released visual explain tool to confirm the filter predicates are pushed to the data source:

As shown above (only displaying the relevant part of the visual explain plan), because of the predicate pushdown, the Catalog_sales and Date_dim tables have filters applied at the source. Athena processes only the resulting filtered data.
Using the Athena console, we can see query processing details using the recently released query stats to interactively explore processing details with predicate pushdown at the query stage:

Displaying only the relevant query processing stages, Catalog_sales table has approximately 4.3 billion records, and Date_dim has approximately 73,000 records in Amazon Redshift. Only 11 million records from the Catalog_sales (Stage 4) and 8 records from the Date_dim (Stage 5) are passed from source to Athena, because the predicate pushdown pushes query filter conditions to the data sources. This filters out unneeded records at the source, and only brings the required rows to Athena.
Using predicate pushdown resulted in scanning 99.75% less data from Catalog_sales and 99.99% less data from Date_dim. This results in a faster query runtime and lower cost.
Use case 2: Amazon Redshift and Aurora MySQL
In our second use case, we run an Athena federated query on Aurora MySQL and Amazon Redshift data stores. This query joins the Catalog_sales and Date_dim tables in Amazon Redshift with the Customer table in the Aurora MySQL database to get the total number of orders with the total amount spent by each customer for the first week in January 1998 for the market segment of AUTOMOBILE. The following query gets the information required and takes approximately 35 seconds scanning approximately 337 MB of data:
Athena pushes the following filters to the data sources for processing:
cs_sold_date_sk between 2450815 and 2450822for theCatalog_Salestable in Amazon Redshift.d_date_sk between 2450815 and 2450822;because of the joinl.cs_sold_date_sk=d_date_skin the query, theDate_dimtable is also filtered at the source (Amazon Redshift) and only filtered data is moved from Amazon Redshift to Athena.c_mktsegment = 'AUTOMOBILE'for theCustomertable in the Aurora MySQL database.
Now let’s consult the visual explain plan for this query to show the predicate pushdown to the source for processing:
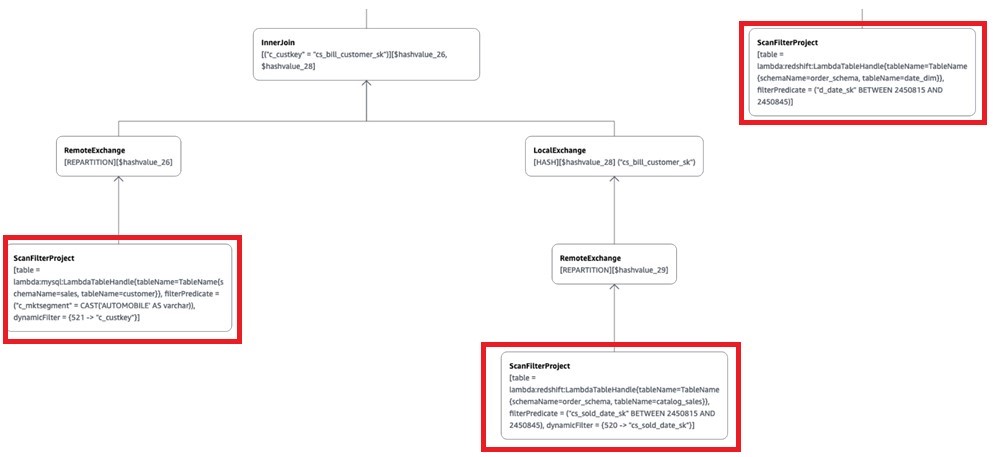
As shown above (only displaying the relevant part of the visual explain plan), because of the predicate pushdown, Catalog_sales and Date_dim have the query filter applied at the source (Amazon Redshift), and the customer table has the market segment AUTOMOBILE filter applied at the source (Aurora MySQL). This brings only the filtered data to Athena.
As before, we can see query processing details using the recently released query stats to interactively explore processing details with predicate pushdown at the query stage:
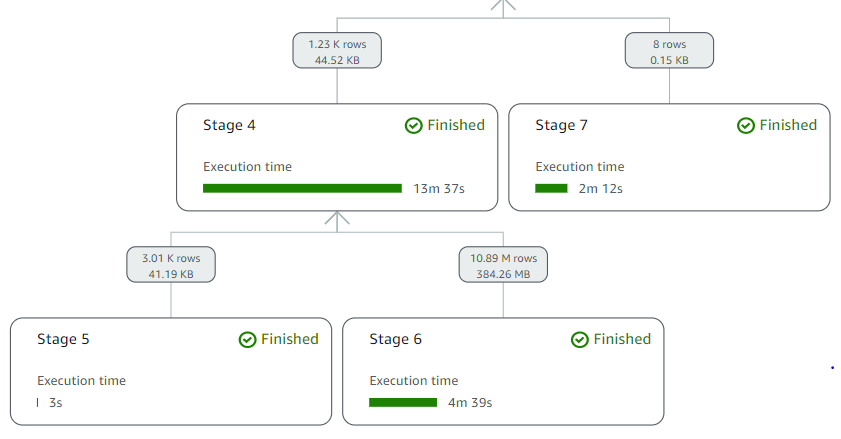
Displaying only the relevant query processing stages, Catalog_sales has 4.3 billion records, Date_Dim has 73,000 records in Amazon Redshift, and Customer has 15,000 records in Aurora MySQL. Only 11 million records from Catalog_sales (Stage 6), 8 records from Date_dim (Stage 7), and 3,000 records from Customer (Stage 5) are passed from the respective sources to Athena because the predicate pushdown pushes query filter conditions to the data sources. This filters out unneeded records at the source and only brings the required rows to Athena.
Here, predicate pushdown resulted in scanning 99.75% less data from Catalog_sales, 99.99% less data from Date_dim, and 79.91% from Customer. Furthermore, this results in a faster query runtime and reduced cost.
Use case 3: Amazon Redshift, Aurora MySQL, and DynamoDB
For our third use case, we run an Athena federated query on Aurora MySQL, Amazon Redshift, and DynamoDB data stores. This query joins the Part and Partsupp tables in DynamoDB, the Catalog_sales and Date_dim tables in Amazon Redshift, and the Supplier and Customer tables in Aurora MySQL to get the quantities available at each supplier for orders with the highest revenue during the first week of January 1998 for the market segment of AUTOMOBILE and parts manufactured by Manufacturer#1.
The following query gets the information required and takes approximately 33 seconds scanning approximately 428 MB of data in Athena:
Athena pushes the following filters to the data sources for processing:
cs_sold_date_sk between 2450815 and 2450822for theCatalog_Salestable in Amazon Redshift.d_date_sk between 2450815 and 2450822;because of the joinl.cs_sold_date_sk=d_date_skin the query, theDate_dimtable is also filtered at the source and only filtered data is moved from Amazon Redshift to Athena.c_mktsegment = 'AUTOMOBILE'for theCustomertable in the Aurora MySQL database.p.p_mfgr='Manufacturer#1'for theParttable in DynamoDB.
Now let’s run the explain plan for this query to confirm predicates are pushed down to the source for processing:
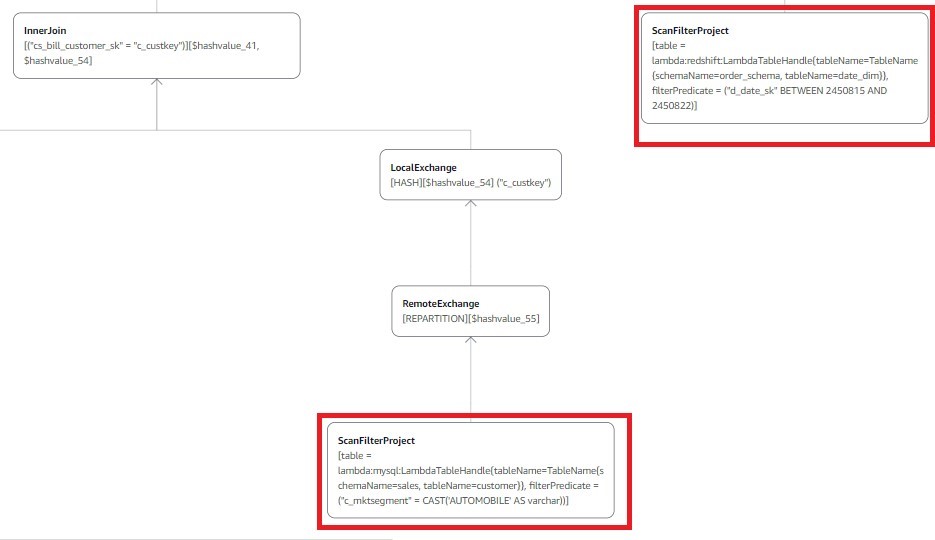

As shown above (displaying only the relevant part of the plan), because of the predicate pushdown, Catalog_sales and Date_dim have the query filter applied at the source (Amazon Redshift), the Customer table has the market segment AUTOMOBILE filter applied at the source (Aurora MySQL), and the Part table has the part manufactured by Manufacturer#1 filter applied at the source (DynamoDB).
We can analyze query processing details using the recently released query stats to interactively explore processing details with predicate pushdown at the query stage:

Displaying only the relevant processing stages, Catalog_sales has 4.3 billion records, Date_Dim has 73,000 records in Amazon Redshift, Customer has 15,000 records in Aurora MySQL, and Part has 20,000 records in DynamoDB. Only 11 million records from Catalog_sales (Stage 5), 8 records from Date_dim (Stage 9), 3,000 records from Customer (Stage 8), and 4,000 records from Part (Stage 4) are passed from their respective sources to Athena, because the predicate pushdown pushes query filter conditions to the data sources. This filters out unneeded records at the source, and only brings the required rows from the sources to Athena.
Considerations for predicate pushdown
When using Athena to query your data sources, consider the following:
- Depending on the data source, data source connector, and query complexity, Athena can push filter predicates to the source for processing. The following are some of the sources Athena supports predicate pushdown with:
- Athena also performs predicate pushdown on data stored in an S3 data lake. And, with predicate pushdown for supported sources, you can join all your data sources in one query and achieve fast query performance.
- You can use the recently released query stats as well as EXPLAIN and EXPLAIN ANALYZE on your queries to confirm predicates are pushed down to the source.
- Queries may not have predicates pushed to the source if the query’s WHERE clause uses Athena-specific functions (for example,
WHERE log2(col)<10).
Conclusion
In this post, we demonstrated three federated query scenarios on Aurora MySQL, Amazon Redshift, and DynamoDB to show how predicate pushdown improves federated query performance and reduces cost and how you can validate when predicate pushdown occurs. If the federated data source supports parallel scans, then predicate pushdown makes it possible to achieve performance that is close to the performance of Athena queries on data stored in Amazon S3. You can utilize the patterns and recommendations outlined in this post when querying supported data sources to improve overall query performance and minimize data scanned.
About the authors
 Rohit Bansal is an Analytics Specialist Solutions Architect at AWS. He has nearly two decades of experience helping customers modernize their data platforms. He is passionate about helping customers build scalable, cost-effective data and analytics solutions in the cloud. In his spare time, he enjoys spending time with his family, travel, and road cycling.
Rohit Bansal is an Analytics Specialist Solutions Architect at AWS. He has nearly two decades of experience helping customers modernize their data platforms. He is passionate about helping customers build scalable, cost-effective data and analytics solutions in the cloud. In his spare time, he enjoys spending time with his family, travel, and road cycling.
 Ruchir Tripathi is a Senior Analytics Solutions Architect aligned to Global Financial Services at AWS. He is passionate about helping enterprises build scalable, performant, and cost-effective solutions in the cloud. Prior to joining AWS, Ruchir worked with major financial institutions and is based out of New York Office.
Ruchir Tripathi is a Senior Analytics Solutions Architect aligned to Global Financial Services at AWS. He is passionate about helping enterprises build scalable, performant, and cost-effective solutions in the cloud. Prior to joining AWS, Ruchir worked with major financial institutions and is based out of New York Office.