AWS Partner Network (APN) Blog
Building a Knowledge Graph for Scientific Research with MarkLogic and AWS
By Damon Feldman, Sr. Director, Solutions Engineering – MarkLogic
 |
The need to easily and efficiently access information to improve pharma R&D processes has never been greater.
However, patchwork IT infrastructure within organizations often results in data siloes with decades of research and clinical data. Without proper access and information management, it’s impossible for researchers to accelerate results and lower development costs.
Research clearly shows that organizations that prioritize data search and discovery are more productive and innovative. Data search and data discovery are related but not the same. Search is when you find information; discovery is when information finds you.
Deploying an intelligent search and discovery system, also known as an “insight engine,” goes beyond buying search application software. It requires organizations to change the way they integrate and curate data using semantic graphs (or knowledge graphs) to build rich search and discovery experiences.
MarkLogic Data Hub Service is a leading enterprise cloud data hub with built-in semantic search capabilities, allowing you to quickly build knowledge graph-based applications.
In this post, I will walk through a Consolidated Coronavirus Research Hub (CCRH) that’s built on Data Hub Service and designed specifically for researchers and data science experts.
The Research Hub provides a single place to search across more than 200,000 articles about COVID-19. The dataset is an integrated corpus accessed through MEDLINE that is focused on coronavirus-related research over the past 20 years.
The platform leverages MarkLogic’s advanced semantic search capabilities to provide researchers new insights and cross-connections within the data that would otherwise be missed. Best of all, it was built in just six weeks by MarkLogic, an AWS Partner with the Data & Analytics Competency.
Hosted on AWS
This project is built on MarkLogic’s Data Hub Service, a leading enterprise cloud data hub that runs on Amazon Web Services (AWS) for reliability and ease.
As a fully managed service, the Data Hub removes the friction of setting up the infrastructure; for example, it eliminates improperly provisioned disks, use of the wrong operating system versions, or problems with low-throughput network switches or a bad port on a storage area network (SAN).
Rather than focus on diagnosing or fixing thousands of infrastructure issues across hundreds of active customers, MarkLogic chose to build a reliable, repeatable solution where we know the stack and infrastructure are well provisioned, properly sized, and flexible.
That’s the essence of the Data Hub Service—an entire data integration and data management infrastructure that “just works” to solve business problems while hiding the complexity of DevOps and infrastructure management.
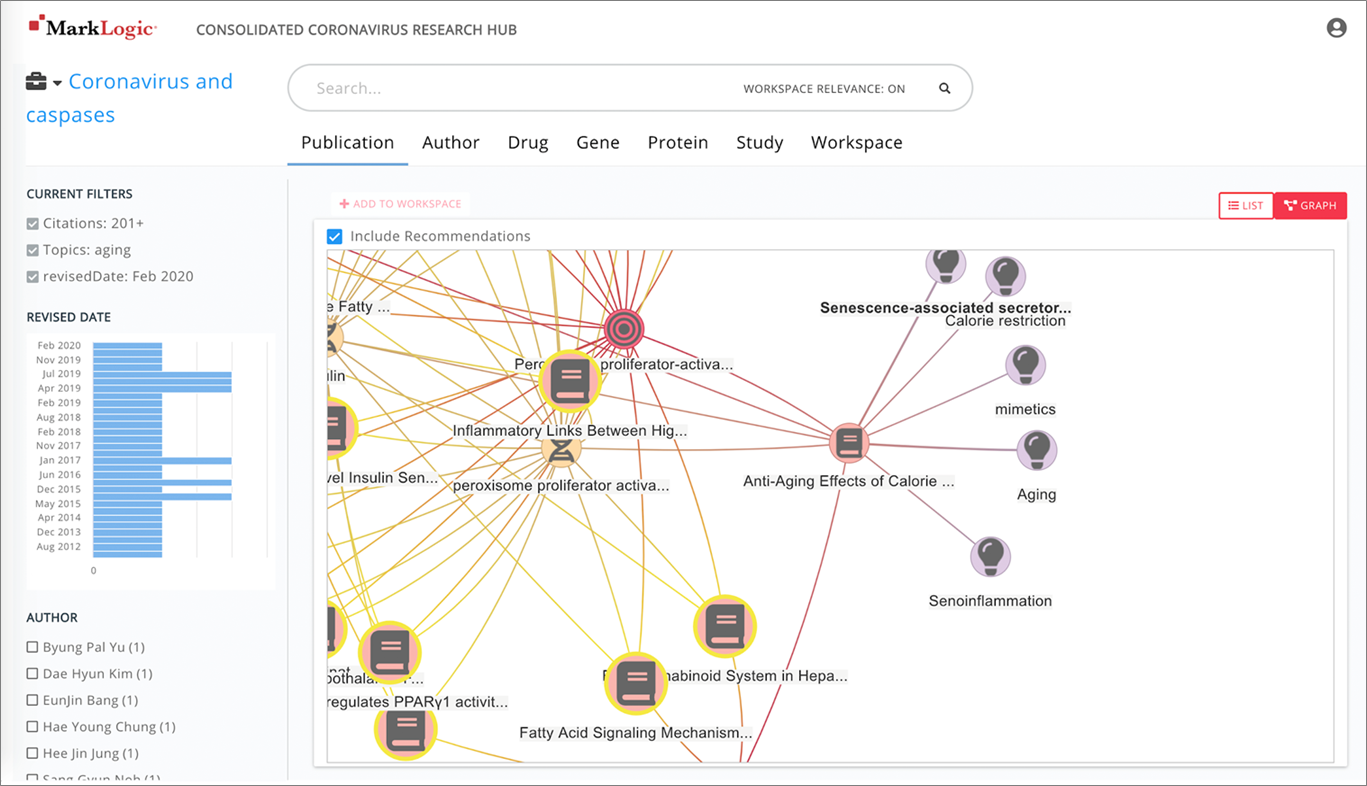
Figure 1 – Semantic graph view of entities extracted from publications.
How the Application Helps Researchers
The Consolidated Coronavirus Research Hub application enhances research productivity by consolidating and integrating multiple datasets into a single app, and shows users all data types linked into a knowledge graph.
There are two main ways to use the app:
First, you can use it like a search engine for publications and articles. In this mode, the search capabilities are robust and fast, which is useful, but similar to PubMed.
The graph views illustrate the overall context for search results by connecting articles with the genes, proteins, drugs, and studies mentioned in them. In addition, the current “workspace” selected will supply a relevance adjustment based on extracted semantic concepts.

Figure 2 – Search Results in the CCRH.
The second way to use the CCRH is to use it like a data access platform to look up genes, proteins, drugs, and clinical trials. The knowledge graph view illuminates relationships, and publications show how and why items are relevant to the search context.
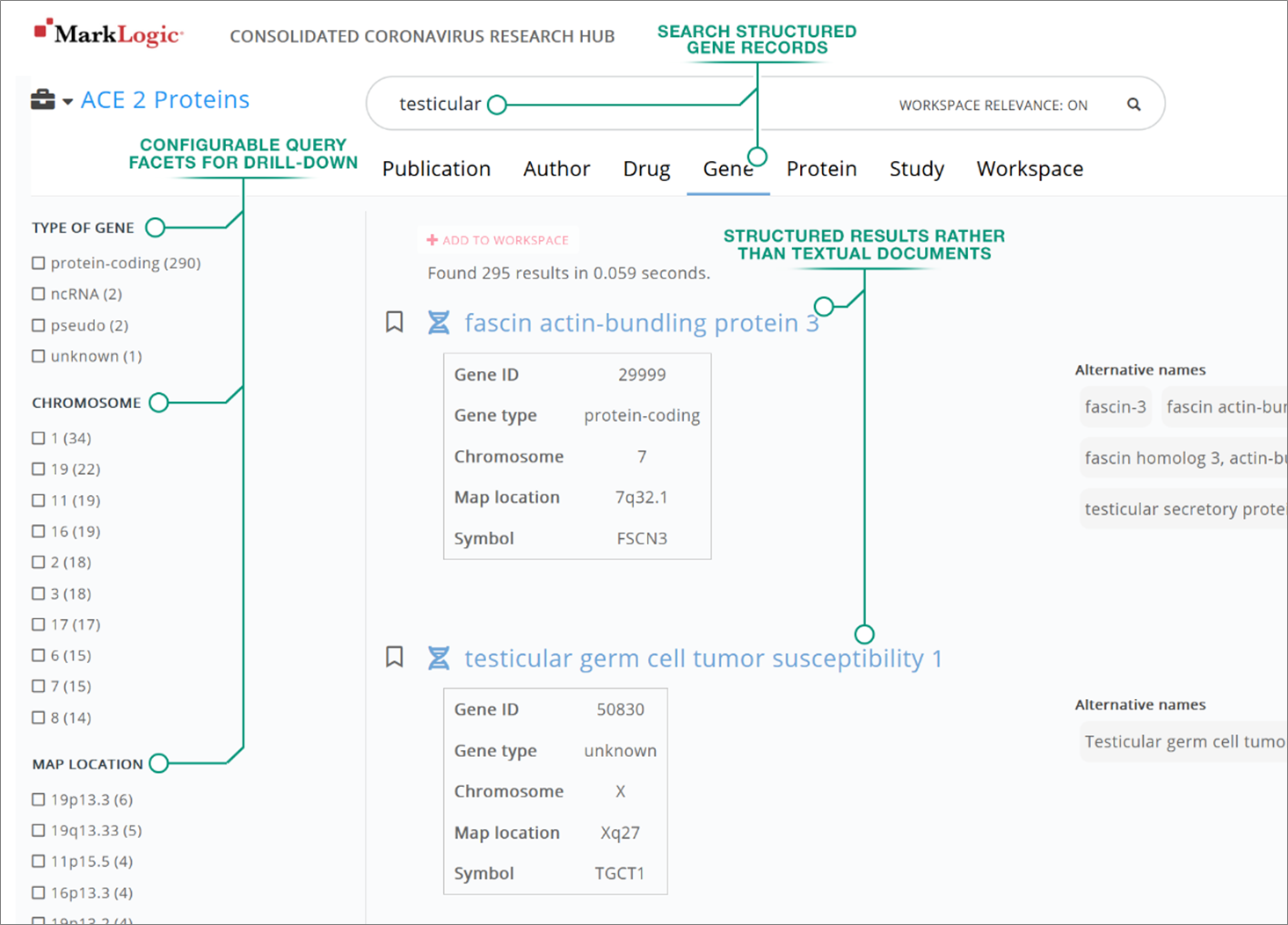
Figure 3 – Structured record search for genes.
Target Users
The app is designed primarily for researchers at pharmaceutical and life sciences organizations. Given the subject matter, however, it has broad applicability and we expect other researchers and clinicians to find value in it as well.
The main reason MarkLogic built the app is to provide more sophisticated search capabilities than you get by just going to PubMed or MEDLINE.
For example, the CCRH has the ability to view the data as a knowledge graph, look at semantic linkages that highlight hidden connections, and see which topics are emerging. It also includes structured datasets beyond the PubMed/MEDLINE (see the full list below).
Here are a few example searches to show what you can do:
- Find and gather relevant information about the mechanisms of potential treatment.
- Gather and share relevant publications to a topic of interest with a colleague, or the broader community
You can also take a look at a short demo of some of the capabilities of this research hub.
How it Works
We start with our fully managed Data Hub Service, which is a data integration and data management platform with a distributed shared-nothing architecture that scales elastically without having to worry about complex data sharding.
It uses a single-tenant, active-active, high availability deployment architecture with synchronous data replication and automated failover. It also independently auto scales operational, analytical, and data integration workloads, and provides storage for high performance and reliability.
The diagram below illustrates the internal architecture of Data Hub Service. Internally, there are four groups for four functions, which allows instances to scale appropriately and isolates different workloads, such as data ingestion, analytic workload, and interactive (API) workload.
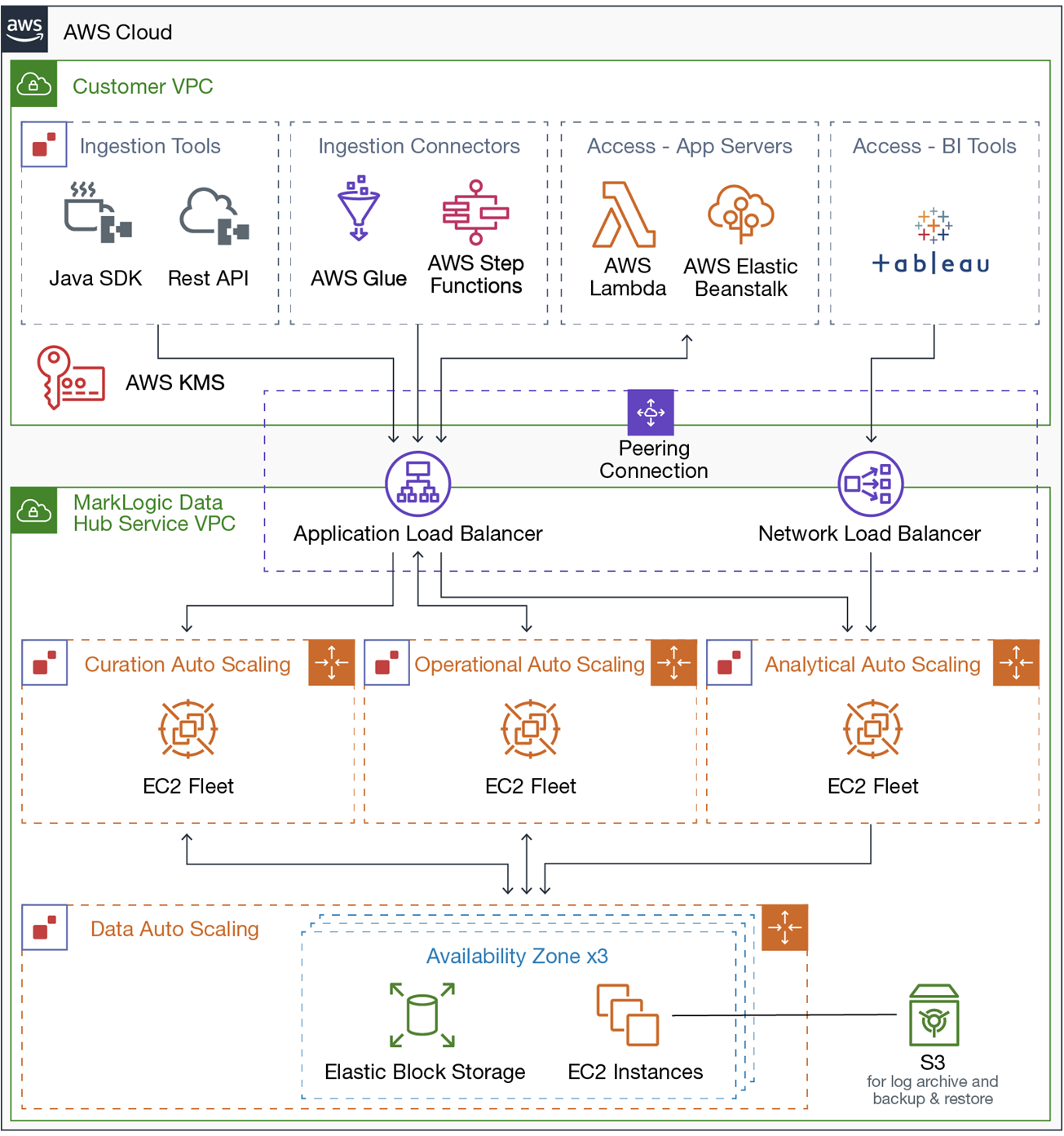
Figure 4 – MarkLogic Data Hub Service is an elastic, fully-hosted AWS solution.
We set up an Amazon Elastic Compute Cloud (Amazon EC2) instance as a combined data loader/bastion host, an LDAP service to delegate authentication and authorization, and a middle-tier node.js virtual machine in our own network for the web application.
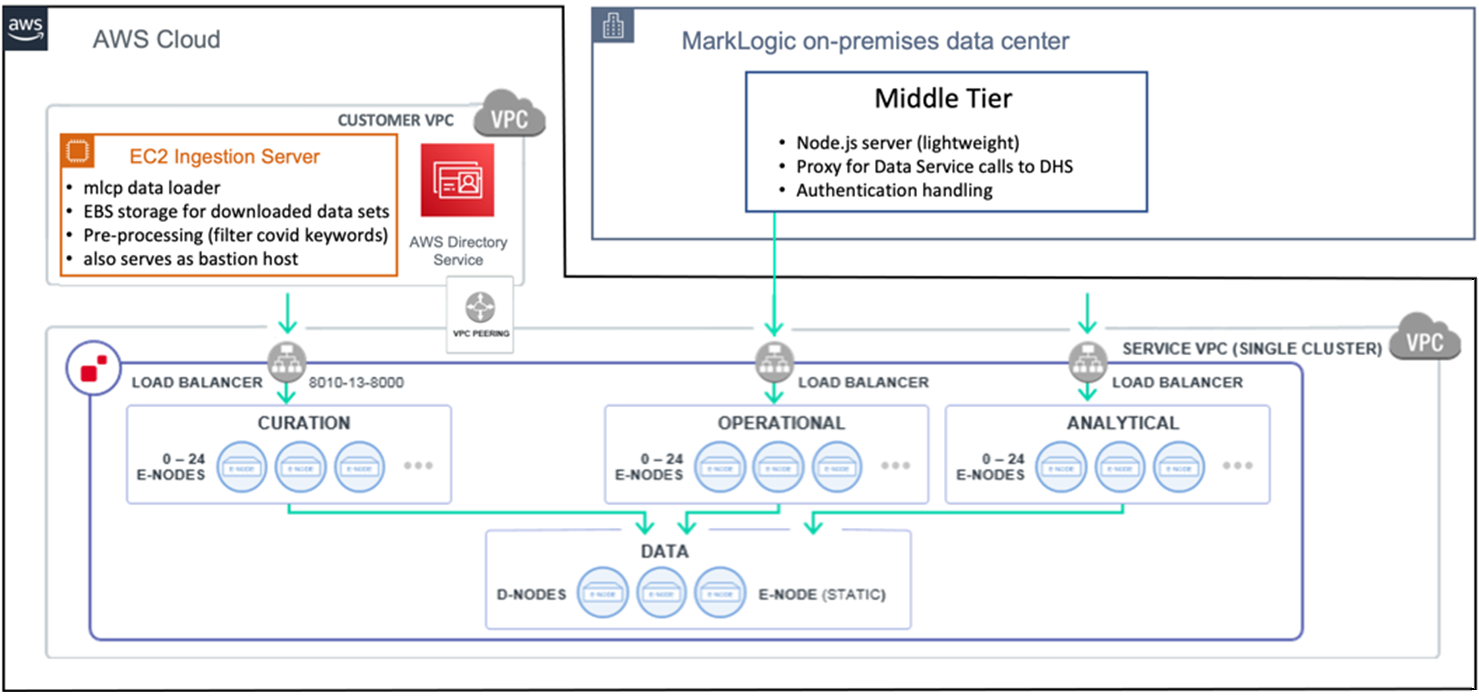
Figure 5 – Additional servers and services connect to Data Hub Service APIs via REST.
Ingestion Server
Ingestion server is an Amazon EC2 instance where we download the raw data files that are inputs to the Consolidated Coronavirus Research Hub.
To load raw data files into Data Hub Service, we use a bulk data loading java utility, MarkLogic Content Pump (MLCP). It loads various data formats into the Hub, including XML versions of articles, CSV gene listings, Turtle files (or RDF), zip files with drug label information, and drug label images.
Additionally, MarkLogic also uses a simple, keyword-based grep bash file to preprocess and eliminate less-relevant articles. Finally, the Gradle utility is used to drive the various data set loads and processing steps to load, map, and master the incoming data by running Data Hub “flows” which process the data.
Middle Tier
To more easily map to the “marklogic.com” domain and meet MarkLogic policies, we host this application on-premises. It connects to the Data Hub Service instance using REST calls, invoking data APIs.
Data Hub Service Instance
The hard work is done here. A sequence of steps is applied to the data that includes:
- Ingesting raw data, and tracking provenance about it. The Data Hub typically keeps raw data for traceability and reprocessing.
- Mapping data to a canonical form. Data mapping GUIs and JavaScript plugins define the mappings.
- Mastering data. The publication authors have variations in names and affiliations that make it useful to do fuzzy matching based on attribute weights for the authors.
- Data lenses are canonical data is mapped to SQL and RDF views.
- Transforms (XSLT and JavaScript) transform the canonical, internal data formats to useful REST response payloads for consumption by the middle tier.
Unique Features of the App
The CCRH app shows off a lot of the unique capabilities of MarkLogic Data Hub Service, which is what the app runs on. Some of the features are visible in the app, but many are used behind the scenes to integrate and clean up the data.
Here’s a short list of notable features:
- Text search
- Graph search
- Transactions
- Facets and range indexes
- Fast data ingestion
- Smart Mastering
MarkLogic is happy to provide more detail on how we built the app if you’re interested in building something similar, or if you’re simply curious and want to understand how it all works.
Data Included in the App
The app includes integrated data from many different data sources, including:
- PubMed Open Access articles (from MEDLINE) including keywords: covid, nCoV, coronavirus, SARS (case sensitive), MERS (case sensitive), furin, ‘vitamin c’, tocilizumab, actemra, remdesivir, GS.5734, RoActemra, IL6R, IL-6.
- Author and affiliation information are extracted from those articles.
- ncbi/gene data for Homo Sapiens.
- Swiss Prot proteins as exposed by the UniProt project.
- ClinicalTrials.gov trial data.
- US FDA Structured Product Label data.
MarkLogic is working to continue adding new data sources as they become available and as new studies are published, including adding preprint articles.
Getting Started
With the unprecedented challenges posed by the coronavirus pandemic, people are turning to science and technology to better understand and track the virus.
As a company, MarkLogic is humbled to be able to use our technology in this effort, which includes supporting our customers’ use of MarkLogic and developing our own apps like the Consolidated Coronavirus Research Hub (CCRH).
The app is free to use; just visit cov.marklogic.com to get started.
For a private account, or with any questions and comments, please send an email to covresearchhub@marklogic.com.
MarkLogic Data Hub Service is available on AWS Marketplace, and you can learn more about a Data Hub built for pharmaceutical applications.
The content and opinions in this blog are those of the third-party author and AWS is not responsible for the content or accuracy of this post.
.

.
MarkLogic – AWS Partner Spotlight
MarkLogic is an AWS Competency Partner whose Data Hub Service is a leading enterprise cloud data hub with built-in semantic search capabilities, allowing you to quickly build knowledge graph-based applications.
Contact MarkLogic | Partner Overview | AWS Marketplace
*Already worked with MarkLogic? Rate the Partner
*To review an AWS Partner, you must be a customer that has worked with them directly on a project.