AWS Partner Network (APN) Blog
Bigstream Provides Big Data Acceleration with Apache Spark and Amazon EMR
By Brad Kashani, CEO at Bigstream
 |
Big data platforms have seen remarkable growth in recent years. Apache Spark and its parallel processing framework, along with the ease of scaling up in public clouds, have pushed out the limits for data analytics.
Organizations can now just throw more computing—specifically, bigger or more central processing unit (CPU) instances—at more complex problems.
That approach, however, comes with rapidly escalating costs and diminishing returns to scale. An alternative approach is to accelerate the platforms, accessing CPU-alternatives such as field-programmable gate arrays (FPGAs), graphics processing units (GPUs), or application-specific integrated circuits (ASICs), and deploying software to deliver operator-level execution more efficiently.
Bigstream is an AWS ISV Partner and pioneer in this field. With hardware- and software-level acceleration, Bigstream brings the fast Spark deployment to Amazon Web Services (AWS).
In this post, I will describe why acceleration has better potential than CPU scaling, the historic challenges organizations have had in implementing accelerators, and how Bigstream is able to address those for a seamless, accelerated Spark experience.
Scalability and Accessibility Drive Spark Usage
As open source-based software, Spark has been accessible to big and small organizations, often at the cutting edge. Rather than bring data to a single processor, Spark spreads compute-intensive workloads across a “cluster” of multiple processors, also referred to as nodes.
Amazon EMR is one of the leading distributions of Spark, freeing users from the complexity of cluster creation and other administration.
With every processor added to a Spark cluster comes increased orchestration requirements. Doubling the number of nodes yields far less than double the performance.
Hardware Acceleration Has Not Been Deployable
Hardware acceleration technologies hold the promise of more efficiently using computing resources and specialized hardware beyond CPUs. Specialized hardware can handle certain data operations more effectively than a CPU.
Also, by offloading work from the CPUs, organizations can increase performance on an existing Spark cluster without the overhead of more CPU server nodes.
Unfortunately, these technologies have historically required hardware programming complexity and mean data scientists must significantly alter their code. Bigstream’s technology bridges that gap with an efficient and flexible solution that processes data faster and reduces spending.
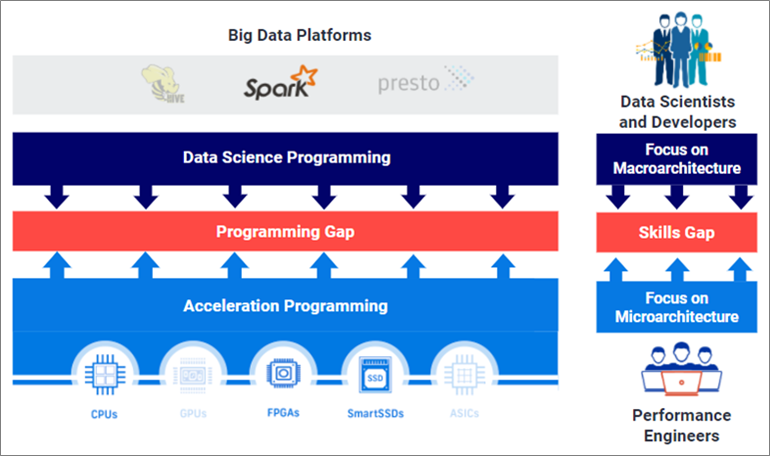
Figure 1 – Acceleration falls within a programming gap.
Bigstream Accelerates Spark Seamlessly
Bigstream opens Spark up to specialized hardware and requires zero Spark code changes. Spark users don’t tend to focus on the underlying processing infrastructure or have the skills or interest to program advanced hardware. Their focus is more on optimizing data pipelines, processing, and analytics.
Meanwhile, infrastructure teams are not familiar enough with Spark to add accelerators non-disruptively. While they can install and/or provision GPUs or FPGAs, most applications cannot take advantage of their benefits without special programming.
Bigstream bridges this programming gap so users don’t have to change a single line of Spark code and IT teams don’t have to program the specialized hardware.
Customers choose managed Spark offerings like Amazon EMR for their ease of use. In addition to not requiring Spark code changes, Bigstream can be added with just a few additional clicks during EMR cluster creation.
How it Works
Spark has become the de facto standard for big data processing through its distributed computing framework. Let’s examine this framework and illustrate how Bigstream accelerates it seamlessly.
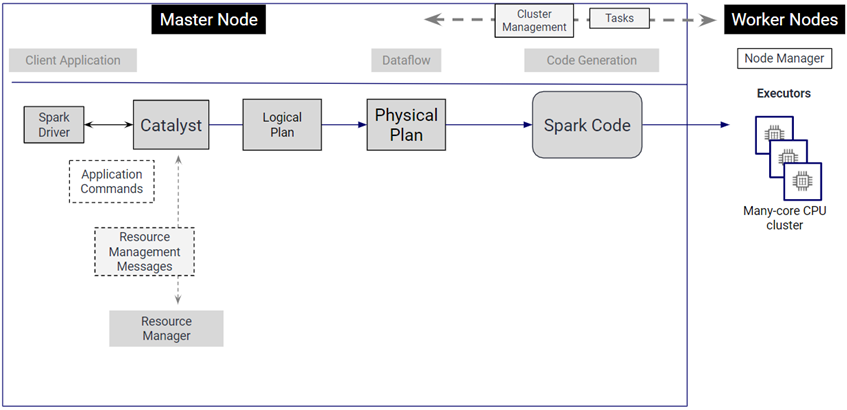
Figure 2 – Apache Spark basic framework.
Apache Spark on Amazon EMR turns the user’s code into multiple iterations of a logical plan, and ultimately generates code by creating an optimized physical plan.
This data structure defines how the code will be run as tasks across multiple executors on multiple physical nodes. Its focus is on parallelization across the nodes, the efficiency and order of the stages, and task details, such as which type of join to run.
Bigstream delivers acceleration at the level of the actual operator and task, leaving the physical plan unchanged, but calling on software and hardware optimization to deliver a faster scan, filter, or sort, for instance.
In many cases, the biggest acceleration comes by having an FPGA process a task rather than the CPU. The FPGAs are more efficient for many Spark operations, and they also free up the CPUs to process other work.
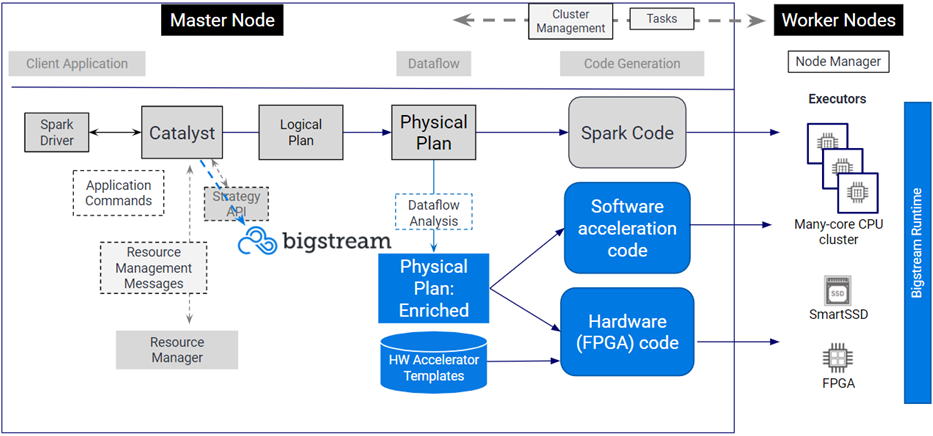
Figure 3 – How Bigstream accelerates Apache Spark.
The Client Application, Spark Driver, Resource Manager, Physical Plan, and structure of the Master and Executors all remain unchanged with Bigstream.
The Bigstream Compiler evaluates each individual stage of the Physical Plan for potential execution acceleration. This list of stages that can be accelerated is pushed to the Bigstream Runtime API. For FPGA acceleration, this is a set of bitfile templates and their associated APIs that implement accelerated versions of Spark stages.
At cluster bootstrap time, a hook is added to all Executors that enables a pre-execution check of whether a stage can be accelerated. If so, the associated compiled module is called. If not, the standard Java bytecode version is executed.
The result is that the Spark programmer doesn’t have to change a single line of code, and yet end-to-end run times are accelerated up to 10x. If acceleration of a stage is not possible, the code defaults to the original Spark code.
Delivering Results
This ultimately yields faster insights, expands the scope of data that can be processed, and lowers total cost of ownership (TCO). Bigstream can deliver 50-200 percent Amazon EMR speed gains and up to 10X for clusters on Amazon Elastic Compute Cloud (Amazon EC2).
Without a middleware layer like Bigstream, Spark analytics workloads can’t utilize Amazon EC2 F1 instances, which use FPGAs to enable custom hardware accelerations.
Customers see significant direct and indirect savings by adding Bigstream to EMR workloads. Bigstream also cuts customers’ EC2 and EMR spending and typically reduces Spark TCO by 30 percent or more.
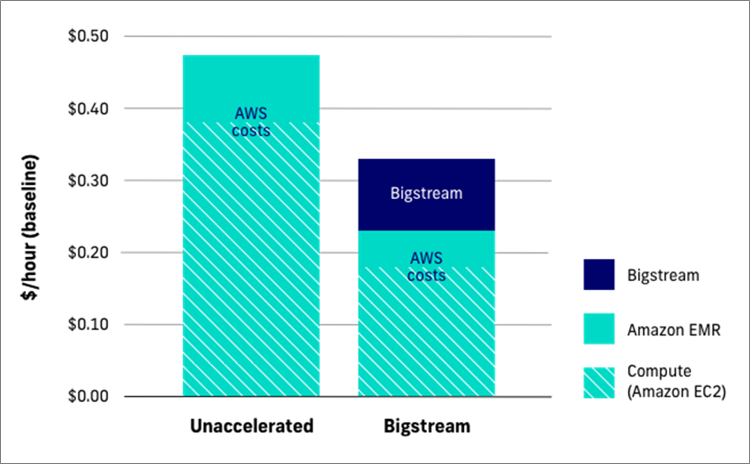
Figure 4 – TCO of Apache Spark deployments.
Use Cases Cross Industry Verticals
Bigstream acceleration supports use cases across a wide range of industries, from retailers analyzing customer growth segments to manufacturers minimizing downtime and banks preventing money laundering.
The software works by accelerating specific Spark operations, and some of the best performance gains come in core Spark workloads like data ingest.
These extract, transform, and load (ETL) processes typically support data lake and data warehouse pipelines, providing the foundation for downstream machine learning (ML) and analytics in Spark and other tools.
Along with Bigstream’s batch analytics acceleration, this covers a large portion of many organizations’ Spark deployments.
Conclusion
Big data platforms like Apache Spark offer the appeal of seemingly unlimited scale. Spark distributes data processing across multiple servers, and now that these server nodes can be provisioned in seconds in the cloud it’s tempting to imagine you can easily scale as your processing needs grow.
Bigstream offers a way of addressing growing Spark needs with software that optimizes existing CPU infrastructure. It can also seamlessly incorporate advanced programmable hardware. With the same number of servers, Bigstream can accelerate Spark clusters 3x with software alone and 10x when introducing FPGAs.
Data engineering and data science teams can take advantage of Bigstream’s 30-day free trial on Amazon EMR via AWS Marketplace. Bigstream is easy to deploy, and Bigstream architects are available to ensure your success.
The content and opinions in this blog are those of the third-party author and AWS is not responsible for the content or accuracy of this post.
.

.
Bigstream – AWS Partner Spotlight
Bigstream is an AWS ISV Partner and supplier of SaaS software for acceleration of big data applications.
Contact Bigstream | Partner Overview | AWS Marketplace
*Already worked with Bigstream? Rate the Partner
*To review an AWS Partner, you must be a customer that has worked with them directly on a project.